1. 引言
“我们的潜在客户是谁?”、“我们即将推出的产品应具备哪些特征?”——这是当下每一家公司都希望解答的问题。
为了找到这些答案,企业纷纷开始收集并堆积大量数据。正如尼尔森的标语所说:“人们看什么、听什么、买什么”,各类数据都被收集起来。尽管如此,数据量大并不等同于知识多。
现实情况是,结构化与非结构化数据充斥着整个数字世界。在这种背景下,从海量数据中提取知识在决策过程中扮演着至关重要的角色。我们可以通过数据挖掘工具来预测趋势,并据此做出基于知识的决策。
在本教程中,我们将学习使用 WEKA 这一数据挖掘工具。
2. 数据挖掘简介
简单来说,数据挖掘 是在大型数据集中寻找模式和关联,从而预测结果的过程。这些结果可以揭示数据中的趋势、共同主题或规律。
例如,一家超市的老板想了解哪些商品经常被一起购买。通过对客户交易记录的几周分析后,他发现:
- 当顾客购买牛奶时,面包的销量意外增长了75%
- 60%的人喜欢同时购买鸡蛋、牛奶和面包
基于这些信息,老板可以确保在合适的时间和地点备足相关商品,以提升营收。
✅ 数据挖掘帮助企业发现急需的知识。
2.1 数据挖掘流程
数据挖掘通常包括以下几个步骤:
- 数据获取、清洗与整合:从不同来源获取数据,并去除不一致之处,使其统一。
- 特征选择:数据中往往包含大量无关属性,选择合适的特征并进行降维是产出高质量结果的关键。
- 算法选择:根据问题类型选择合适的算法,如分类、聚类等。
- 模式解释:由数据挖掘算法生成的模式和规则需要被解读为可操作的知识。
整个流程从原始数据到最终决策,每一步都至关重要。
3. WEKA 概述
WEKA 是一个用于数据挖掘任务的机器学习算法工作台。它涵盖了从数据准备、可视化,到分类、聚类等各类任务。虽然 WEKA 最强项是分类,但它也支持回归、聚类、关联规则挖掘等功能。
