1. 简介
在本文中,我们将探讨实现字典的几种常见方式,并分析它们的优缺点。字典作为存储和查询词语及其含义的重要结构,其底层数据结构的选择直接影响性能和扩展性。
2. 什么是字典?
字典是一种存储词语及其含义,并可能关联其他条目的数据结构。传统纸质字典无法满足计算机处理需求,因此数字字典在自然语言处理(NLP)中广泛应用。
在实际使用中,我们通常通过词语查询其定义。如果词语存在,返回其定义;否则返回未找到。此外,我们还可能需要支持范围查询或前缀查询。本文将围绕这些场景展开讨论。
3. 字典的实现方式
3.1 排序数组
我们可以将字典维护为一个排序数组,每个元素是“词语:定义”的字符串形式。通过排序字符串数组,我们也就对词语进行了排序。
✅ 优点:
- 实现简单
- 支持二分查找,查询复杂度为 O(log N)
❌ 缺点:
- 数组占用连续内存,不适合大规模数据
- 插入/删除效率低,需重新排序
- 适合静态字典,不适合频繁更新的场景
📌 踩坑提醒:虽然单次查询快,但如果要查询 M 个词,总复杂度是 O(M log N),在大量查询场景下可能成为瓶颈。
3.2 哈希表
哈希表是实现字典最常用的方式之一。使用哈希表可以实现平均 O(1) 的查询效率。
✅ 优点:
- 查询速度快
- 支持动态插入和删除
❌ 缺点:
- 存在哈希冲突问题,极端情况下查询复杂度退化为 O(N)
- 不支持范围或前缀查询
📌 示例图:

📌 踩坑提醒:对于动态字典,需要考虑哈希表扩容机制,通常每次扩容为原来的两倍。
3.3 Trie(前缀树)
Trie 是一种树形结构,特别适合处理字符串集合中存在大量公共前缀的场景。
✅ 优点:
- 天然支持前缀查询
- 插入、删除、查询复杂度均为 O(L),L 为词长
- 不需要哈希函数
❌ 缺点:
- 普通实现内存占用高
- 对于短词效率优势不明显
📌 示例图:
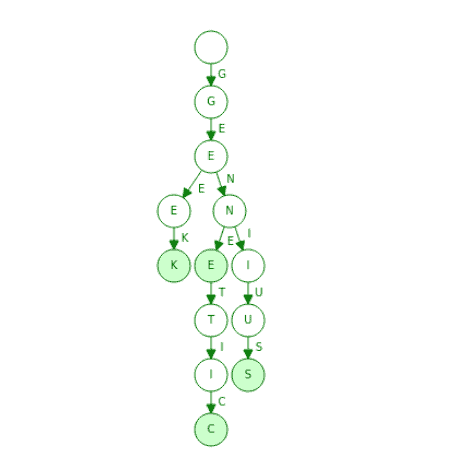
📌 踩坑提醒:对于大规模词库,建议使用压缩版本的 Trie,如 Radix Tree、DAWG 等,以节省内存。
3.4 布隆过滤器(Bloom Filter)
布隆过滤器是一种概率型数据结构,用于判断一个元素是否存在于集合中。
✅ 优点:
- 空间效率极高
- 插入和查询时间复杂度低,为 O(k),k 为哈希函数数量
❌ 缺点:
- 存在误判(False Positive),即可能误判一个不存在的词为存在
- 不支持删除操作
- 无法存储定义,只能作为辅助结构
📌 示例图:
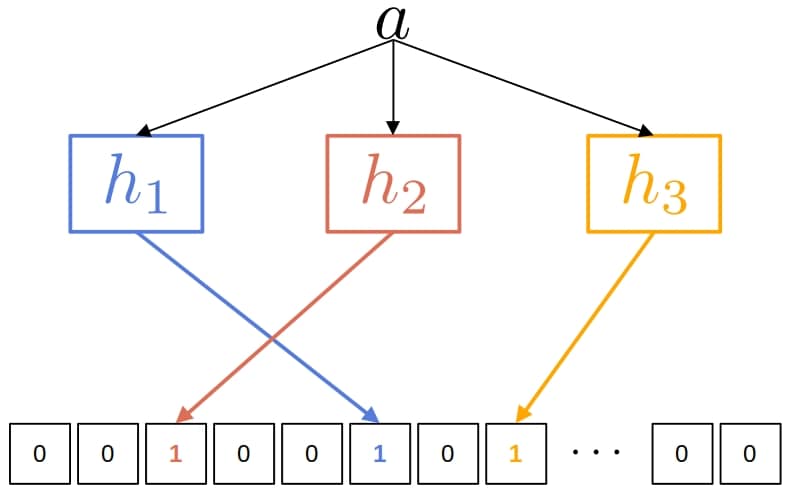
📌 踩坑提醒:使用布隆过滤器前应预估词库规模,否则误判率会迅速升高。
📌 布隆过滤器的典型用法是作为哈希表前的“缓存层”,快速过滤掉不存在的查询词,减少对主字典的访问压力。
4. 总结
选择字典的实现方式取决于具体场景:
| 场景 | 推荐结构 | 理由 |
|---|---|---|
| 静态词库,仅查询 | 哈希表 / 布隆过滤器 | 查询快,实现简单 |
| 动态词库 | 哈希表 / Trie | 支持增删改 |
| 支持前缀查询 | Trie | 天然支持 |
| 大规模词库 + 高效查询 | Trie + 哈希表 + 布隆过滤器组合使用 | 平衡性能与内存 |
📌 最佳实践建议:在实际项目中,往往采用多结构组合的方式来实现字典,例如用 Trie 支持前缀搜索,用哈希表提供快速定义查询,用布隆过滤器过滤无效查询。