1. Introduction
In this tutorial, we’ll discuss active learning in machine learning. We’ll explain what it is, why, how, and when to use it.
2. Problem Statement
Generally, when we want to train a supervised learning system, we use hundreds, if not thousands, of labeled instances.
Training these models is usually low-cost, as the labels are not hard to get. For example, a model that recommends music based on the songs we liked in an app already has a large dataset from which to learn.
However, what if we wanted to train a model for a task without enough labeled instances? For example, an article recommender without history to learn from will require the trainer or user to annotate thousands of documents and files, which is difficult, time-consuming, and expensive.
Hence, we need a better approach to training these systems: a method that allows systems to learn even with many unlabeled instances.
This framework is active learning, a subfield of machine learning that postulates query learning.
3. Active Learning
Active learning, also known as query learning, revolves around the idea that the learning system can choose the data to learn from. Rather than requiring that we label every instance before learning, the system can work with a few labeled instances and choose the unlabeled objects to query for labels as it learns.
So, this form of learning aims to solve the labeling problem. The system queries the oracle or annotator on unlabeled instances based on the information or responses to past queries. In a typical active-learning problem, we have a dataset with many unlabeled instances and a small subset of labeled data.
We approach these problems through a series of steps:
- Train the model on the labeled data
- Choose samples of instances from the distribution of unlabeled instances
- Use the model to evaluate the pool of unlabeled samples
- Based on the evaluation, choose the best sample
- Label this sample and add the instances to the labeled data
- Repeat steps 1–5 until a stopping criterion is satisfied
Here’s the flowchart:
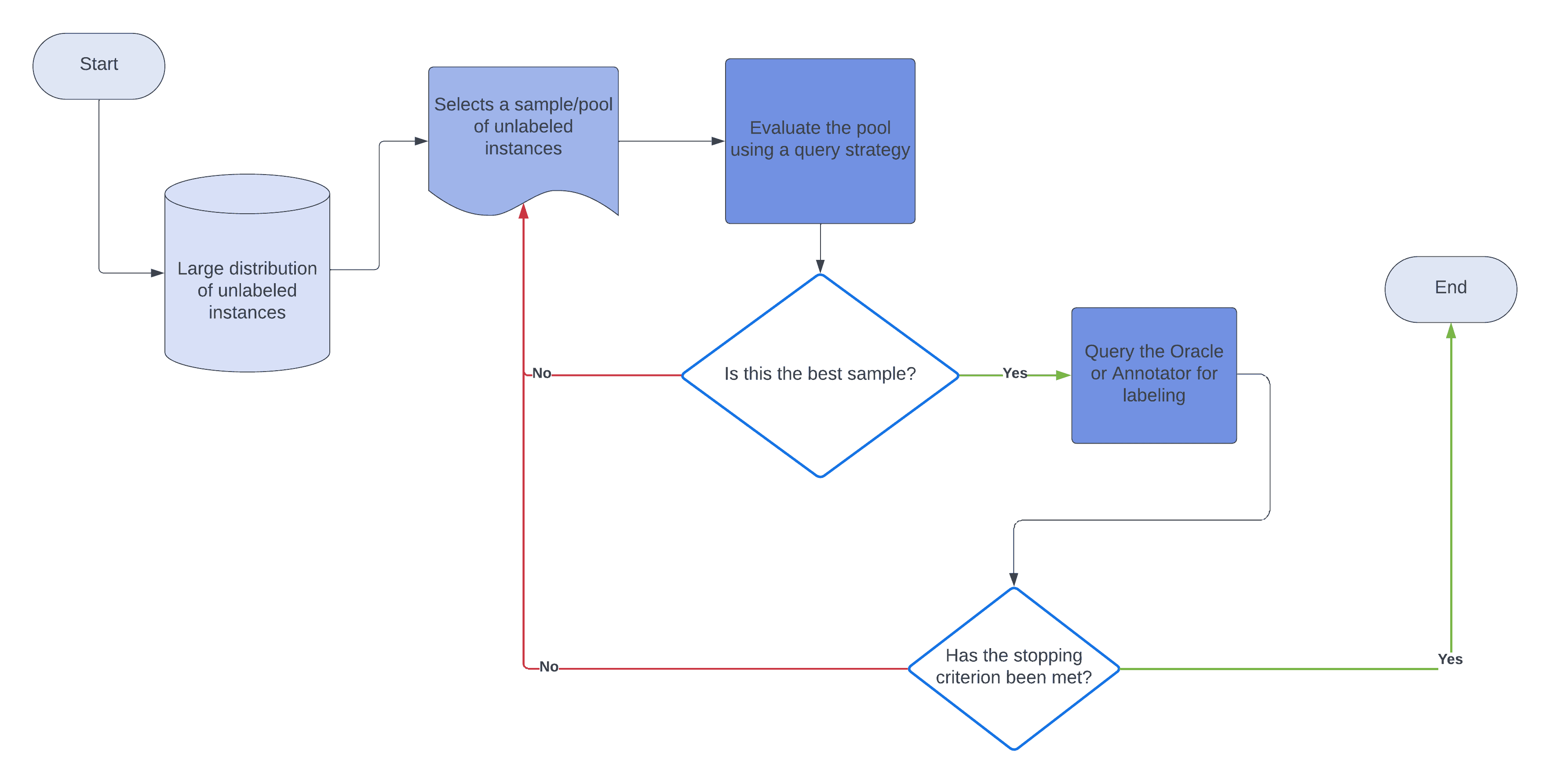
Coincidentally, these steps describe pool-based sampling, one of the many ways an active learner can query the oracle. We use a query strategy to choose the unlabeled objects for whose labels we’ll query the oracle. A query strategy is a rule set for the learner to decide for which instance to query the oracle and which instance to ignore.
