1. 概述
在本文中,我们将深入探讨基于梯度的优化算法。我们会先介绍优化问题的基本概念,接着讲解函数的导数定义及其在梯度计算中的作用。然后,我们会详细介绍最经典的梯度下降算法(Gradient Descent),并进一步将其扩展到多输入函数的优化场景。
2. 优化问题简介
优化的目标是找到一个输入值  ,使得目标函数
,使得目标函数  达到最小值或最大值。
达到最小值或最大值。
在实际中,我们通常只讨论最小化问题,因为最大化问题可以通过对函数取负值转化为最小化问题。也就是说:
- 最大化 ⇔ 最小化

我们通常将需要最小化的函数称为目标函数(objective function)或损失函数(loss function)。
示例:线性最小二乘问题
一个典型的优化问题例子是线性最小二乘(Linear Least Squares),其目标函数如下:

我们希望找到使该函数取得最小值的输入值:

3. 函数的导数
梯度是所有基于梯度优化算法的核心组成部分。我们先从单变量函数入手,其导数记为  或
或  。
。
几何上,导数表示函数在某一点的斜率,如下图所示:

换句话说,导数反映了输入值的微小变化对输出值的影响程度。
4. 梯度下降算法
梯度下降(Gradient Descent)是最经典、最常用的梯度优化算法之一,最早由数学家 Augustin-Louis Cauchy 提出。
其核心思想非常直观:
对于一个函数
,就可以使函数值减小。
示例说明
我们以一个简单的函数为例:

其导数为:

我们希望找到该函数的全局最小值,即  。
。
假设我们从一个随机的初始值  开始:
开始:
- 如果
 ,则
,则  ,说明函数在上升,应该向左移动(减小 )
,说明函数在上升,应该向左移动(减小 ) - 如果
 ,则
,则  ,说明函数在下降,应该向右移动(增大 )
,说明函数在下降,应该向右移动(增大 )
整个过程如下图所示:
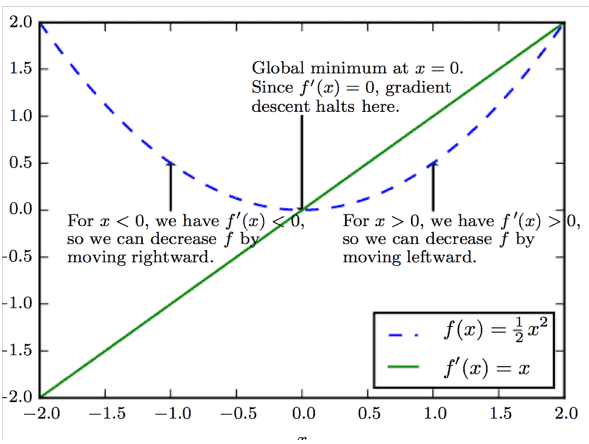
我们通过不断迭代更新  ,直到函数值的变化小于某个预设的小阈值,此时认为已找到最小值。
,直到函数值的变化小于某个预设的小阈值,此时认为已找到最小值。
5. 多输入优化
当函数有多个输入变量时(例如  ),我们需要使用偏导数(partial derivatives)来衡量函数在每个方向上的变化率。
),我们需要使用偏导数(partial derivatives)来衡量函数在每个方向上的变化率。
偏导数记为:

梯度是一个向量,包含所有偏导数:

梯度方向的意义
- 正梯度方向指向函数上升最快的方向
- 负梯度方向指向函数下降最快的方向
因此,在多输入场景下,我们仍然可以沿负梯度方向进行迭代更新,从而逐步逼近函数的最小值。
6. 总结
✅ 本文系统介绍了基于梯度的优化算法,包括:
- 优化问题的基本概念
- 函数导数的定义与作用
- 梯度下降算法的原理与示例
- 多输入场景下的梯度与优化方法
❌ 注意:梯度下降虽然简单有效,但在实际应用中可能面临收敛慢、陷入局部极小值等问题,后续可结合动量、学习率调整等策略改进。
⚠️ 提醒:梯度下降适用于可导函数,对于非光滑或非凸函数需谨慎使用。