1. 概述
本文将介绍如何为树结构设计一个哈希函数。
我们先定义问题:如何判断两个树结构是否相同。随后通过一个示例进行说明。接着,提出一种通用的解决方案,并给出一个变种思路,适用于子节点顺序无关的场景。
2. 问题定义
我们有一个由 N 个节点和 N - 1 条边构成的树结构。目标是为其生成一个能代表该结构的哈希值,从而实现任意两个树结构的常数时间比较。
树的定义回顾:
树是一种无环连通图,由 N 个节点和 N - 1 条边组成,不存在自环边,也不存在重复连接同一对节点的边。
举个例子:
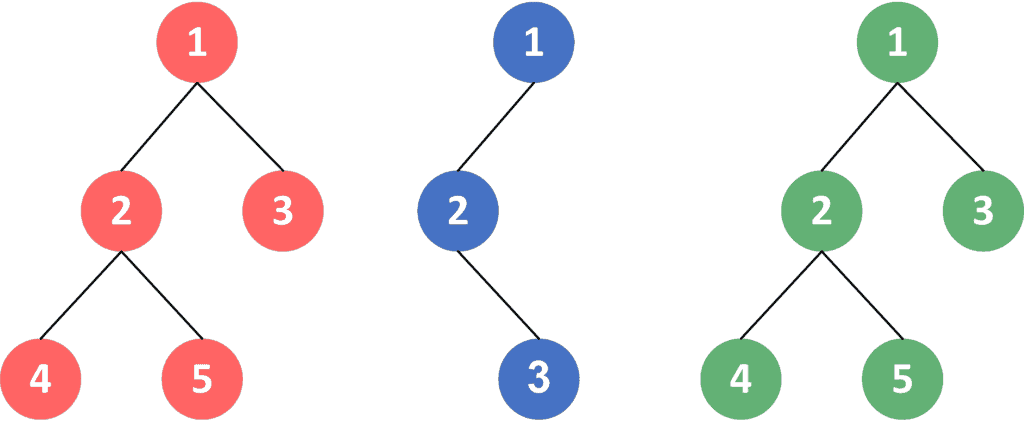
上图展示了三种不同的树结构(红、蓝、绿)。如果我们分别为它们计算哈希值,可能会得到如下结果:
- 红色树:5462
- 蓝色树:4921
- 绿色树:5462
可以看到,红树和绿树哈希值相同,因为它们结构完全一致;而蓝树哈希不同,因为其结构不同。
3. 哈希树方法(Hash Tree)
核心思想:
每个节点的哈希值依赖于其子节点的哈希值。根节点的哈希值即为整棵树的哈希。
我们采用深度优先遍历(DFS)进行递归处理:
- 当前节点为叶子节点时,返回哈希值 0。
- 否则,对子节点进行递归哈希,然后使用一个哈希公式将子节点哈希值组合成当前节点的哈希。
我们使用如下公式计算子节点哈希序列的哈希值:
$$ \sum_{i=0}^{N-1} S[i] \times SEED^i \mod MOD $$
其中:
S[i]是第 i 个子节点的哈希值SEED和MOD是预定义常量,用于控制哈希分布
最终,根节点的哈希值即为整棵树的哈希值。
3.1 算法实现
algorithm Hash(node)
// INPUT
// node = the current node in the tree
// SEED, MOD = the hashing parameters
// OUTPUT
// the hash value of the subtree rooted at node
nodeHash <- 0
for i <- 0 to length(node.children) - 1: // 0-based indexing
child <- node.children[i]
childHash <- Hash(child)
nodeHash <- nodeHash + (childHash * SEED^i mod MOD)
return nodeHash
3.2 时间复杂度分析
✅ 时间复杂度: O(N)
因为每个节点和边都只被访问一次,等价于标准 DFS 的复杂度。
4. 变种问题:子节点顺序无关的哈希
如果我们希望两个结构相同但子节点顺序不同的树具有相同的哈希值,例如:
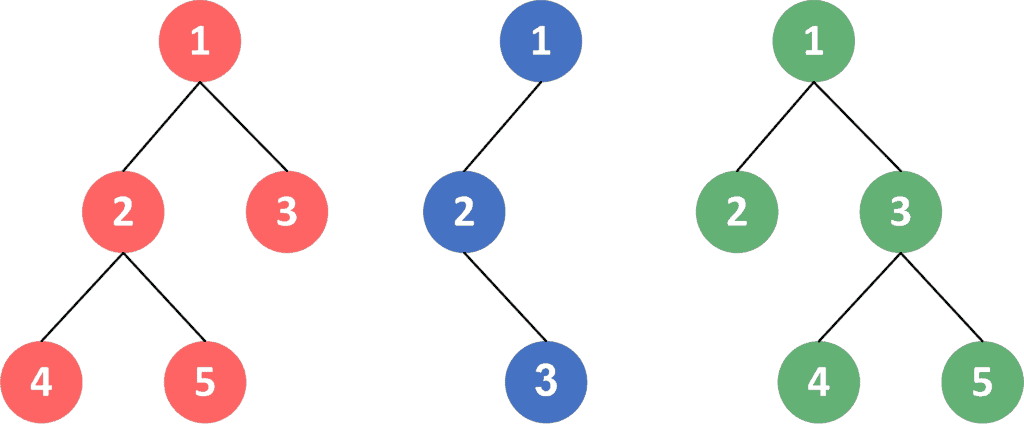
如图所示,红树和绿树结构相同,只是节点 2 和 3 的顺序不同。这种情况下,我们希望它们的哈希值一致。
解决思路
在递归过程中:
- 递归获取子节点哈希值
- 将子节点哈希值排序
- 使用排序后的哈希值组合当前节点的哈希
这样可以忽略子节点顺序带来的差异。
4.1 算法实现
algorithm Hash(node)
// INPUT
// node = the current node in the tree
// SEED, MOD = the hashing parameters
// OUTPUT
// the hash value of the subtree rooted at node
children_hash <- empty list
for child in node.children:
children_hash.add(Hash(child))
sort(children_hash)
nodeHash <- 0
for i <- 0 to children_hash.size - 1: // 0-based indexing
nodeHash <- nodeHash + children_hash[i] * (SEED^i) mod MOD
return nodeHash
4.2 时间复杂度分析
✅ 时间复杂度: O(N × logN)
因为每个节点的子节点都需要排序,排序复杂度为 O(k × logk),其中 k 是当前节点的子节点数。由于所有节点总子节点数不超过 N,总复杂度为 O(N × logN)。
5. 总结
本文介绍了两种树结构哈希算法:
| 方法 | 子节点顺序敏感 | 时间复杂度 | 适用场景 |
|---|---|---|---|
| 标准哈希树 | ✅ 是 | O(N) | 子节点顺序影响结构 |
| 排序哈希树 | ❌ 否 | O(N × logN) | 子节点顺序不影响结构 |
这两种方法都基于递归 DFS 和子节点哈希组合的思想,适用于树结构比较、缓存、版本控制等场景。
通过选择合适的哈希公式和参数(SEED、MOD),可以有效减少哈希冲突,提高哈希函数的稳定性。