Let’s check out three types of active learning.
4. Active Learning Types
We’ll cover three types: membership query synthesis, stream-based selective sampling, and pool-based sampling.
4.1. Membership Query Synthesis
Here, a learner can create a new, unlabeled instance and query the oracle for its label. This new instance can differ from the unlabeled objects in the dataset. After the annotator labels the object, the learner proceeds with learning:
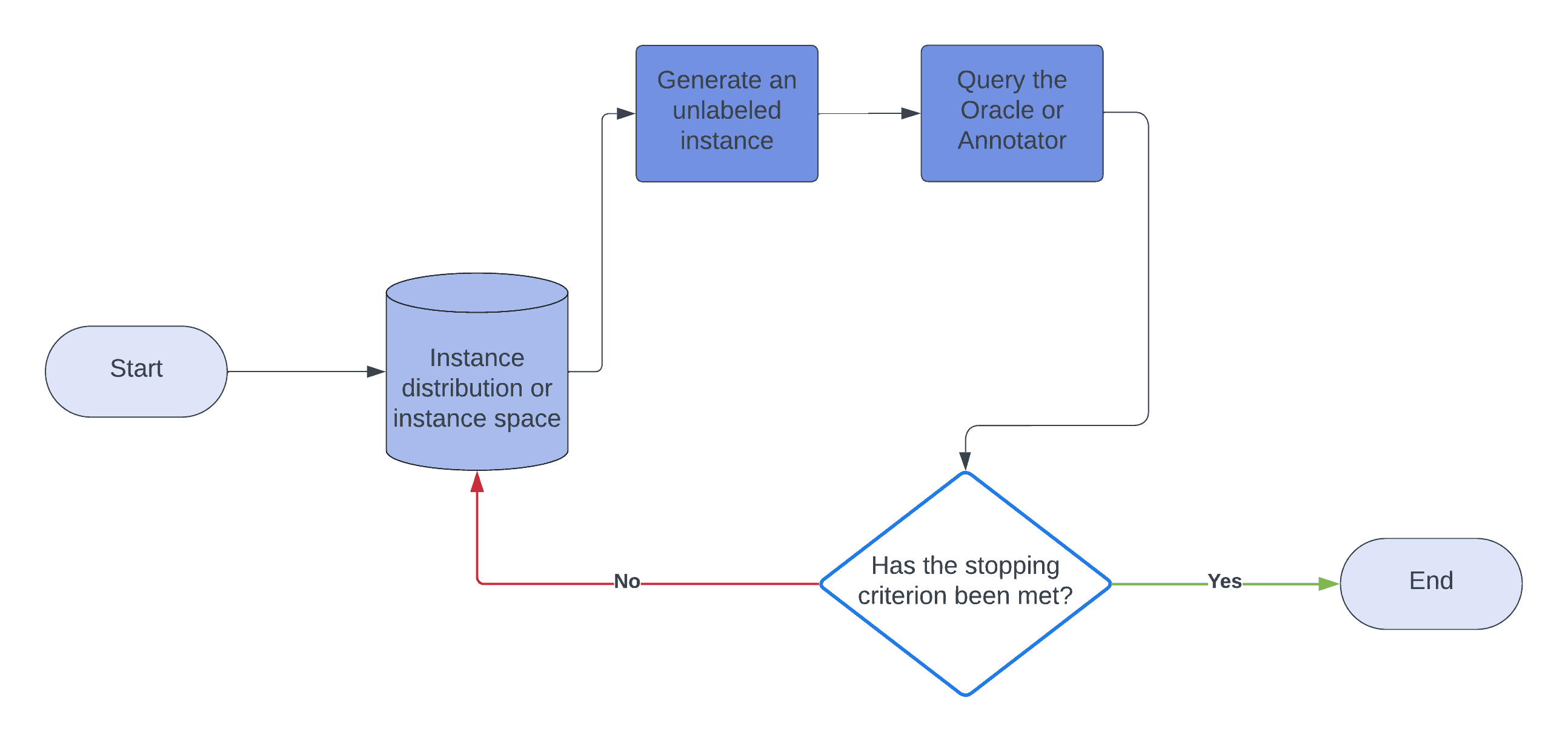
For example, let’s say we’re training our system to identify hieroglyphic characters and have a way to generate hieroglyphic shapes at random from a distribution. In this scenario, the learner looks at the sample of unlabeled characters and generates a similar character. Then, it queries the oracle to get the label of the generated character: whether it is a hieroglyph or not or which hieroglyph it represents.