它是基于 GNU 通用公共许可证发布的开源工具。
3.1 安装与要求
WEKA 支持 Windows、Mac OS 和 Linux 系统。最新稳定版要求 Java 8 或更高版本。
WEKA 的主界面如下图所示:
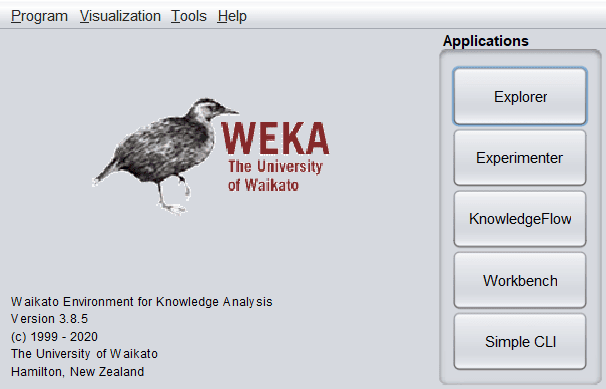
在 Applications 分类下有五个选项:
- Explorer:核心功能区,大部分数据挖掘任务在此完成。
- Experimenter:用于设计和运行实验。
- KnowledgeFlow:提供拖拽式组件接口,构建知识流并分析数据。
- Simple CLI:命令行接口,可执行 WEKA 命令。例如,使用
ZeroR分类器对iris.arff数据进行训练:
java weka.classifiers.trees.ZeroR -t iris.arff
3.2 数据集
数据是数据挖掘任务的核心。本教程将使用经典的 Iris 数据集 来训练和测试多个算法。该数据集包含三个类别(鸢尾花种类)和四个特征(花萼和花瓣的长度与宽度)。
3.3 数据类型与格式
WEKA 支持以下四种数据类型:
- 数值型(Integer、Real)
- 字符串(String)
- 日期(Date)
- 关系型(Relational)
默认支持 ARFF 格式(Attribute-Relation File Format),这是一种 ASCII 格式,用于描述具有相同属性集的实例列表。
每个 ARFF 文件分为两部分:header 和 data。header 部分定义属性类型,data 部分则是用逗号分隔的数据列表。注意:@attribute 和 @data 的声明不区分大小写。
例如一个天气预测数据集的 ARFF 示例:
@attribute outlook {sunny,overcast,rainy}
