1. 引言
在本篇文章中,我们将深入理解什么是特征描述符(Feature Descriptor),以及它在数字图像处理中扮演的重要角色。我们会探讨如何通过特征向量(Feature Vector)来描述图像中的兴趣点,并讲解如何利用这些向量在不同图像中识别出相似的兴趣点。
2. 为什么要使用特征描述符?
特征描述符是一种将图像中的兴趣点转化为数值特征向量的方法,它把这些点的信息编码成多维向量空间中的一个点,便于后续的匹配、识别等操作。
2.1. 兴趣点(Interest Points)
- ✅ 兴趣点通常是图像中纹理丰富、边缘变化剧烈的区域。
- ✅ 它们具有良好的定位性,即使图像发生尺度、旋转或光照变化,也能稳定地被检测出来。
- ❗兴趣点的准确检测和重复性是图像匹配任务成功的关键。
2.2. 特征描述符(Feature Descriptors)
- ✅ 是对兴趣点的数学或逻辑描述,通常以数值向量形式表示。
- ✅ 可以理解为兴趣点的“指纹”,用于区分不同的图像特征。
- ✅ 通过特征描述符,我们可以从图像数据中提取出有价值的信息,降低维度,提升处理效率。
2.3. 特征向量(Feature Vectors)
- ✅ 是特征描述符的数学表示,通常是一个多维向量。
- ✅ 多个特征向量可以组合成一个特征空间(Feature Space)。
- ✅ 向量维度越高,描述越精细,但计算开销也越大。
2.4. 对应问题(Correspondence Problem)
- ✅ 图像匹配的核心问题之一:如何在两幅图像中找到对应的兴趣点。
- ✅ 这些图像可能是同一场景在不同视角、不同时间下拍摄的。
- ✅ 通过匹配特征向量来解决对应问题,是计算机视觉中的关键步骤。
3. 特征空间(Feature Space)
特征空间是一个由特征向量构成的多维空间,用于表示图像中各种特征的分布情况。
3.1. 特征空间的维度
- ✅ 每个维度代表一个特征属性,如颜色、纹理、边缘方向等。
- ✅ 维度越高,信息越丰富,但也会带来“维度灾难”问题。
- ✅ 在实际应用中,通常需要进行特征选择或降维处理。
3.2. 特征向量在特征空间中的表示
- ✅ 每个特征向量对应特征空间中的一个点。
- ✅ 实际图像处理中,特征向量可能有上百个维度,难以直观可视化。
- ✅ 为简化处理,常使用嵌入(Embedding)将高维向量映射到低维空间。
3.3. 特征向量的相似性度量
为了判断两个特征向量是否来自同一个兴趣点,我们需要计算它们之间的相似度。常用方法包括:
| 方法 | 描述 |
|---|---|
| 欧氏距离(Euclidean Distance) | 衡量两个向量在空间中的直线距离 |
| 余弦相似度(Cosine Similarity) | 衡量两个向量之间的夹角余弦值 |
| 点积(Dot Product) | 衡量向量方向和长度的综合相似性 |
⚠️ 这些方法通常输出一个相似度分数,而不是二元的“匹配”或“不匹配”。
4. 特征描述符的类型
根据描述的范围不同,特征描述符可分为两大类:
4.1. 局部描述符(Local Descriptors)
- ✅ 描述图像中某个局部区域(如兴趣点周围的像素块)。
- ✅ 更具鲁棒性,适用于物体识别、图像拼接等任务。
- ✅ 常见算法:SIFT、SURF、LBP、BRISK、MSER、FREAK
4.2. 全局描述符(Global Descriptors)
- ✅ 描述整张图像的整体特征。
- ✅ 更适合用于图像分类、检索等任务。
- ✅ 常见算法:HOG(方向梯度直方图)、HOF(光流直方图)、MBH(运动边界直方图)、形状矩阵、不变矩等
以下是一个使用HOG、HOF、MBH组合生成的长特征向量示例:
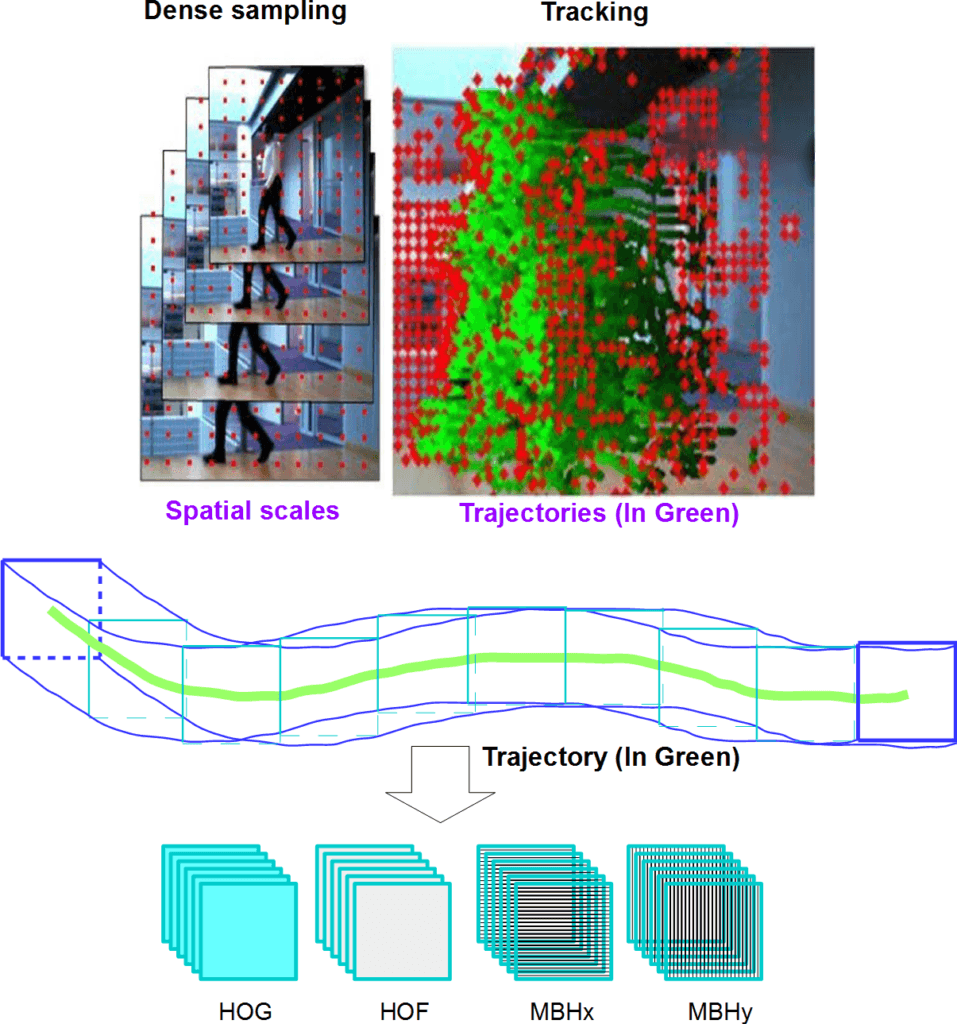
5. 特征匹配工作流(Feature Matching Workflow)
特征匹配是图像识别和物体定位的基础流程,主要包括以下几个步骤:
5.1. 检测兴趣点
- ✅ 在参考图像和目标图像中分别检测兴趣点。
- ✅ 通常只保留前几百个高质量的兴趣点,以减少计算量。

