1. 引言
在机器学习中,不同的算法会基于数据中潜在的模式做出一定的假设。这些假设可能是隐式的,也可能是显式的。从数学角度看,每种算法能学习的模型都属于一个特定的函数族,这个函数族被称为假设空间(Hypothesis Space)。
本文将解析假设空间的定义、表达能力、以及如何选择合适的假设空间,帮助你在实际建模中做出更明智的选择。
2. 什么是假设空间?
以一个二维的二分类任务为例,我们的目标是构建一个模型,将样本划分为正类和负类。
使用逻辑回归(Logistic Regression)时,模型的形式如下:
(1)
$$
p_{\theta_0, \theta_1, \theta_2}(x_1, x_2) = \frac{1}{1 + e^{-(\theta_0 + \theta_1 x_1 + \theta_2 x_2)}}
$$
该模型用于估计样本为正类的概率。
- 每一个这样的模型就是一个假设(Hypothesis)
- 所有这些假设的集合,构成了该算法的假设空间
例如,$ p_{0,1,2} = \frac{1}{1+e^{-x_1 - 2x_2}} $ 是一个具体的假设,而 $ \left{p_{\theta_0, \theta_1, \theta_2} \mid \theta_0, \theta_1, \theta_2 \in \mathbb{R} \right} $ 就是该算法的假设空间。