@attribute tempreture {hot,mild,cool}
@attribute humidity {high,normal}
@attribute windy {TRUE,FALSE}
@attribute play {yes,no}
@data
sunny,hot,high,FALSE,no
sunny,hot,high,TRUE,yes
overcast,hot,high,TRUE,yes
overcast,cool,normal,TRUE,yes
rainy,cool,normal,FALSE,no
rainy,cool,normal,TRUE,no
WEKA 也支持 CSV、JSON 和 XRFF 等其他格式。
3.4 数据加载
WEKA 支持从以下四种来源加载数据:
- 本地文件系统
- 公共 URL
- 数据库查询
- 生成人工数据
加载数据后,下一步是预处理。可以在 Filter 标签下选择合适的处理方式:
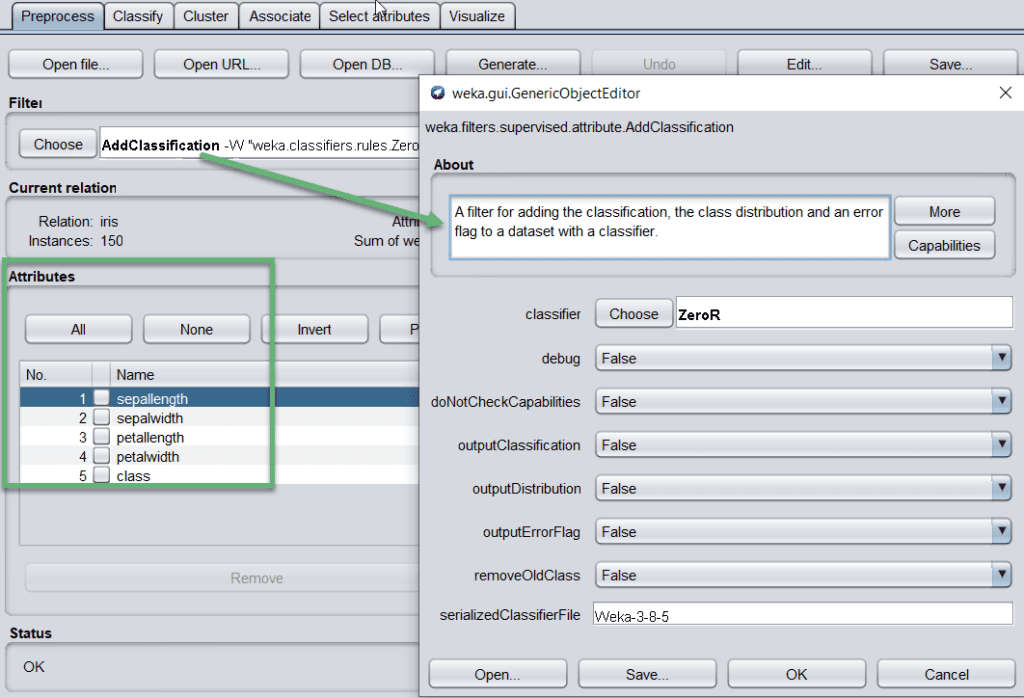
如果某个属性(如 sepallength)存在错误或异常值,可以从 Attributes 部分中删除或更新。
3.5 机器学习算法分类
WEKA 提供了丰富的机器学习算法,按功能分类如下:
- bayes:基于贝叶斯定理的算法,如 Naive Bayes
- functions:函数估计类算法,如 Linear Regression
- lazy:惰性学习算法,如 KStar, LWL
- meta:集成多个算法的元算法,如 Stacking, Bagging
- misc:不属于其他类的杂项算法
- rules:基于规则的算法,如 OneR, ZeroR
- trees:基于决策树的算法,如 J48, RandomForest
