1. 线性可分数据概述
线性可分(Linearly Separable)是分类任务中的一个重要概念。在二分类问题中,我们通常有两个类别:正类和负类。如果存在一个决策边界(decision boundary)能将正类样本和负类样本完全分开,我们就说这两个类别是可分的。
✅ 如果这个决策边界是输入特征的线性函数,那么我们称这两个类别是线性可分的。
线性可分性不仅适用于二维空间,在高维特征空间中同样适用。在实际应用中,如果数据集中的样本在特征空间中是线性可分的,我们就可以使用线性模型进行分类。
2. 线性可分数据的示例
2.1. 二维空间中的线性可分数据
在二维空间中,线性可分意味着我们可以用一条直线将正类样本和负类样本完全分开。只要存在这样的一条直线即可,不一定要唯一。
✅ 示意图如下:
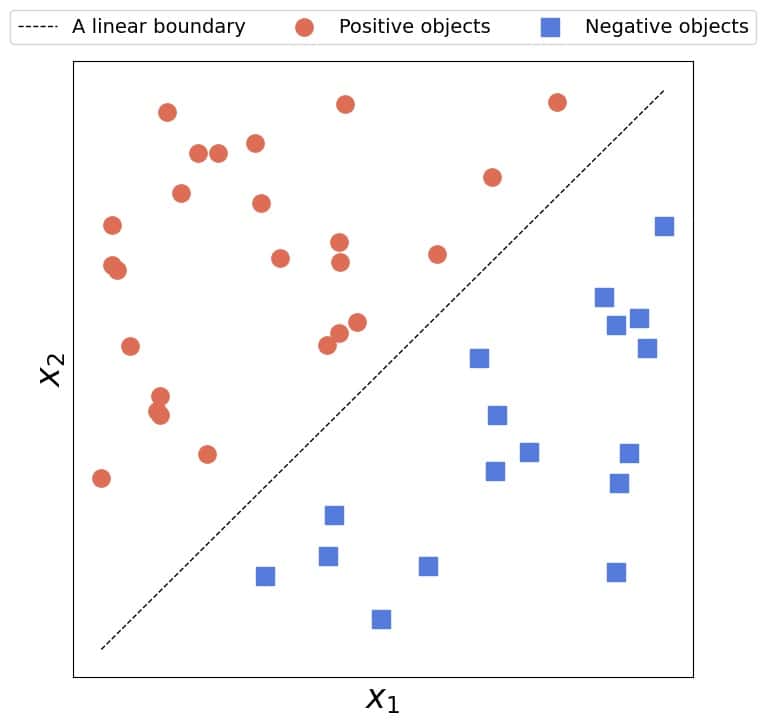
❌ 反之,如下图所示,无法用一条直线将两类样本完全分开,这就是线性不可分的情况:
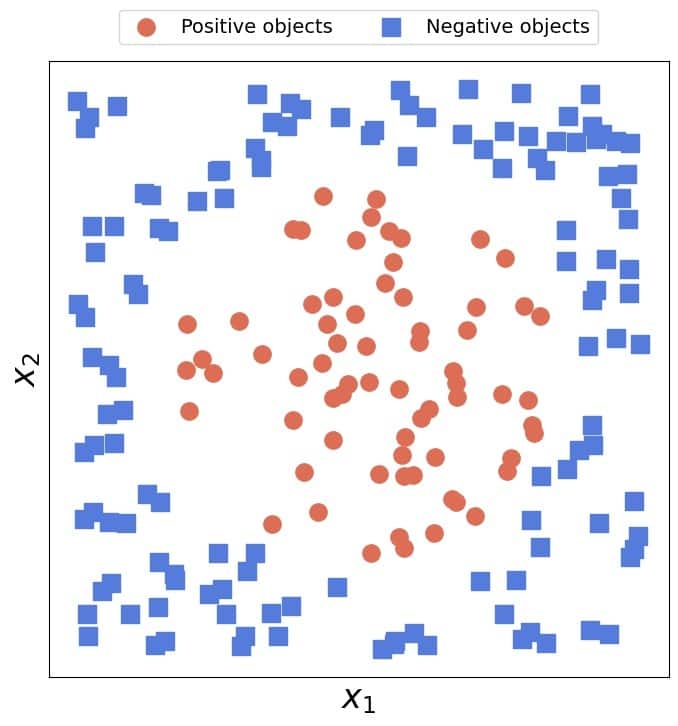
2.2. 高维空间中的线性可分数据
在 n 维空间中,线性可分的决策边界是一个超平面(Hyperplane)。其数学表达式为:
(1)
$$
\sum_{i=1}^{n} w_i x_i + b = \langle \mathbf{w}, \mathbf{x} \rangle + b = 0
$$
其中:
- $\mathbf{w} = [w_1, w_2, \dots, w_n]$ 是超平面的法向量
- $\mathbf{x} = [x_1, x_2, \dots, x_n]$ 是样本点
- $b$ 是偏置项(bias)
- $\langle \cdot, \cdot \rangle$ 表示向量的内积(点积)
这个公式定义了超平面的边界。样本点在该超平面的一侧属于正类,另一侧属于负类。
3. 线性模型的应用
如果数据是线性可分的,我们就可以使用线性模型来找到这个决策边界。例如:
- 线性支持向量机(SVM):寻找间隔最大的超平面
- 逻辑回归(Logistic Regression)
- 感知机(Perceptron)
3.1. 线性模型的优势
- 模型结构简单,易于解释:直接使用原始特征,便于理解模型决策过程。
- 可求解解析解:在优化过程中,可以使用解析方法(如梯度下降的闭式解)。
- 计算效率高:数值优化方法在线性问题中通常更高效。
⚠️ 但缺点也很明显:
如果数据本身是线性不可分的,这些优势将无法体现。
4. 映射到线性可分空间
当数据在原始特征空间中线性不可分时,一个常见策略是将其映射到一个新的特征空间,使得在新空间中数据变得线性可分。
4.1. 示例:二维圆形数据
考虑如下情况:正类样本集中在圆内,负类样本在圆外。此时,在二维空间中没有直线可以完全分开这两类。
我们可以通过以下映射方式将数据升维:
$$ \begin{bmatrix} x_1 \ x_2 \end{bmatrix} \mapsto \begin{bmatrix} x_1 \ x_2 \ x_1^2 + x_2^2 \end{bmatrix} $$
