1. Overview
When it comes to web performance, Hypertext Transfer Protocol caching (HTTP Caching) is vital for faster load times.
In this tutorial, we’ll explore its basics, types, and key considerations, offering insights for developers aiming to optimize online experiences.
2. HTTP Caching and Benefits
Slow websites often lead to user frustration, and caching is one effective solution to this problem. Implemented either on the server side, using tools like Redis or Memcached, or on the client side, this process involves checking the cache first when a resource request is made:
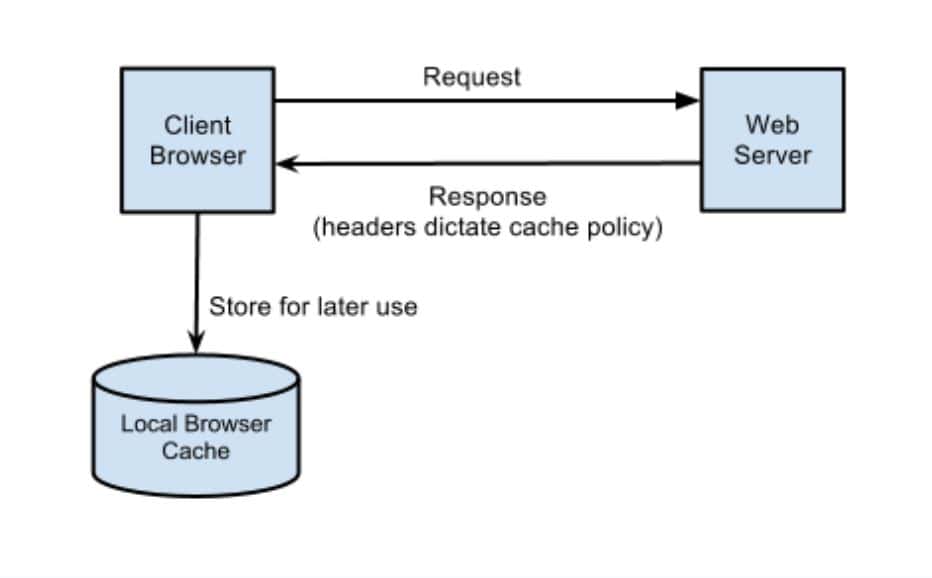
If the cache lacks the resource, the system fetches and caches it from the server, serving it directly from the cache for future requests. This method speeds up response times and reduces server bandwidth and workload.
Now, let’s discover some benefits of HTTP Caching.
First, the most noticeable increase is in response times. By avoiding unnecessary server calls, cached resources are delivered much faster. This speed boost enhances user experience, a crucial factor in today’s fast-paced digital world.
Secondly, another key benefit is the reduction in server bandwidth usage. Since the cache handles repeated requests, there’s less strain on the server’s resources, translating to cost savings and increased efficiency.
Furthermore, caching significantly reduces the load on the server. By handling requests locally (either in the browser or a proxy), we minimize the number of queries hitting the server, thereby increasing its lifespan and reducing maintenance costs.
3. Understanding Different Storage Locations
Caching can be implemented in various locations, each serving a unique purpose in the caching ecosystem. The effectiveness of caching depends significantly on where it’s placed. In this section, we’ll explore the primary caching locations and their unique roles in enhancing web performance.
3.1. Browser Cache
One of the primary caching locations is the browser cache. This cache is unique to each user, storing responses according to individual HTTP Headers.
The advantage here is that repeat visits to a website become much quicker because the browser has already stored much of the needed data.
3.2. Proxy Cache
Another crucial caching location is the proxy cache, typically managed by Internet Service Providers (ISPs) or organizational IT departments. This cache caters to a broader audience and plays a key role in reducing external bandwidth usage.
Proxy caches alleviate the load on the primary server by caching frequently requested content, speeding up the end user’s response times.
3.3. Reverse Proxy Cache
Lastly, the reverse proxy cache is an important aspect of the caching ecosystem. Positioned closer to the server and generally managed by server administrators, it is an intermediary.
