1. 简介
在本篇文章中,我们将讨论如何在多分类(multi-class)分类任务中计算 F-1 Score。与二分类任务不同,多分类任务中每个类别都会单独计算一个 F-1 Score。
此外,我们还会介绍在 Python 中如何计算一个平均的 F-1 Score,以便在需要单一指标评估模型表现时使用。
2. F-1 Score 简介
F-1 Score 是评估分类器性能的一个常用指标,它是精确率(Precision)和召回率(Recall)的调和平均数。在二分类问题中,其公式为:
$$ \textrm{F-1 Score} = \frac{2 \times \textrm{Precision} \times \textrm{Recall}}{\textrm{Precision} + \textrm{Recall}} $$
F-1 Score 更适合以下场景:
✅ 数据类别分布不均衡
✅ 需要同时关注精确率和召回率(即 Type I 和 Type II 错误)
由于 F-1 Score 对数据分布敏感,因此它特别适用于不平衡数据集的评估。
3. 多分类 F-1 Score 的计算方式
在多分类任务中,F-1 Score 不是全局计算的,而是采用 One-vs-Rest(OvR)的方式为每个类别分别计算。这意味着我们实际上是在评估每个类别的表现,就像为每个类别训练了一个二分类器一样。
下面是一个多分类任务的混淆矩阵示例,总共 127 个样本:
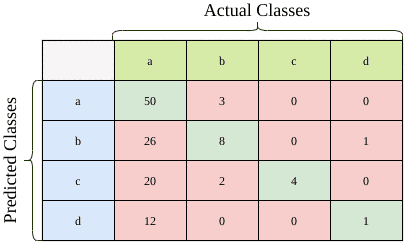
我们以 class a 为例来计算其 F-1 Score:
Precision(精确率): $$ \frac{TP}{TP + FP} = \frac{50}{53} = 0.943 $$
Recall(召回率): $$ \frac{TP}{TP + FN} = \frac{50}{108} = 0.463 $$
F-1 Score: $$ \frac{2 \times 0.943 \times 0.463}{0.943 + 0.463} = 0.621 $$
同理,我们也可以计算出其他类别的 Precision、Recall 和 F-1 Score:
| 类别 | Precision | Recall | F-1 Score |
|---|---|---|---|
| b | 0.228 | 0.615 | 0.333 |
| c | 0.154 | 1.000 | 0.267 |
| d | 0.077 | 0.500 | 0.133 |
4. Python 实现
在 Python 中,我们可以使用 scikit-learn 提供的 f1_score 函数来计算多分类任务的 F-1 Score。
4.1 每个类别的 F-1 Score
如果想查看每个类别的 F-1 Score,需要将 average 参数设为 None:
from sklearn.metrics import f1_score
f1_score(y_true, y_pred, average=None)
输出示例:
array([0.62111801, 0.33333333, 0.26666667, 0.13333333])
4.2 单一平均 F-1 Score
如果你希望得到一个整体的 F-1 Score 用于模型对比,可以使用以下三种平均方式:
✅ micro 平均
将所有类别的 TP、FP、FN 合并后统一计算:
f1_score(y_true, y_pred, average='micro')
输出:
0.49606299212598426
✅ macro 平均
将每个类别的 F-1 Score 平均,不考虑类别样本数量:
f1_score(y_true, y_pred, average='macro')
输出:
0.33861283643892337
⚠️ 该方法对样本少的类别影响较大。
✅ weighted 平均
按每个类别的样本数量加权平均 F-1 Score:
f1_score(y_true, y_pred, average='weighted')
输出:
0.5728142677817446
💡 选择建议:
- 如果你关心每个类别的表现,使用
None - 如果你希望得到一个整体评价,根据数据分布选择
micro、macro或weighted
5. 小结
- 多分类任务中,F-1 Score 是通过 One-vs-Rest 的方式为每个类别单独计算的。
- 如果需要一个整体的评价指标,可以使用
micro、macro或weighted平均方式。 - 在使用
scikit-learn的f1_score时,注意设置average参数以获得你想要的输出形式。
选择哪种方式取决于你的业务目标和数据分布。合理使用这些指标,有助于你更准确地评估模型性能。