1. 简介
在本文中,我们将深入解析目前最流行的目标检测算法之一 —— YOLO(You Only Look Once)。顾名思义,YOLO 是一种实时目标检测算法,其处理图像的速度非常快,适合用于对实时性要求较高的场景。
我们将从目标检测的基本概念讲起,逐步深入 YOLO 的核心机制,包括其工作原理、关键算法优化(如非极大值抑制 NMS)以及后续版本的改进,并介绍其在实际中的应用。
2. 目标检测概述
目标检测的任务是在图像或视频中识别出特定类别的物体实例。它不仅需要判断图像中是否存在物体,还要通过边界框(bounding box)标出其位置,并给出物体的类别标签。
目标检测本质上是两个任务的结合:
- 图像分类:判断图像中包含的是什么物体(如猫、狗)
- 目标定位:确定物体在图像中的具体位置(通常用边界框表示)
例如,目标检测算法接收一张图像作为输入,输出一个或多个带有类别标签的边界框。

2.1 常见目标检测方法
目标检测方法可以分为两大类:
- 非神经网络方法:
- Viola-Jones(基于 Haar 特征)
- SIFT(尺度不变特征变换)
- HOG(方向梯度直方图)
- 模板、形状或颜色匹配方法
这些方法依赖人工提取特征,再使用如 SVM 等分类器进行识别,准确率有限。
- 基于神经网络的方法:
- R-CNN 系列(Fast R-CNN、Faster R-CNN)
- SSD(Single Shot Detector)
- RetinaNet
- YOLO(You Only Look Once)
神经网络方法无需手动提取特征,具有更高的准确率,但训练成本较高,需要大量标注数据。
2.2 目标检测的挑战
- 边界框为矩形,无法准确描述具有曲线形状的物体。
- 非神经网络方法容易产生误检。
- 神经网络方法虽准确但训练成本高,依赖大量标注数据。
YOLO 正是为了解决这些挑战而设计。借助迁移学习(Transfer Learning),我们可以使用预训练模型或对模型进行微调,从而快速部署目标检测任务。YOLO 之所以流行,是因为它在保持较高准确率的同时,还能实现实时处理。
3. YOLO(You Only Look Once)
YOLO 是目前最主流的目标检测算法之一,其核心思想是将目标检测任务转化为一个回归问题,从而实现一次前向传播即可完成检测。
YOLO 输出每个检测目标的类别和边界框,边界框由以下四个参数定义:
- 中心坐标 (bx, by)
- 宽度 bw
- 高度 bh
此外,YOLO 还输出类别预测 c 和预测概率 Pc。
3.1 YOLO 的工作原理
假设我们有一张包含猫和狗的图像。YOLO 的处理流程如下:
- 将图像划分为一个 S×S 的网格(如 3×3)。
- 每个网格负责检测一个物体。
- 对每个网格单元,输出一个向量,包含边界框信息和类别预测。
例如,第一个网格单元中没有物体,其向量表示为:
$$ C_{1, 1} = (P_c, B_x, B_y, B_w, B_h, C_1, C_2) = (0, ?, ?, ?, ?, ?, ?) $$
其中:
- $P_c$:是否包含物体的概率
- $B_x, B_y$:边界框中心坐标(相对于网格单元)
- $B_w, B_h$:边界框尺寸(相对于整张图像)
- $C_1, C_2$:类别标签(如猫或狗)
如果某个网格单元中包含一个猫的边界框中心,则其向量可能为:
$$ C_{3, 2} = (1, 0.05, 0.04, 0.35, 0.4, 1, 0) $$
整个图像被编码为一个 S×S×(B×5 + C) 的张量,其中:
- B:每个网格单元预测的边界框数量
- C:类别数量