A drawback is that the learner might generate ambiguous or incoherent characters. This possibility significantly impacts the efficiency of learning and leads to more errors.
The computational cost of generating and querying new instances, particularly more complex data types like images and videos, can be immense. As a result, active learning isn’t used often in practice.
4.2. Stream-Based Selective Sampling
In selective sampling, we choose a sample of unlabeled instances from the actual dataset or distribution and decide whether to query the oracle or ignore the instance:
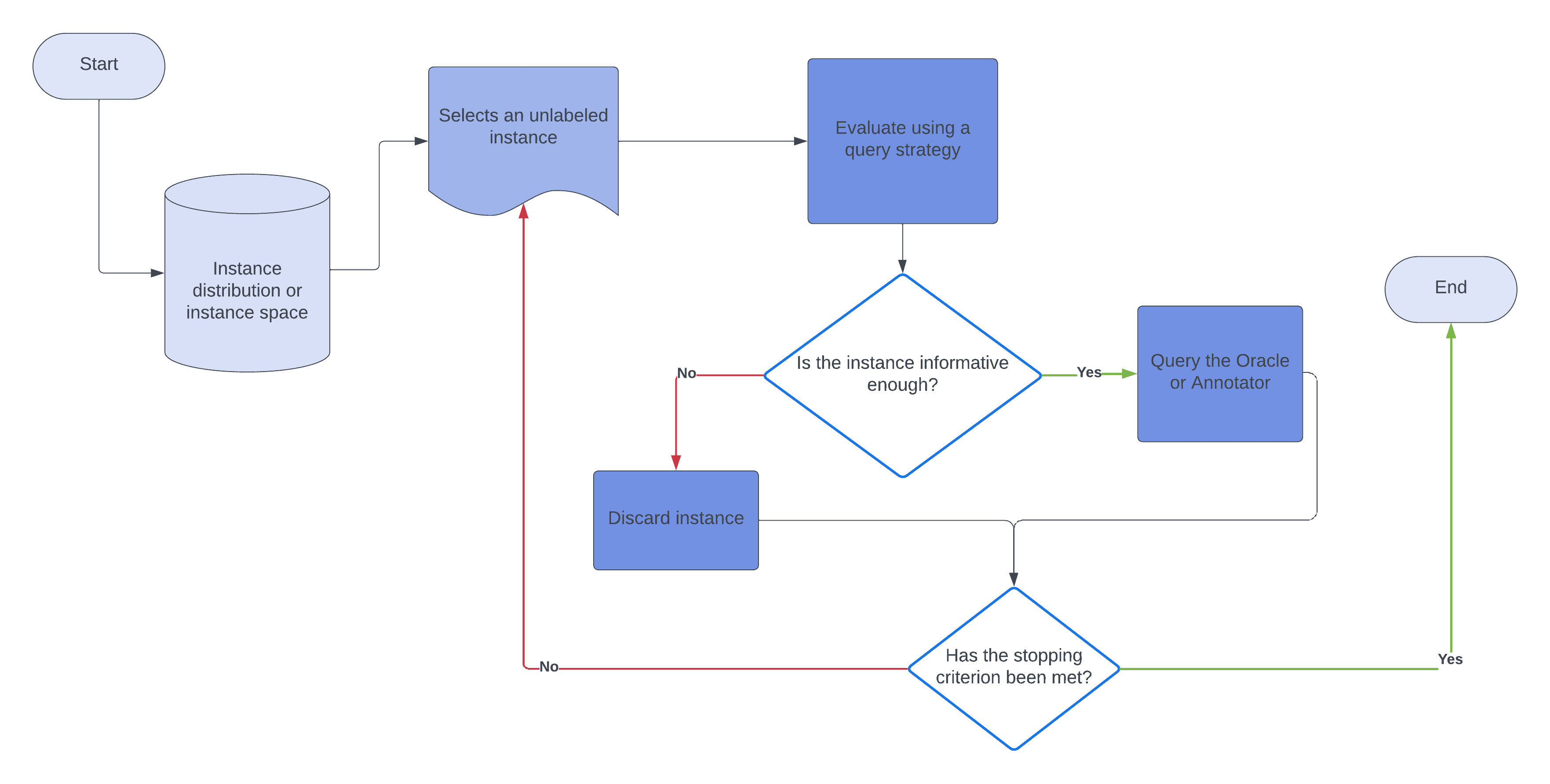
Generally, this method assumes that obtaining an unlabeled instance is free for the learner. The learner decides to query or discard based on its query strategy, which evaluates the instance and informs the learner what to do with it: query the annotator or discard it and move to the next instance.
