1. Introduction
In this tutorial, we’ll explain the role of null hypotheses in standard statistical tests.
2. Statistical Tests
Let’s say we want to check how a new, recently proposed teaching method using generative AI affects students’ quiz results. To do this, we teach one class using the new AI-powered method and another using the good old presentation slides. To ensure a fair comparison, we choose the classes with equally talented students and instruct them to use the same textbook.
After scoring the quiz, we can be tempted to compute the mean scores in both classes to see which one is better. However, if we want to generalize the conclusions, we need to use statistics. The two classes we scored in this experiment are just two samples of the entire student population. So, the results might differ if the same experiment was conducted with different students. Statistical tests help us quantify this uncertainty and draw general conclusions with high confidence (if we conduct them correctly).
Usually, statistical tests have two hypotheses: the null and the alternative.
The null hypothesis is the hypothesis of “no effect,” i.e., the hypothesis opposite to the effect we want to test for. In contrast, the alternative hypothesis is the one positing the existence of the effect of interest.
3. Effects and Null Hypothesis
The effect depends on our research question. In our example, we want to check the efficacy of a new method, so we’re interested in the score difference. We must formulate the effect using quantifiable and measurable parameters to test it statistically.
Formally, let  be the parameter we want to test. That can be the mean difference between the scores we get using the two methods. However, we’re referring to the population means, not sample averages. For instance, the mean score we get in the class taught using the old method is a sample mean
be the parameter we want to test. That can be the mean difference between the scores we get using the two methods. However, we’re referring to the population means, not sample averages. For instance, the mean score we get in the class taught using the old method is a sample mean  , and the same goes for
, and the same goes for  . In contrast, the means we’d get if we could teach all the students using these methods are the population means
. In contrast, the means we’d get if we could teach all the students using these methods are the population means  and
and  .
.
So, if one method is better than the other, will be different from zero, and that’s our alternative hypothesis:
![[H_a: \theta = \mu_{old} - \mu_new} \neq 0]](/wp-content/ql-cache/quicklatex.com-7b0c92feb348bc4b7f25cc769fe7b4d8_l3.svg "Rendered by QuickLaTeX.com")
The opposite of  is that the mean scores are the same, i.e., that there is no effect, which is our null hypothesis
is that the mean scores are the same, i.e., that there is no effect, which is our null hypothesis  :
:
![[H_0: \theta = \mu_{old} - \mu_{new} = 0]](/wp-content/ql-cache/quicklatex.com-af72ab99f8cb150f3342103ee30ebcf7_l3.svg "Rendered by QuickLaTeX.com")
3.1. The Special Role of the Null Hypothesis
Rejecting in favor of is justifiable if our test is calibrated to reject a true null rarely.
Formally, let  be the statistic of the test to check if
be the statistic of the test to check if  holds and let higher values be less compatible with . The value of
holds and let higher values be less compatible with . The value of  corresponds to “no effect.” In our example with score difference, is 0.
corresponds to “no effect.” In our example with score difference, is 0.
Let  be the value of computed using our samples. The p-value of is:
be the value of computed using our samples. The p-value of is:
![[P(T \geq t^* \mid \theta = \theta_0)]](/wp-content/ql-cache/quicklatex.com-7c4cdace976a2dda4d1654e342dcb098_l3.svg "Rendered by QuickLaTeX.com")
Rejecting  if the
if the  -value is lower than
-value is lower than  (usually 1% or 5%) means that our long-term frequency of rejecting true nulls will not exceed . The caveat is that every statistical test has implicit or explicit assumptions about the tested parameter(s). If the real world substantially deviates from the assumptions, we’ll be unable to limit the error rate from above.
(usually 1% or 5%) means that our long-term frequency of rejecting true nulls will not exceed . The caveat is that every statistical test has implicit or explicit assumptions about the tested parameter(s). If the real world substantially deviates from the assumptions, we’ll be unable to limit the error rate from above.