2.1 假设与假设背后的模型
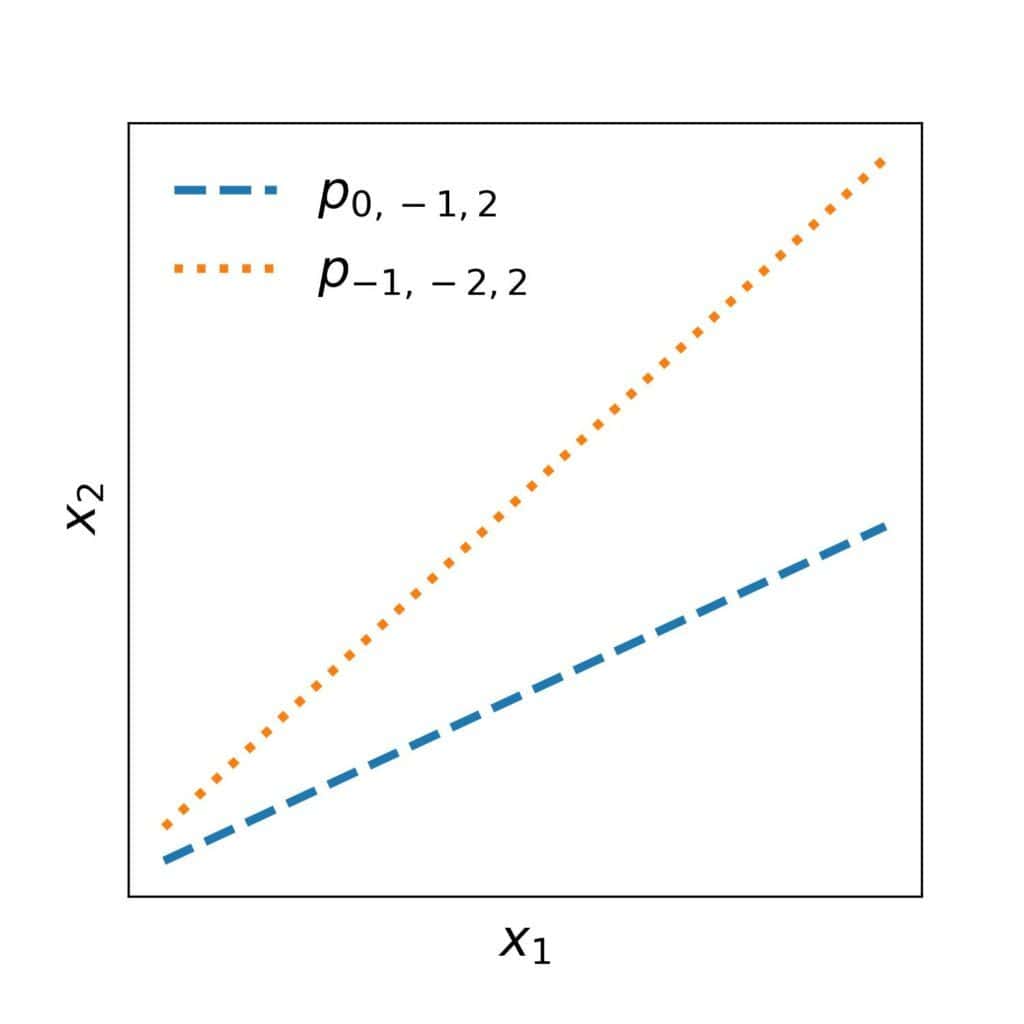
以逻辑回归为例,其假设空间中的每个模型都隐含一个前提:正负样本之间的边界是一条直线(线性边界)。
如下图所示,两个不同的假设对应了两条不同的直线:
2.2 回归任务中的假设空间
同样适用于回归任务。例如,线性回归(Linear Regression)假设输出是一个线性组合:
(2)
$$
\widehat{y}(x_1, x_2, \ldots, x_n) = \theta_0 + \sum_{j=1}^{n}\theta_j x_j
$$
这个表达式就是该算法的假设空间中的一个假设,而整个空间由所有可能的 $\theta_0, \theta_1, \ldots, \theta_n$ 组合构成。
3. 假设空间的表达能力(Expressivity)
可以粗略地说,一个假设空间越复杂,其表达能力越强,能拟合的数据模式也越多样。
但表达能力过强也有代价:
- ✅ 更容易捕捉数据中的复杂模式
- ❌ 也更容易过拟合(Overfitting)
- ❌ 模型可能变得难以解释和计算
3.1 表达能力与欠拟合
