1. 概述
循环神经网络(Recurrent Neural Networks,RNN)是一种擅长处理序列数据的神经网络。与之相关但略有不同的还有递归神经网络(Recursive Neural Networks,RvNN),它更适合捕捉层次结构模式。
本文将介绍 RNN 与 RvNN 的基本原理、训练方式及其在自然语言处理(NLP)中的典型应用场景,并分析它们在 NLP 任务中的优缺点。
2. 循环神经网络(RNN)
RNN 是一类能够建模时间序列的神经网络结构,非常适合处理具有顺序特性的语言数据,如句子、段落等。
2.1. 定义
假设我们有一个长度任意的序列:
$$ x_1, x_2, \ldots $$
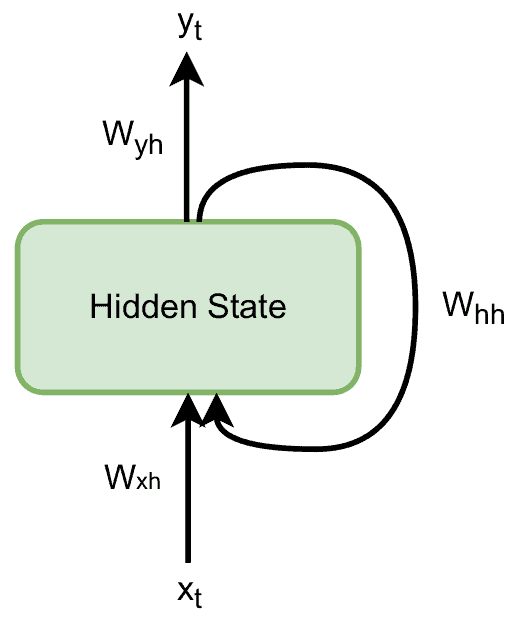
RNN 按照时间步(time step)依次处理序列中的每一个元素。在第 $ t $ 步,它产生输出 $ y_t $,并维护一个隐藏状态 $ h_t $,用于表示子序列 $ x_1, x_2, \ldots, x_t $ 的信息。
隐藏状态 $ h_t $ 是通过将前一步的隐藏状态 $ h_{t-1} $ 和当前输入 $ x_{t-1} $ 与权重矩阵 $ W_{hh} $ 和 $ W_{xh} $ 相乘,并应用变换函数 $ f_W $ 得到的:
$$ h_t = f_W(W_{hh}h_{t-1} + W_{xh}x_{t-1}) $$
输出 $ y_t $ 则是隐藏状态 $ h_t $ 与权重矩阵 $ W_{yh} $ 的乘积:
$$ y_t = W_{yh}h_t $$
由于所有时间步共享相同的权重矩阵,RNN 的结构非常简洁,如下图所示:
2.2. 训练
RNN 的训练目标是学习这些变换矩阵。通常使用梯度下降法进行优化。
权重和初始隐藏状态通常随机初始化。激活函数 $ f_W $ 可以选用如 $ \tanh $ 函数:
$$ \tanh (z) = \frac{e^{2z} - 1}{e^{2z} + 1} $$
2.3. 示例:机器翻译
一个典型的 RNN 应用是编码器-解码器模型用于机器翻译。例如,英文句子作为输入,经过编码器后,由解码器生成对应的西班牙语翻译:
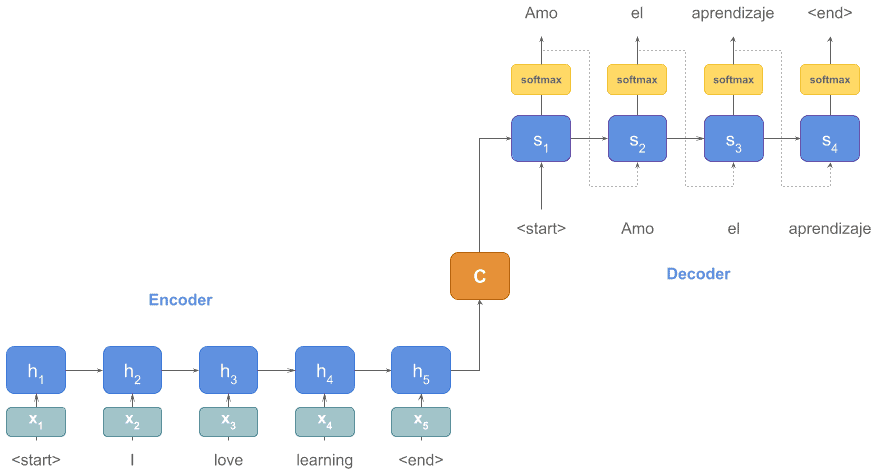
编码器和解码器都可以使用 RNN 实现。无论输入句子长短,RNN 都可以一直处理直到遇到 end 标记。✅ 这体现了 RNN 的灵活性。
2.4. 在 NLP 中的优势
RNN 的优势主要体现在以下三点:
- ✅ 支持任意长度输入:不同于 CNN 只能处理固定长度输入,RNN 可以处理从短句到长文本的各种序列。