5.2. 提取特征向量
- ✅ 对每个兴趣点计算特征描述符,生成对应的特征向量。
- ✅ 特征向量通常是一个高维数组(如SIFT为128维)。

5.3. 匹配特征向量
- ✅ 使用相似性度量方法(如欧氏距离、余弦相似度)进行特征向量匹配。
- ✅ 常见方法:
- Brute-Force Matching(暴力匹配)
- FLANN(快速最近邻搜索库)
- Lowe’s Ratio Test(SIFT中常用)
⚠️ 匹配结果中通常包含一些误匹配(outliers),需进一步处理。

5.4. 估计几何变换
- ✅ 利用RANSAC等算法去除误匹配。
- ✅ 根据匹配点计算仿射变换或透视变换矩阵。
- ✅ 最终实现物体在图像中的定位。

✅ 如果目标物体不存在于图像中,则无法找到一致的几何变换。
6. 总结
本文我们详细讲解了:
- ✅ 特征描述符的概念及其在图像处理中的作用
- ✅ 特征向量与特征空间的关系
- ✅ 局部与全局描述符的区别及应用场景
- ✅ 特征匹配的基本流程与关键技术点
特征匹配是计算机视觉中的基础任务之一,掌握这些概念有助于深入理解图像识别、图像检索、图像拼接等相关应用。在实际项目中,合理选择特征描述符和匹配策略,往往能显著提升算法的准确率和鲁棒性。