通过 CNN 网络,YOLO 可以在一次前向传播中完成所有目标的检测。
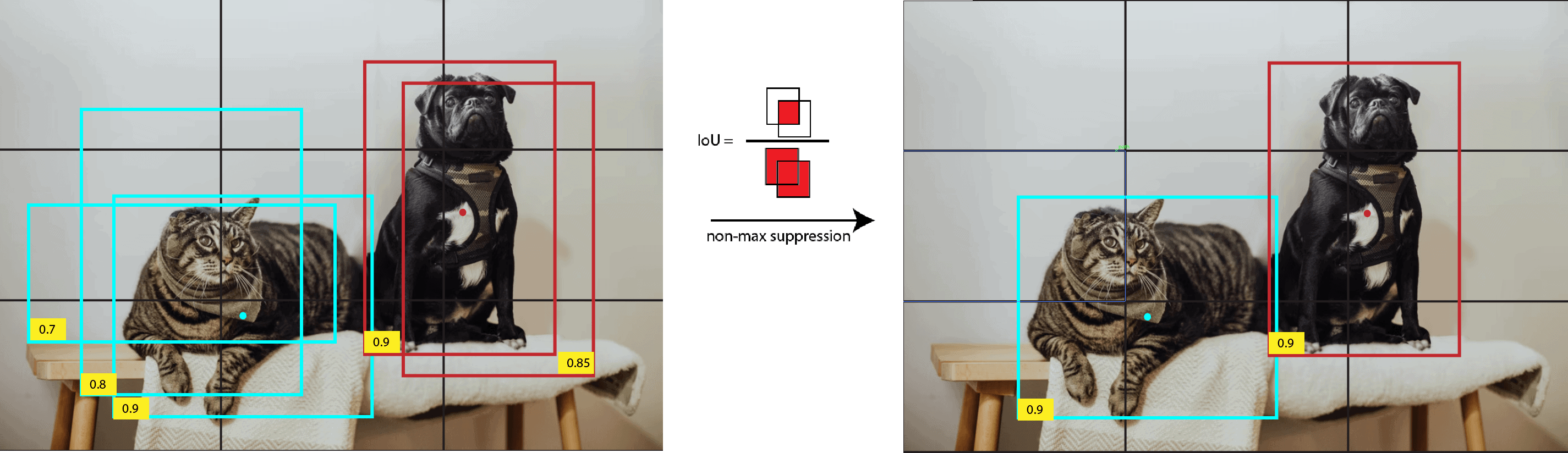
3.2 非极大值抑制(Non-Max Suppression)
YOLO 有时会为一个目标生成多个边界框,这时就需要使用 NMS 来保留最优的边界框。
步骤如下:
- 选择置信度最高的边界框。
- 计算该框与其余框的 IoU(交并比)。
- 若 IoU 超过设定阈值(如 0.5),则删除置信度较低的框。
- 重复上述步骤,直到所有框都被处理。
IoU 的计算公式为:
$$ IoU = \frac{\text{area of intersection between } B_1 \text{ and } B_2}{\text{area of union between } B_1 \text{ and } B_2} $$
3.3 向量泛化
YOLO 不仅限于每个网格单元预测一个边界框。在 YOLOv1 中,每个单元预测两个边界框,向量结构为:
$$ C_{1, 1} = (P^1_c, B^1_x, B^1_y, B^1_w, B^1_h, P^2_c, B^2_x, B^2_y, B^2_w, B^2_h, C_1, C_2) $$
其中上标表示边界框索引。类别数量可以根据需求扩展(如最多 20 类)。
整个图像可表示为一个 $S×S×(B×5 + C)$ 的张量,其中:
- B:边界框数量
- C:类别数量
4. YOLO 的改进版本
YOLO 的多个版本在准确率和速度之间不断优化:
4.1 YOLO v2:引入锚框(Anchor Boxes)
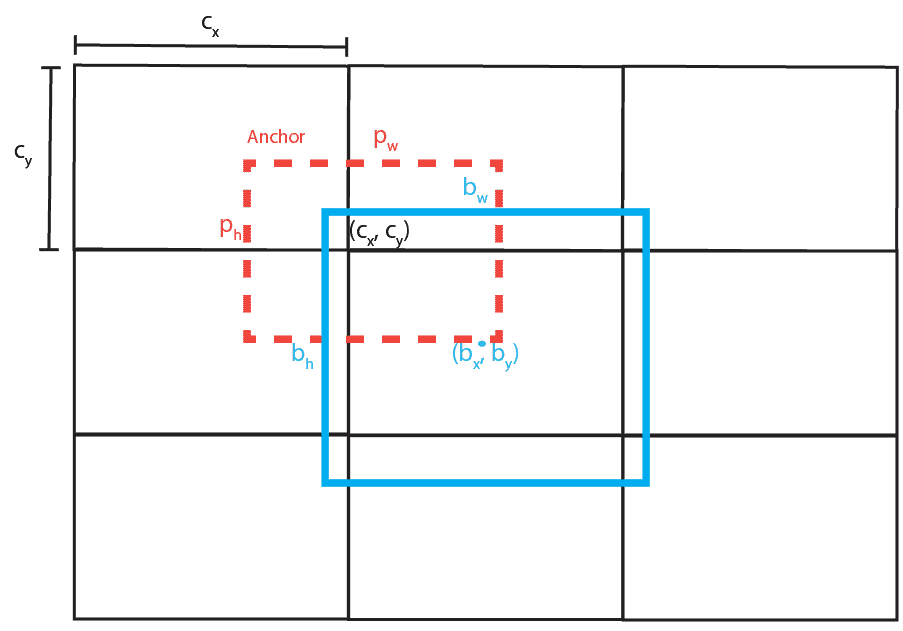
YOLO v2 引入了 锚框(Anchor Boxes),预先定义一组边界框尺寸,通过 K-Means 聚类得到最优尺寸,提升对不同尺度物体的适应能力。
锚框不是滑动窗口,而是作为预测的参考,YOLO v2 会预测相对于锚框的偏移量,公式如下:
$$ \begin{align*} b_x &= \sigma(t_x) + c_x\ b_y &= \sigma(t_y) + c_y\ b_w &= p_w e^{t_w}\ b_h &= p_h e^{t_h} \end{align*} $$
其中:
- $p_w, p_h$:锚框的宽高
- $c_x, c_y$:网格左上角坐标
- $\sigma$:Sigmoid 函数
4.2 后续版本改进
- YOLO v3:使用更深的 CNN(53 层),支持多尺度预测
- YOLO v4:引入加权残差连接、跨阶段部分连接、CIoU 损失等
- YOLO v5:基于 PyTorch 实现,支持自动学习边界框和数据增强
此外还有 PP-YOLO、YOLOX 等变体,但本文不做深入介绍。
5. 应用场景
YOLO 凭借其高效准确的特性,在多个领域有广泛应用:
✅ 自动驾驶:识别车辆、行人、交通标志
✅ 安防监控:检测禁区入侵者
✅ 工业质检:识别生产线异常
✅ 体育分析:跟踪运动员位置
✅ 医疗影像:辅助诊断系统
6. 总结
YOLO 是一种高效的目标检测算法,通过一次前向传播完成检测任务,适合对实时性要求较高的场景。从 YOLOv1 到 YOLOv5,其结构和性能不断优化,已成为目标检测领域的标杆算法之一。
虽然本文侧重理论讲解,但 YOLO 的开源实现非常丰富,例如 YOLOv5 GitHub 仓库,非常适合用于实战部署。
📌 建议阅读:
- YOLOv5 GitHub 项目
- YOLOv7 官方论文(进阶)
- YOLOX 论文(轻量级变体)