- ✅ 隐藏状态具有记忆能力:随着序列的处理,隐藏状态会不断融合前面的信息,形成对整个序列的抽象表示。
- ✅ 权重共享机制:不同时间步共享相同的权重矩阵,使得模型参数数量不随序列长度变化。
2.5. 在 NLP 中的劣势
RNN 也有几个显著缺点:
- ❌ 训练效率低:由于每一步的计算依赖前一步,难以并行化,训练速度慢。
- ❌ 梯度消失/爆炸问题:长序列中梯度可能趋近于零或无限放大,影响模型学习。可通过使用 ReLU 激活函数或 LSTM 等变体缓解。
- ❌ 难以捕捉长距离依赖:例如句子开头的词与结尾的词之间可能存在语义关联,但 RNN 容易遗忘早期信息。
例如:
Programming is a lot of fun and exciting especially when you're interested in teaching machines what to do. I've seen many people from five-year-olds to ninety-year-olds learn it.
句末的 it 指代句首的 programming,RNN 可能难以建立这种长距离联系。⚠️ 此时推荐使用 LSTM 或双向 LSTM(BiLSTM)。
3. 递归神经网络(RvNN)
RvNN 是 RNN 的泛化版本,其结构为树状而非线性,因此更适合处理具有层次结构的数据,例如语法树。
3.1. 定义
RvNN 的树结构意味着它通过组合子节点来生成父节点。每个子节点与父节点之间的连接都有一个权重矩阵。相同位置的子节点共享权重。
以二叉树为例,所有左子节点共享一个权重矩阵,所有右子节点共享另一个权重矩阵。此外,还需要一个初始权重矩阵 $ V $ 来处理原始输入:
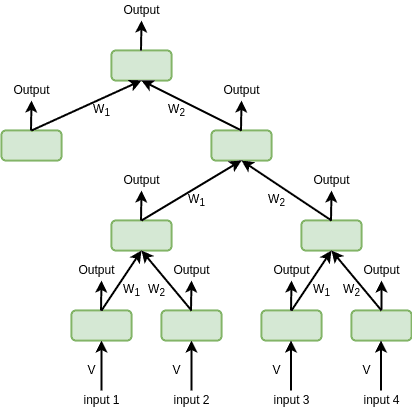
父节点的表示由子节点的加权和并通过激活函数 $ f $ 得出:
$$ h = f \left( \sum_{i=1}^{c} W_i C_i \right) $$
其中 $ c $ 是子节点数量,$ C_i $ 是第 $ i $ 个子节点的表示。
3.2. 训练
RvNN 的训练方式与 RNN 类似,使用梯度下降法优化。模型需要学习每个子节点对应的权重矩阵 $ W_1, W_2, \ldots, W_c $,这些权重在不同递归层级中共享。
3.3. 示例:句法分析(Syntactic Parsing)
RvNN 的一个典型应用是自然语言句法分析。例如,将句子分解为名词短语、动词短语等成分,并构建语法树:
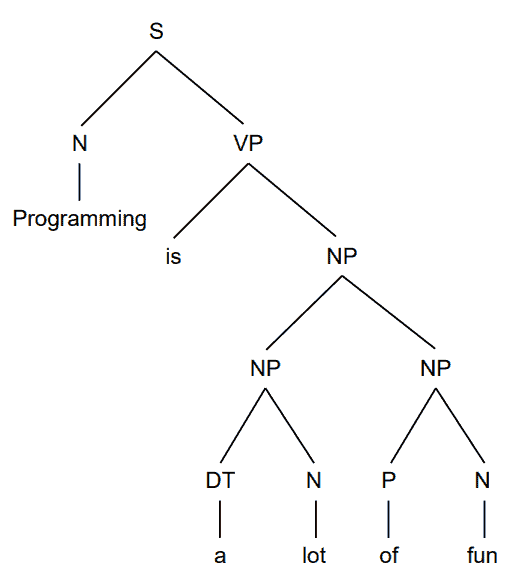
以句子:
Programming is a lot of fun.
