1. 简介
本文将介绍三种在二叉搜索树(BST)中查找节点中序后继的方法。 在 BST 中,每个节点的值都大于其左子树中的所有节点,小于其右子树中的所有节点。
节点可以是数字、字符串、元组,甚至是可比较的对象。
2. 什么是中序后继?
中序遍历是一种递归定义的树遍历方式,其顺序为:先访问左子树,再访问当前节点,最后访问右子树。
algorithm InOrderTraverse(node):
// INPUT
// node = a node in a tree
// OUTPUT
// Visits nodes in an in-order sequence
if node != NONE:
InOrderTraverse(node.left)
visit(node)
InOrderTraverse(node.right)
在 BST 中使用中序遍历时,节点会按照非降序排列。例如下面这棵树:
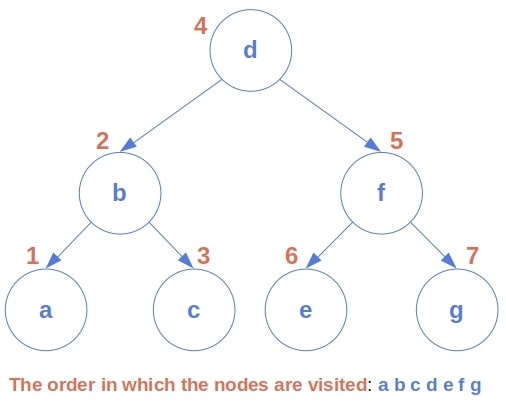
我们的目标是找到给定节点 x 在中序遍历中的下一个节点,即它的中序后继。 这个后继是树中比 x 大的所有节点中最小的那个。
2.1. 中序后继的位置规律
观察上图可以发现一些规律:
- 如果节点
x有右子节点,它的中序后继就是右子树中最左边的节点(最小节点)。这是因为中序遍历在访问完x后会进入它的右子树,而第一个访问的就是右子树的最左节点。 - 如果
x没有右子节点,它的中序后继位于其祖先中某个特定的位置。 此时我们需要回溯到某个祖先节点,这个祖先节点是某个左子节点的父节点。
3. 在出树(Out-Tree)中查找中序后继
通常,我们将节点实现为包含内容、左子节点和右子节点的结构体。这种结构对应的是“出树”(out-tree),即边从根节点向外延伸的树。
3.1. 算法
查找中序后继的步骤如下:
- 从根节点开始查找目标节点
x,并在查找过程中记录所有左子节点的父节点。 - 如果
x有右子节点,则返回右子树中最左的节点。 - 否则,返回最近记录的那个父节点。
algorithm FindSuccessorOutTree(x, root):
// INPUT
// x = the node whose successor we search for
// root = the root of the out-tree to search
// OUTPUT
// The in-order successor of x in the tree, or NONE if x is not there
parent <- NONE
node <- root
while node != NONE and node.content != x:
if x < node.content:
parent <- node
node <- node.left
else:
node <- node.right
if node = NONE:
return NONE
if node.right != NONE:
successor <- node.right
while successor.left != NONE:
successor <- successor.left
return successor
else:
return parent
如果 x 是树中最大的节点,它没有中序后继,此时返回 NONE。
3.2. 时间复杂度分析
设 h 为树的高度,d(root, x) 表示从根节点到 x 的路径长度。
- 如果
x没有右子节点,最多需要查找d(root, x) ≤ h步。 - 如果
x有右子节点,最多查找路径长度为h的叶子节点。
因此,**最坏情况下时间复杂度为 O(h)**。
- 如果树是平衡的,
h = O(log n),则算法运行时间为O(log n)。 - 如果树是退化的(如链表),则
h = O(n),算法运行时间为O(n)。
4. 在双向链表结构的 BST 中查找中序后继
有时我们会为每个节点增加一个指向父节点的指针,这种结构称为“双向 BST”。虽然会占用更多内存,但能简化很多操作。
4.1. 算法
在这种结构中,我们不需要在查找过程中记录父节点。如果 x 没有右子节点,我们只需沿着父节点指针向上查找,直到找到某个是其父节点左子节点的节点,其父节点即为中序后继。
algorithm FindSuccessorBidirectional(x, root):
// INPUT
// x = the node whose successor we search for
// root = the root of the bidirectional tree to search
// OUTPUT
// The in-order successor of x in the tree, or NONE if x isn't there
node <- root
while node != NONE and node.content != x:
if x < node.content:
node <- node.left
else:
node <- node.right
if node = NONE:
return NONE
if node.right != NONE:
successor <- node.right
while successor.left != NONE:
successor <- successor.left
return successor
else:
while node.parent != NONE and node.parent.left != node:
node <- node.parent
return node.parent
时间复杂度分析
与出树结构相同,**最坏情况下时间复杂度仍为 O(h)**。
5. 中序遍历查找法
第三种方法是直接进行中序遍历,直到找到比 x 大的第一个节点。由于中序遍历是按升序进行的,所以第一个大于 x 的节点即为其后继。
5.1. 算法实现
algorithm InOrderSearch(node, x):
// INPUT
// node = the node we're currently traversing
// x = the node whose successor we search for
// OUTPUT
// The in-order successor of x
if node != NONE:
successor <- InOrderSearch(node.left, x)
if successor != NONE:
return successor
else:
if node.content > x:
return node.content
else:
return InOrderSearch(node.right, x)
5.2. 时间复杂度分析
- 最坏情况下需要遍历整个树,即
O(n)时间。 - 如果
x是树中最大节点,则必须访问所有节点才能确认它没有后继。
6. 总结与讨论
| 方法 | 时间复杂度 | 适用场景 |
|---|---|---|
| 出树结构查找 | O(h) |
树结构稳定,支持快速查找 |
| 双向结构查找 | O(h) |
支持频繁查找与回溯 |
| 中序遍历查找 | O(n) |
树结构不稳定或频繁更新,且 x 排名靠前 |
⚠️ 注意: 如果树中存在多个值为 x 的节点,上述方法都会返回第一个大于 x 的节点作为后继。
7. 总结
本文介绍了三种查找中序后继的方法:
✅ 出树结构查找法 和 双向结构查找法 都利用了 BST 的结构特性,效率较高,适合树结构稳定的情况。
✅ 中序遍历查找法 实现简单,但效率较低,适用于树结构频繁变动的场景。
根据实际需求选择合适的方法非常重要。如果树是平衡的,前两种方法效率更高;如果树经常更新,中序遍历可能更实用。