We call this method stream-based sampling, as the learner draws one instance at a time from the dataset and decides before moving on to the next.
A typical example of the stream-based sampling method is in real-time data analysis or online analysis, where we analyze each incoming object before the next.
4.3. Pool-Based Sampling
In this method, t****he learner selects a pool (sample) of unlabeled objects and evaluates this pool using a query strategy to determine the most promising objects for which to query the oracle. This method works efficiently in large datasets of unlabeled objects, as we can sample finite subsets of unlabeled data.
An example is text classification with a large corpus of unstructured texts. Having human annotators analyze, sort, and label each text sequentially can be pretty expensive in these applications.
To mitigate this issue, we can use pool-based sampling to sample and evaluate a few text excerpts from the corpus. Then, the learner forwards the best excerpts to the oracle for labeling. The responses are then added to the labeled data. Afterward, we retrain the model.
While stream-based sampling picks instances and queries the oracle sequentially, the pool-based method evaluates a collection, choosing the most promising objects before querying the oracle.
5. Query Strategy Frameworks
For an active learner to work, it must accurately evaluate unlabeled instances’ informativeness.
A learner can use several frameworks: uncertainty sampling, query-by-committee, expected model change, expected error reduction, and variance reduction. We’ll discuss uncertainty sampling, which is the most commonly applied framework.
In uncertainty sampling, we use the probabilities of labels to make informed decisions about instances.
Generally, there are three methods to evaluate instances based on uncertainty sampling: least confidence, margin sampling, and entropy sampling.
5.1. Least-Confidence Method
In the least-confidence method, the learner considers the probabilities of each label for every instance in the dataset. For each instance, i****t finds the highest probability. Then, it queries the oracle for the label of the instance with the smallest “maximum” probability.
Let’s take an example:
Unlabeled Objects
Label A
Label B
Label C
Object 1
0.5
0.25
0.25
Object 2
0.1
0.8
0.1
The learner is 50% certain that Object 1 belongs to class A, and Object 2 is 80% likely to have the actual label B. Consequently, the learner queries the annotator for Object 1.
The major drawback of this approach is that the learner always chooses the most probable label, ignoring the probability distribution over other labels.
5.2. Margin Sampling
The learner considers the difference between the two most probable labels in margin sampling. Then, it chooses the instance with the smallest difference. This is useful in distributions where the margins are more ambiguous. For example:
Unlabeled Objects
Label A
Label B
Label C
Object 1
0.5
0.45
0.05
Object 2
0.3
0.4
0.3
In this case, the difference between the two most probable labels for Object 1 is 0.05, and for Object 2, it’s 0.1. So, it queries the oracle for the label of Object 1.
5.3. Entropy Sampling
In entropy sampling, the learner selects the instance with the largest entropy:
![[x^*_H = \mathrm{argmax}_x \left\{- \sum_i P(y_i|x)\log P(y_i|x)\right\}]](/wp-content/ql-cache/quicklatex.com-f8750f1cb3bcb2b6b3e8e500aa43e62b_l3.svg "Rendered by QuickLaTeX.com")
where  ranges across all possible labels of
ranges across all possible labels of  .
.
Unlike the previous strategies discussed, this method considers all the probable labels of the instance. Consequently, it is the most common uncertainty sampling strategy.
If we use this approach for the first table, we’ll see that Object 1 has an entropy of 0.452 and that the entropy of Object 2 is 0.277. Hence, the learner selects Object 1.
6. Application Areas
As a growing area of machine learning, more and more areas are adopting active learning to train supervised classifiers and predictors.
One of the most popular areas of its application is in training NLP models because of the high cost of labeling linguistic data (e.g., in speech recognition).
We also use active learning in computer vision and information extraction. Some researchers are also trying to integrate it with Generative Adversarial Networks and deep reinforcement learning.
7. Conclusion
In this article, we discussed active learning in machine learning and explained how it mitigates the bottlenecks identified in traditional training of supervised learning systems.
Active learning systems learn by starting with a small set of labeled data. During training, they query an oracle (e.g., a human annotator) to get the labels of some unlabeled instances to add to the labeled data.