为例,RNN 无法单独表示短语 a lot of fun,因为其隐藏状态总是包含整个句子的信息。而 RvNN 则可以在节点 $ R_{a\ lot\ of\ fun} $ 中单独保存该短语的表示:
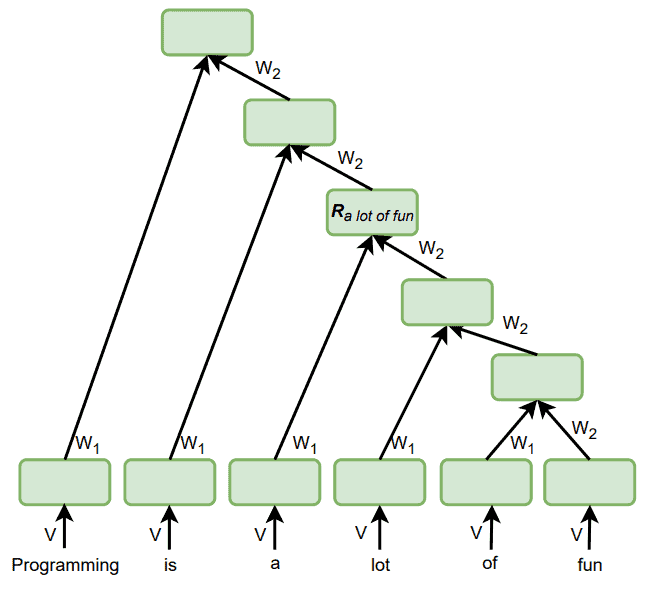
这体现了 RvNN 在结构化建模上的优势。
3.4. 在 NLP 中的优势
- ✅ 支持层次结构建模:适用于句法分析、语义组合等任务。
- ✅ 网络深度更浅:树结构可以将输入元素之间的距离缩短,有助于缓解长距离依赖问题。例如,输入长度为 $ O(n) $,二叉树高度为 $ O(\log n) $。
3.5. 在 NLP 中的劣势
- ❌ 引入归纳偏置:RvNN 假设数据具有树状结构,若数据不符合该假设,模型性能可能下降。
- ❌ 解析效率低且存在歧义:一个句子可能有多个合法的语法树,导致训练和推理过程更复杂。
- ❌ 标注成本高:构建 RvNN 的训练数据需要手动标注语法结构,比 RNN 的序列标注更费时费力。
4. RNN 与 RvNN:对比总结
| 使用场景 | 推荐模型 |
|---|---|
| 序列数据处理 | ✅ RNN |
| 层次结构建模 | ✅ RvNN |
| 输入长度可变 | ✅ RNN |
| 网络深度更浅 | ✅ RvNN |
5. 总结
本文对比了 RNN 和 RvNN 的结构特点、训练方式及其在 NLP 中的应用场景和优缺点。
核心区别在于:RNN 擅长捕捉序列模式,而 RvNN 更适合建模层次结构数据。根据任务需求选择合适的模型,可以显著提升模型表现和训练效率。
在实际项目中,如果任务强调语法结构或语义组合,推荐使用 RvNN;而处理文本生成、机器翻译等任务时,RNN 或其变体(如 LSTM、GRU)仍然是主流选择。