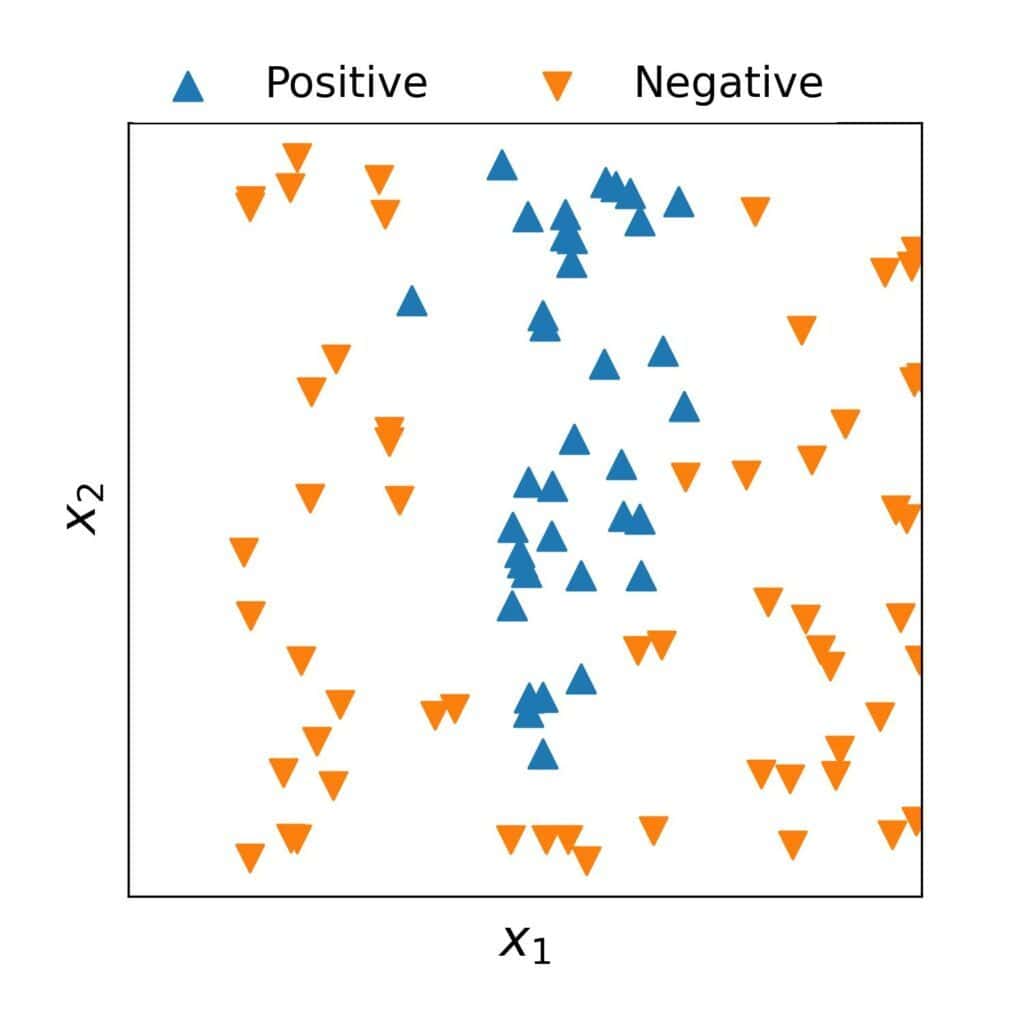
如果假设空间的表达能力太弱,无法捕捉数据中的真实模式,就会出现欠拟合(Underfitting)。
例如,使用线性模型去拟合一个非线性边界的数据,效果会很差:
3.2 表达能力与过拟合
假设我们使用一个更复杂的模型,比如多项式阶数很高的模型:
(3)
$$
p_{\Theta}(x_1, x_2) = \theta_0 + \sum_{k=1}^{10}\theta_{1,k}x_1^k + \sum_{k=1}^{10}\theta_{2, k}x_2^k
$$
这种模型的决策边界可能如下图所示:
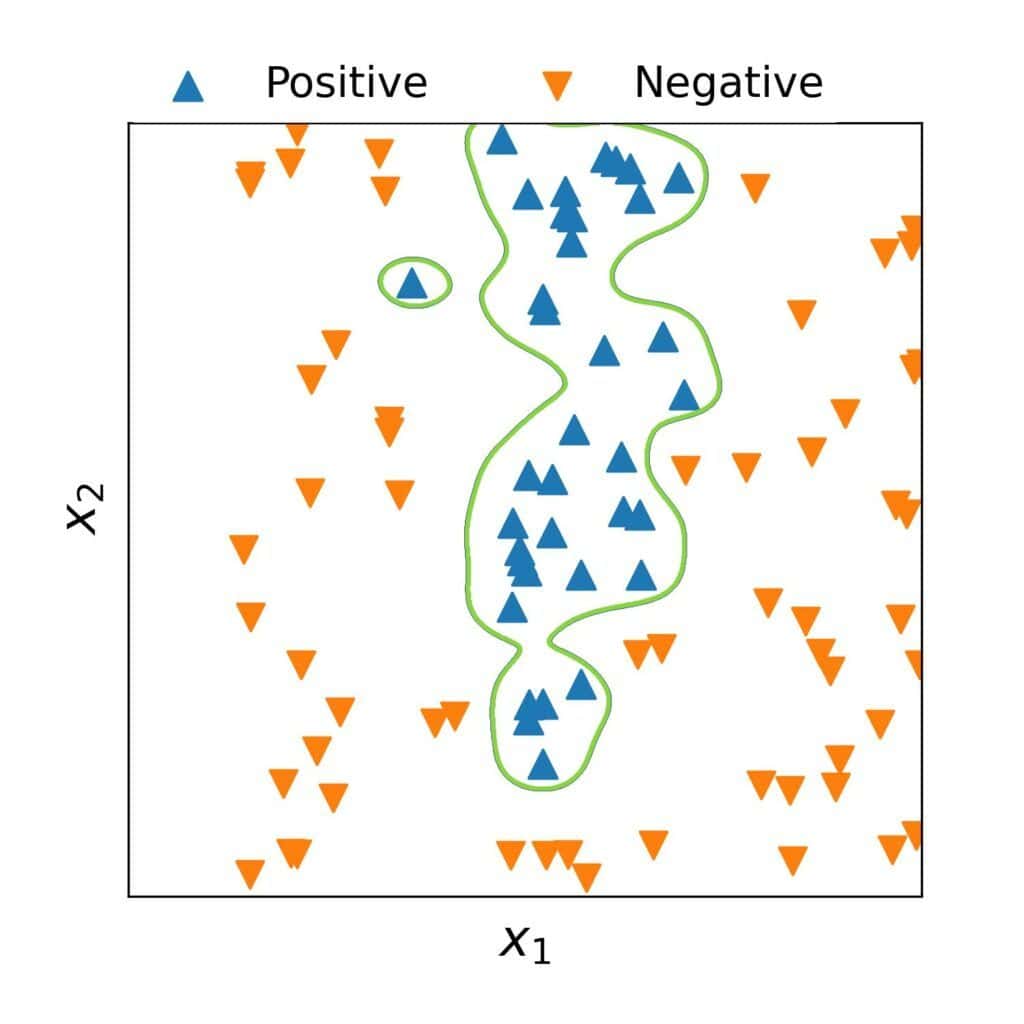
模型开始拟合噪声,导致泛化能力下降。
3.3 表达能力 vs 可解释性
有时候,即使模型表现不错,也可能因为太复杂而无法使用。例如:
- ✅ 简单模型:如 $ y = x^2 + x + 1 $,结构清晰,易于解释
- ❌ 复杂模型:如 $ y = \sqrt{x}e^{-x} -101 x^2 + 20x - \frac{11}{x} $,变量间的关系难以直观理解
所以,选择模型时,不仅要考虑性能,还要兼顾可解释性和计算成本。
4. 如何选择合适的假设空间?