The definition of the  -value reveals that we use the null hypothesis to derive the distribution of the test statistic. Most of the time, it’s easier to analytically derive the distribution if we assume that there is no effect (which usually corresponds to the tested parameter being equal to 0).
-value reveals that we use the null hypothesis to derive the distribution of the test statistic. Most of the time, it’s easier to analytically derive the distribution if we assume that there is no effect (which usually corresponds to the tested parameter being equal to 0).
3.2. The Nature of Scientific Proofs
The asymmetry between the null and alternative is evident in how we act depending on the test results. We’re usually interested in proving an effect. However, we behave as if that’s true only if the results are highly incompatible with the null hypothesis, as it isn’t sufficient that they are compatible with the alternative.
This means that the null acts as our default reality model, which is the one already in place or of lower risk. For instance, if we have a well-tested and very efficient teaching method, we don’t have much incentive to change it unless the new one is substantially better. Similarly, there’s more risk in erroneously recommending the use of an inefficient or harmful drug than not detecting the efficacy of an efficient one, so having a no-effect hypothesis as a default makes sense.
Therefore, we don’t need convincing to behave as if the null is true. It’s the job of the alternative hypothesis to convince us to act otherwise.
3.3. Effect Formulation
There’s more than one way to formulate the effect of interest. The choice of formulation implicitly defines assumptions about the populations. For instance, we defined the effect as a non-zero difference of means. However, the score distributions need to have the same shape for the difference in means to indicate the distributions are different:
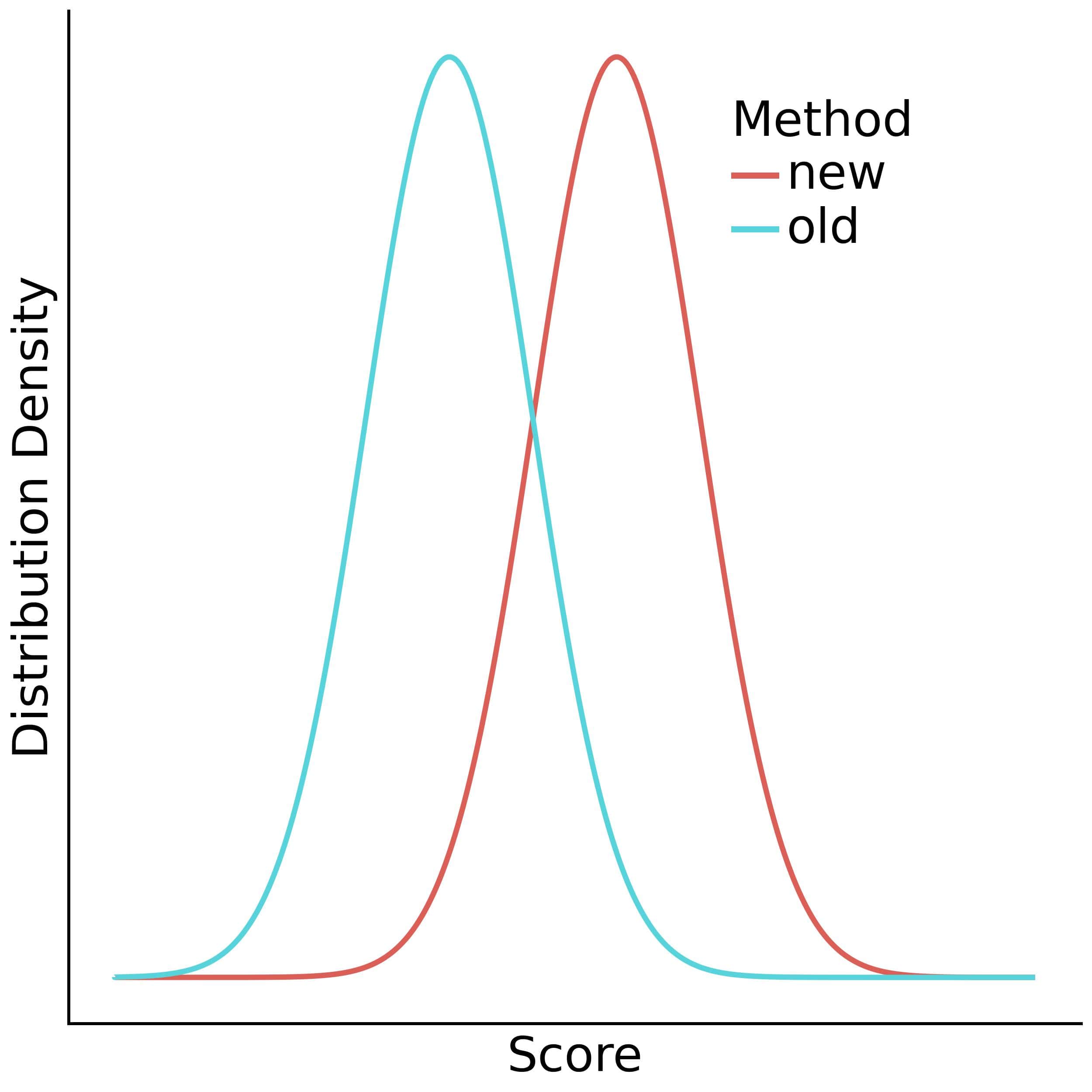
In this case, most values likely under the new method will be unlikely under the old one, and vice versa, because the distributions have the same shape. If they don’t, different means may have little to no practical significance. So, we always have to consider our implicit assumptions and formulate the effects so that they make sense.
4. Simple vs. Composite Null
Let be the parameter of interest. If the null specifies only one value  for
for  , we call it a simple null hypothesis. In that case, the alternative hypothesis is
, we call it a simple null hypothesis. In that case, the alternative hypothesis is  .
.