每个算法都提供配置参数,如 batchSize、debug 等。部分参数为通用配置,部分则为特定算法独有。
4. WEKA 的核心功能模块
4.1 数据预处理(Preprocess)
数据预处理是数据挖掘中极为关键的一步。原始数据往往存在缺失值、重复值、异常值、多余字段或命名不一致等问题,这些问题会直接影响分析结果。
WEKA 提供了丰富的 Filter 工具用于数据清洗和转换,包括监督和非监督方式。
常见预处理操作包括:
ReplaceMissingWithUserConstant:填充缺失值ReservoirSample:生成随机子集NominalToBinary:将名义属性转换为二进制RemovePercentage:按比例删除数据RemoveRange:按范围删除数据
4.2 分类(Classify)
分类 是机器学习中最基础的任务之一,用于为对象分配类别标签。例如:
- 判断脑肿瘤是“恶性”还是“良性”
- 判断邮件是否为“垃圾邮件”
选择分类器后,可以选择以下测试方式:
- 使用训练集测试
- 使用独立测试集
- 交叉验证(Cross-validation)
- 百分比分割(Percentage split)
还可以启用如“保留分割顺序”、“输出源代码”等高级选项。
应用 ZeroR 分类器后,WEKA 会生成评估结果,如下图所示:
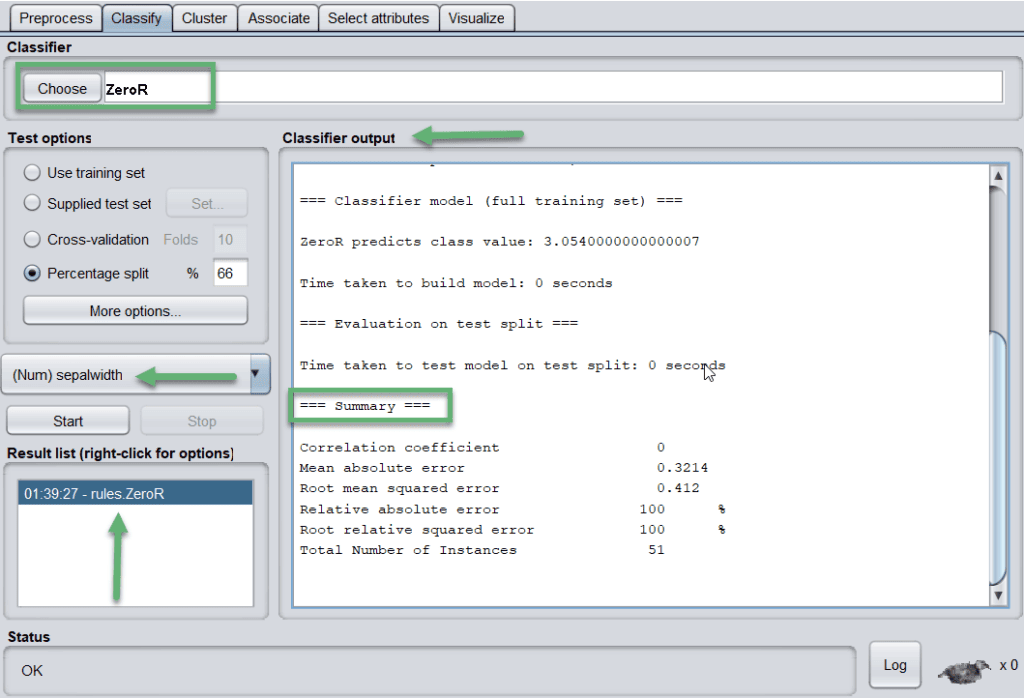
评估结果会保存在 Result list 中,也可以以图形方式展示误差:
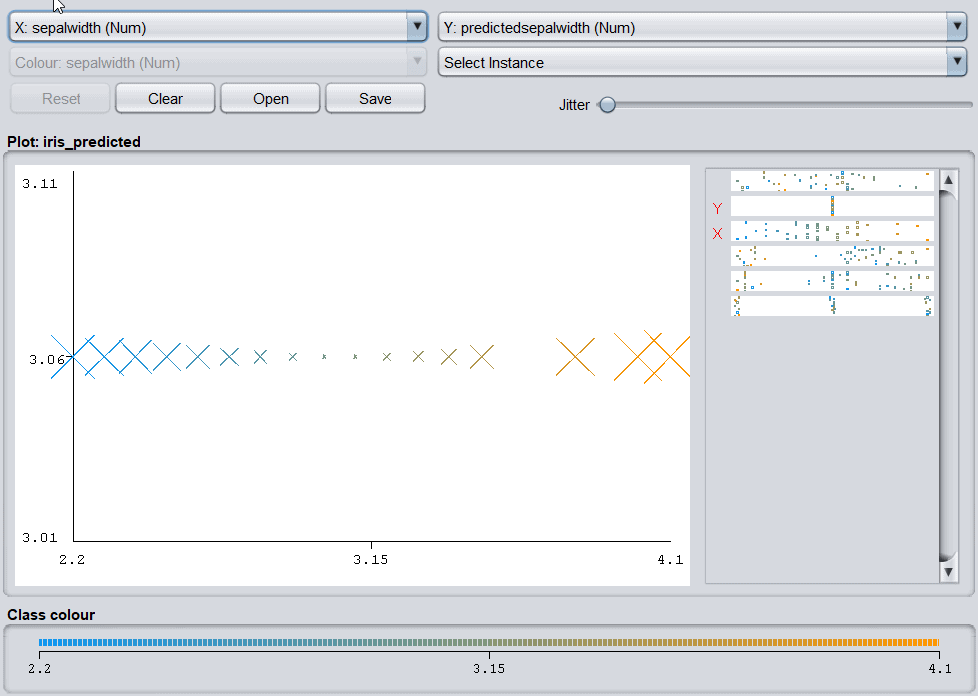
4.3 聚类(Cluster)
聚类 是将数据集划分为多个组,组内数据相似、组间差异明显。常见应用场景包括:
- 识别行为相似的客户群
- 按土地用途划分区域
使用 EM 算法时,WEKA 会展示每个聚类的均值和标准差:
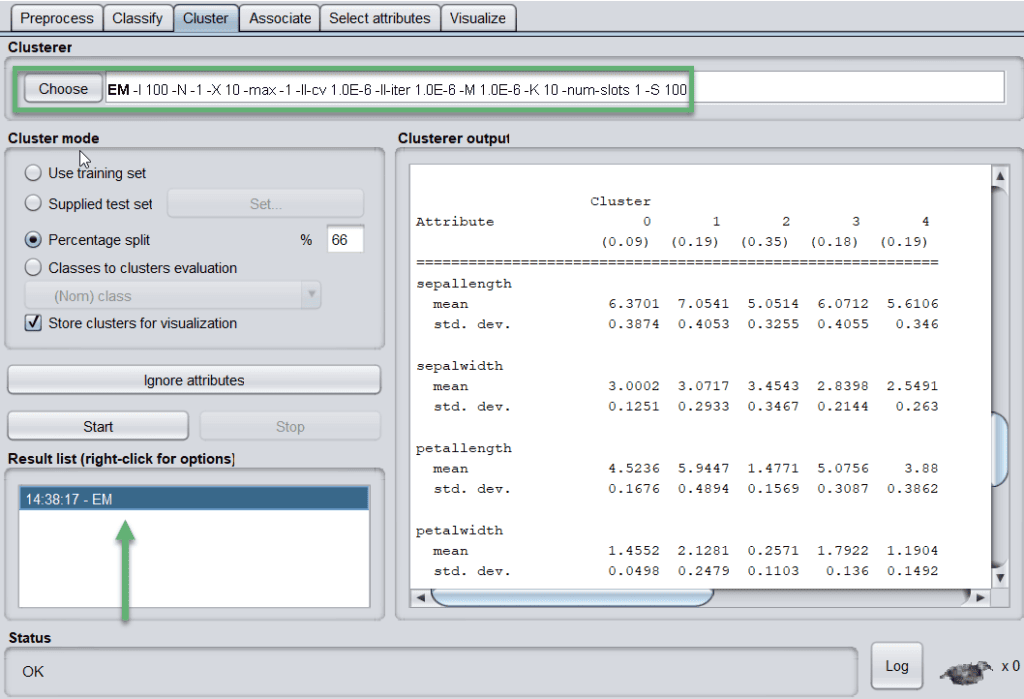
聚类结果也可以可视化展示:
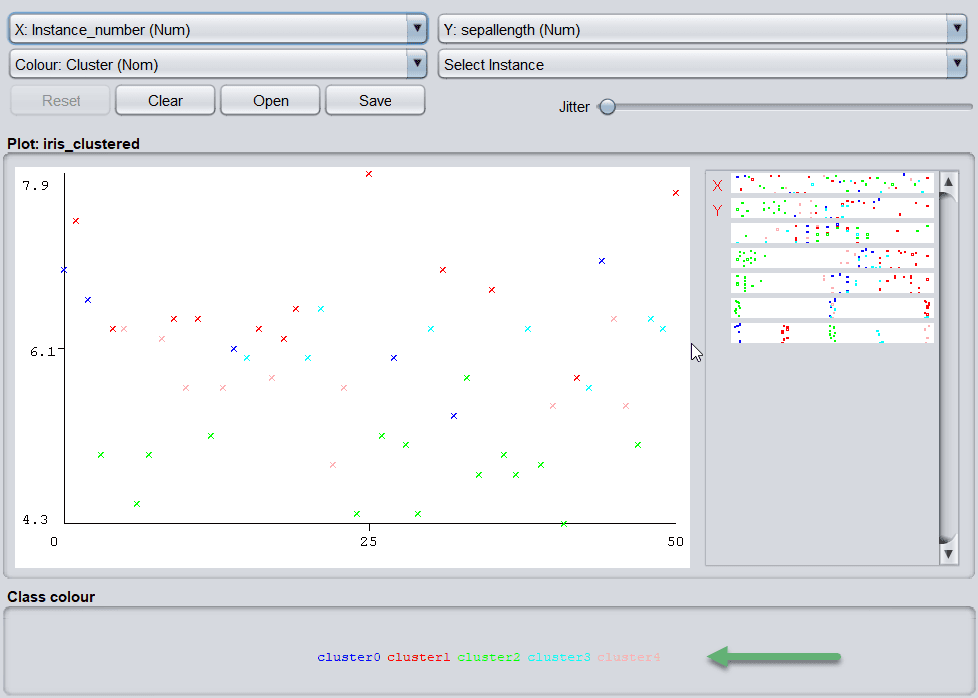
常用聚类算法包括:
- SimpleKMeans
- HierarchicalClusterer
- EM
4.4 关联规则(Associate)
关联规则挖掘用于发现数据集中项目之间的关系,通常以“if-then”的形式表示。例如:
- 购买牛奶的人也常购买面包
WEKA 提供的关联规则挖掘算法包括:
- Apriori
- FilteredAssociator
- FPGrowth
4.5 特征选择(Select Attributes)
数据集中通常包含大量属性,但并非每个属性都对模型有帮助。因此,筛选出相关性高的特征是建模的关键。
WEKA 提供多种特征评估方法和搜索策略,包括:
- BestFirst
- GreedyStepwise
- Ranker
4.6 数据可视化(Visualize)
在 Visualize 标签页中,WEKA 提供了多种图表和矩阵用于展示数据趋势和模型误差。
例如,Iris 数据集的部分可视化结果如下:
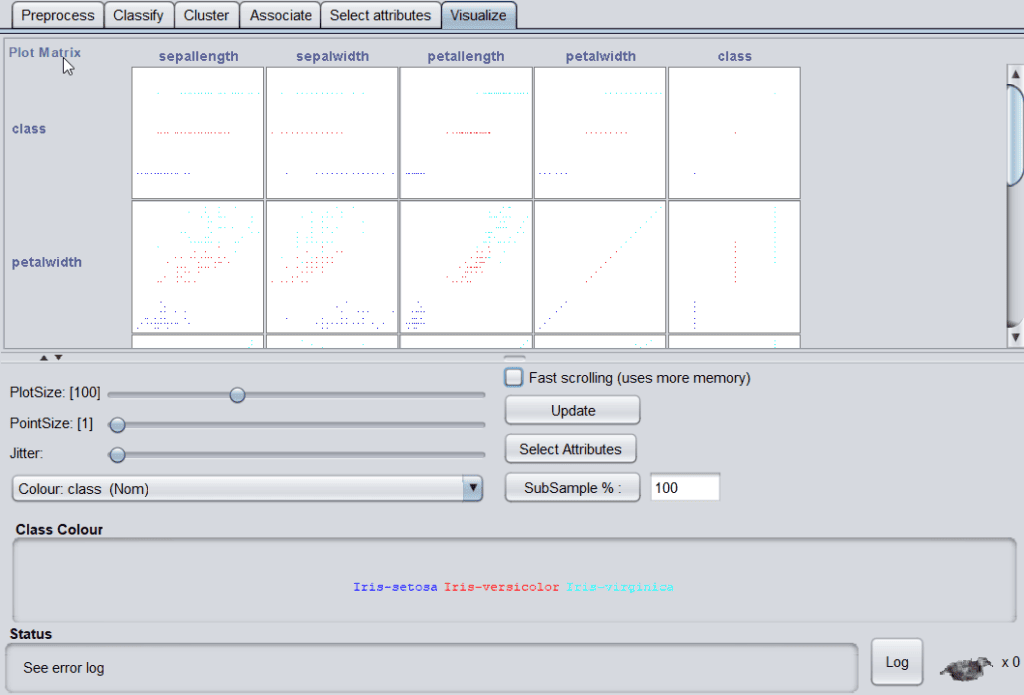
5. 总结
从零售市场到医疗健康,从体育分析到安防监控,数据分析无处不在。毫无疑问,从原始数据中提取知识需要大量努力,但这些知识可以帮助我们做出智能决策、开展精准营销、提升营收、改善客户关系、降低风险、识别在线欺诈等。
在本文中,我们介绍了 WEKA,这是一个功能全面的数据挖掘工具箱。它从数据清洗、特征选择,到各类算法的应用都提供了丰富的选项。最终,WEKA 让我们更轻松地处理大规模数据,并对比不同模型的输出结果,从而得出有价值的结论。