在这个新空间中,正类样本满足 $x_3 = x_1^2 + x_2^2 \leq b$,而负类样本 $x_3 > b$。这样,我们就可以使用线性SVM进行分类。
5. 映射策略的问题
虽然映射到高维空间可以解决线性不可分问题,但这种方法也存在一些挑战:
映射函数设计困难:对于复杂数据,找到合适的映射函数并不容易。
映射方式不唯一:例如,下面几种映射都可以使圆形数据线性可分:
$$ \begin{bmatrix} x_1 \ x_2 \end{bmatrix} \mapsto \begin{bmatrix} x_1 \ x_2 \ \sqrt{x_1^2 + x_2^2} \end{bmatrix},\quad \begin{bmatrix} x_1 \ x_2 \end{bmatrix} \mapsto \begin{bmatrix} \sqrt{x_1^2 + x_2^2} \end{bmatrix},\quad \begin{bmatrix} x_1 \ x_2 \end{bmatrix} \mapsto \begin{bmatrix} x_1^2 + x_2^2 \end{bmatrix} $$
效率问题:如果数据集很大或映射函数很复杂,预处理成本可能非常高。
无限维空间不可行:某些情况下,只有在无限维空间才能实现线性可分,这在实际中无法实现。
6. 核技巧(Kernel Trick)
为了解决上述问题,我们引入核技巧(Kernel Trick)。
核技巧的核心思想是:无需显式地将数据映射到高维空间,而是通过一个核函数(Kernel Function)来计算高维空间中的内积。
6.1. 核函数的定义
设映射函数为 $\Phi(\cdot)$,核函数 $k(\mathbf{x}, \mathbf{z})$ 满足:
$$ k(\mathbf{x}, \mathbf{z}) = \langle \Phi(\mathbf{x}), \Phi(\mathbf{z}) \rangle $$
这样,我们就可以在不显式进行特征映射的前提下,实现对高维空间中线性可分模型的训练。
6.2. 示例说明
例如,以下核函数对应于将二维特征映射到三维空间:
$$ k([x_1, x_2], [z_1, z_2]) = x_1^2 z_1^2 + 2 x_1 z_1 x_2 z_2 + x_2^2 z_2^2 $$
这个核函数等价于将样本映射为:
$$ [x_1^2, \sqrt{2 x_1 x_2}, x_2^2] $$
然后在该空间中使用线性模型进行分类。
✅ 核技巧的优势:
- 避免显式计算高维特征
- 可以处理无限维映射(如 RBF 核)
- 计算效率更高
7. 总结
- 线性可分是指存在一个线性决策边界可以将正类与负类样本完全分开。
- 如果数据在原始空间中线性不可分,可以通过特征映射将其转换到新的空间中实现线性可分。
- 显式映射存在设计复杂、效率低、维度爆炸等问题。
- 核技巧通过核函数隐式计算高维空间中的内积,避免了显式映射,是处理非线性问题的重要手段。
✅ 一句话总结:
核技巧让我们在不显式变换数据的前提下,也能在高维空间中找到线性决策边界,是处理非线性问题的强大工具。