选择合适的假设空间是一个平衡的艺术,关键在于:
✅ 模型足够表达数据中的模式
❌ 又不至于复杂到过拟合或难以解释
实践建议:
先探索数据
- 使用可视化工具观察数据分布
- 判断是否适合线性模型、多项式模型、树模型等
从简单模型开始尝试
- 比如先尝试线性分类器或回归模型
- 如果效果不好,逐步增加模型复杂度
逐步迭代
- 例如从线性模型 → 二次模型 → 三次模型
- 每次提升复杂度时,评估模型表现和泛化能力
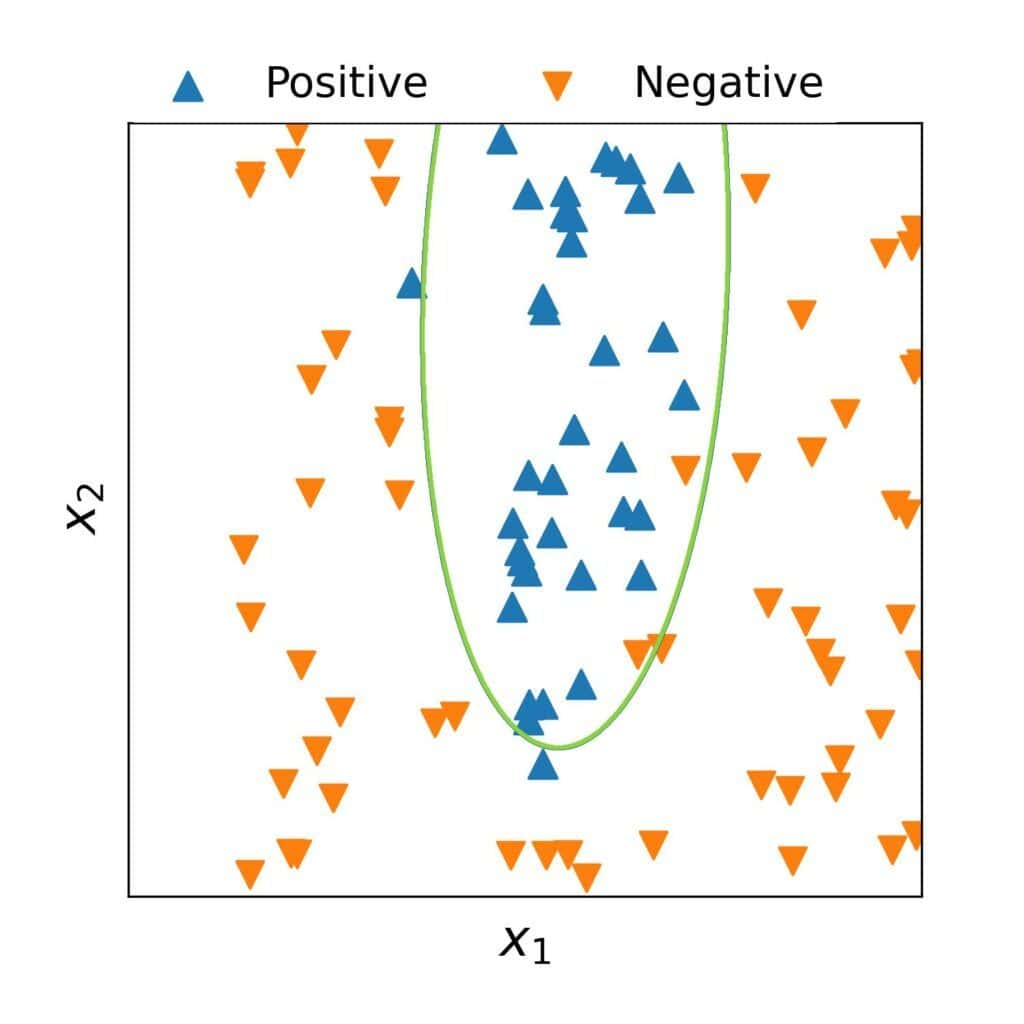
例如,一个二次分类模型的假设空间如下:
(6)
$$
\begin{aligned}
r(x_1, x_2) &= \theta_0 + \theta_1 x_1 + \theta_2 x_2 + \theta_{11} x_1^2 + \theta_{12} x_1 x_2 + \theta_{22} x_2^2 \
p_{\Theta}(x_1, x_2) &= \frac{1}{1+e^{-r(x_1, x_2)}} \qquad \Theta = {\theta_0, \theta_1, \theta_2, \theta_{11}, \theta_{12}, \theta_{22} }
\end{aligned}
$$
其决策边界如下图所示,虽然有少量误分类,但整体拟合效果不错:
如果效果仍不理想,可以尝试更高阶的模型,直到找到一个性能和复杂度之间的最佳平衡点。
5. 总结
- 假设空间是算法能学习的所有模型的集合
- 表达能力太强 → 易过拟合,解释性差
- 表达能力太弱 → 易欠拟合,模型性能差
- ✅ 正确做法:从简单模型开始,逐步增加复杂度,直到找到合适模型
⚠️ 踩坑提醒:不要一开始就用最复杂的模型!先理解数据,再选择合适的假设空间,是建模成功的关键之一。