However, there are cases in which more than one value corresponds to the default or “no-effect” state. For example, we may be interested in knowing if the new teaching method is more efficient, not just if the new and old methods statistically differ. In that case, the effect we’re interested in finding out is  . That’s our alternative hypothesis. The opposite,
. That’s our alternative hypothesis. The opposite,  , corresponds to our null. It covers two ways in which the effect may not be there: the case in which two methods are equally efficient (
, corresponds to our null. It covers two ways in which the effect may not be there: the case in which two methods are equally efficient ( ) and the case in which the old one works better (
) and the case in which the old one works better ( ).
).
In general, if the null specifies multiple values for the tested parameter , we call it a composite null hypothesis:
![[H_0: \theta \in \Theta_0]](/wp-content/ql-cache/quicklatex.com-857f53c07f8c16afd3dd0973f9991fe1_l3.svg "Rendered by QuickLaTeX.com")
where  is the set of all the values for which, if took them, we say there is no effect.
is the set of all the values for which, if took them, we say there is no effect.
In our example,  is the composite null, so {kind=link}
4.1. The P-Value
Computing the -value for a composite null isn’t as straightforward as with a simple null. The reason is that the test statistic may follow different distributions under the values in , so there isn’t one, but many distributions to consider when calculating the -value.
To resolve this, we can use the maximum -value over all  :
:
![[\max_{\theta_0 \in \Theta_o} P(T \geq t^* \mid \theta = \theta_0)]](/wp-content/ql-cache/quicklatex.com-3a4771b3c212c10004533a945af9b5da_l3.svg "Rendered by QuickLaTeX.com")
assuming that higher values of the test statistic are less compatible with the null.
If we always use the maximum -value and reject the null if it’s lower than the threshold  , we can be sure that no matter the value of our parameter , the resulting error frequency will not be higher than .
, we can be sure that no matter the value of our parameter , the resulting error frequency will not be higher than .
In the most common tests, such as the Student t test, the maximum -value usually corresponds to a boundary of . In our teaching example, any difference  greater than 0 yields lower -values.
greater than 0 yields lower -values.
5. Conclusion
In this article, we explained the null hypothesis in statistics. It corresponds to the no-effect state of the world. We reject it in favor of the alternative hypothesis if the observed effect is unlikely under the null.