It handles requests before they reach the server, which is especially beneficial in scenarios with high traffic. This setup improves response times and helps balance and distribute server load more efficiently.
4. Key Concepts and Techniques of Web Caching
Understanding the underlying concepts and techniques of web caching is essential for effectively using it. This section delves into the critical aspects of web caching, including caching headers and validators, which are pivotal in how content is cached and its freshness maintained.
4.1. Caching Headers
Let’s explore caching by understanding HTTP headers and the linchpins in how content is cached.
When servers respond to requests, they include specific headers that guide the storage and management of content in the cache. The most crucial of these are:
- Expires
- Pragma
- Cache-Control
While Expires and Pragma hail from the pre-HTTP 1.1 era, Cache-Control offers a versatile and potent approach, adaptable to a variety of caching scenarios and needs. This makes Cache-Control the current standard.
These headers accept different parameters, called directives:
- private
- public
- no-store
- no-cache
- max-age
- s-max-age
- must-revalidate
Each of them and their combination, serves distinct purposes in managing how content is cached and accessed.
4.2. Validators
The validation process checks if the cached content is still current, preventing the use of outdated information.
Validators play a pivotal role in the caching process, ensuring the content remains relevant and fresh. These include headers like E-Tags and Last-Modified. These allow clients to make conditional requests to the server.
When both E-Tag and Last-Modified headers are present, a client uses them together for content validation. The absence of these headers means the client depends on Cache-Control or Expires headers for caching decisions. If not properly set, this can lead to either avoiding caching or using stale content.
Last-Modified indicates the resource’s last update time, helping clients determine if they need to fetch a newer version.
On the other hand, E-tags or Entity Tags are unique identifiers assigned to specific versions of resources. They are crucial in validating cached content. They allow clients to ask the server whether their cached version of a resource is the latest.
If the server’s response to this header is a 304 status code, it indicates that the cached version is still valid, eliminating the need for a fresh download. However, if the server provides a new version of the resource, it indicates that the cached version is outdated. This mechanism ensures that users always access the most up-to-date content without unnecessary server requests.
We can distinguish between two kinds of E-Tags; Strong and Weak.
Strong E-Tags, are precise indicators of a resource’s content, signifying exact matches. For example, a strong E-Tag could be 686897696a7c876b7e. They ensure that the content cached by the client is the same as the server’s current version.
Weak E-Tags, prefixed with “W/”, these tags suggest functional equivalence rather than byte-for-byte identity. They’re useful when minor changes to a resource don’t require a cache update. An example is W/686897696a7c876b7e.
Choosing between strong and weak E-Tags depends on the content’s nature and caching needs.
5. Strategies
Let’s examine some important considerations for an effective caching strategy based on our application’s specific needs. We must remember that there is no universal approach to caching; it varies depending on what our application does.
For static content such as HTML, CSS, and JavaScript files, we might find aggressive caching for extended periods, like a year, to be highly beneficial. This strategy reduces the number of requests to the server, an ideal approach since these files don’t change frequently.
On the other hand, dynamic content, including user profiles or real-time data, calls for a more nuanced caching approach. Here, we might need shorter caching times or even real-time validation to guarantee the content’s freshness.
6. Debugging
When it comes to refining our caching strategy, debugging and analyzing HTTP headers are crucial steps. Tools such as curl or browser developer tools are indispensable in this aspect. They empower us to scrutinize the sent and received headers, providing insights into how our caching strategy is being implemented.
For example, we can inspect the HTTP headers in a request from a Linux terminal with:
curl -I [URL]
By examining headers, we can pinpoint potential issues, such as too-short cache times or incorrectly configured headers, that could be impeding our website’s performance. This hands-on approach ensures our caching strategy is theoretically sound and effectively executed in practice.
7. Conclusion
In this tutorial, we discussed the intricacies of HTTP caching, involving the strategic use of cache headers, conditional requests, and robust cache invalidation procedures. These elements collectively contribute to faster load times, reduced server load, and an optimized user experience in the dynamic landscape of web performance.