1. 简介
路由(Routing)是现代网络通信的核心机制之一。在数据从源点传输到目标点的过程中,网络设备需要根据当前网络状态选择最优路径,这个过程就是路由。为了适应网络拓扑的动态变化,动态路由被广泛采用,并主要分为两类:距离向量(Distance Vector) 和 链路状态(Link State)。
本文将系统讲解这两种动态路由机制的基本原理、典型协议、优缺点及适用场景。最后会通过一张对比表总结它们的关键差异,帮助你更好地理解和选择适合的路由策略。
2. 路由概述
路由可以简单理解为:在网络中为数据包选择最佳传输路径的过程。
根据路由表的生成方式,可以分为三类:
- 静态路由(Static Routing):路由表由管理员手动配置,适用于结构稳定、变化少的小型网络。
- 默认路由(Default Routing):当没有匹配路由项时,使用默认路由转发数据。常用于连接 ISP 的边界路由器。
- 动态路由(Dynamic Routing):路由表由路由器在运行时自动构建和更新,能适应网络变化。
本文重点介绍动态路由中的两类核心实现方式:距离向量和链路状态。
3. 距离向量(Distance Vector)
距离向量路由基于局部信息进行路径选择,每个路由器只与其直接邻居交换路由信息。
核心思想:
- 每个路由器维护一个路由表(Route Table),记录到达每个目标网络的“距离”和下一跳(Next Hop)。
- “距离”通常以跳数(Hop Count)表示,也可以是延迟、带宽等指标。
- 每隔固定时间(如 RIP 中的 30 秒)与邻居交换路由信息,更新自己的路由表。
示例说明:
考虑如下拓扑:
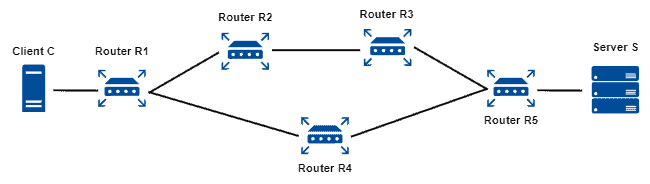
- 如果 R1 要将数据包发送到服务器 S:
- 经 R2 → R3 → R5:3 跳
- 经 R4 → R5:2 跳
✅ 所以 R1 会选择 R4 路径。
距离向量的缺点:
- 收敛速度慢:网络拓扑变化后,更新信息传播慢,可能导致路由环路。
- 广播更新:周期性广播路由表,带宽浪费严重。
- 计数到无穷(Count to Infinity)问题:当某条路径失效时,可能引发无限循环更新。
常见协议:
- RIP(Routing Information Protocol)
- 使用跳数作为距离指标
- 最大跳数为 15,超过则视为不可达
- 每 30 秒广播一次更新
4. 链路状态(Link State)
链路状态路由通过全局视角选择路径,每个路由器都拥有整个网络的拓扑图。
核心机制:
链路状态路由器维护三张表:
- 路由表(Route Table):最终的转发规则
- 邻居表(Adjacency Database):记录直连邻居
- 链路状态数据库(Link State Database):整个网络的拓扑结构
工作流程:
- 发现邻居:通过 Hello 报文建立邻接关系
- 测量链路成本:如延迟、带宽等
- 泛洪链路状态更新:当链路状态变化时,立即广播给全网
- 计算最短路径:使用 Dijkstra 算法构建最短路径树
示例说明:
考虑如下拓扑:
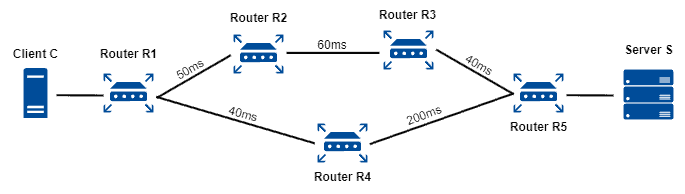
- 若以延迟为距离指标:
- R1 → R2 → R3 → R5:150ms
- R1 → R4 → R5:240ms
✅ 所以 R1 会选择 R2 路径。
链路状态的优点:
- 收敛速度快,适应性强
- 不易形成路由环路
- 可灵活选择路径优化指标(如带宽、延迟)
链路状态的缺点:
- 控制报文泛洪可能造成网络负载
- 初期同步过程复杂,资源消耗较大
- 需要良好的 TTL 控制机制防止环路
常见协议:
OSPF(Open Shortest Path First)
- 基于链路状态的内部网关协议
- 支持分区域设计(Area),适合大型网络
- 支持 VLSM、CIDR、认证等特性
IS-IS(Intermediate System to Intermediate System)
- 原为 ISO 标准设计,后被用于 IP 网络
- 工作在数据链路层(OSPF 在网络层)
- 不支持虚拟链路(Virtual Link)
| 特性 | OSPF | IS-IS |
|---|---|---|
| 协议层 | 网络层 | 数据链路层 |
| 区域划分 | 支持多区域 | 支持层级结构 |
| 路由器标识 | Router ID | System ID |
| 虚拟链路 | ✅ 支持 | ❌ 不支持 |
| 认证机制 | ✅ 支持 | ✅ 支持 |
5. 对比总结
| 类别 | 距离向量 | 链路状态 |
|---|---|---|
| 网络视角 | 邻居视角 | 全局拓扑 |
| 使用表格 | 路由表 | 路由表、邻居表、链路状态数据库 |
| 表更新方式 | 路由表交换 | 链路状态泛洪 |
| 更新频率 | 周期性 | 触发式 |
| 收敛速度 | 慢 | 快 |
| 带宽使用 | 中等 | 高 |
| 典型协议 | RIP | OSPF、IS-IS |
6. 总结
路由是网络通信的基础,而动态路由则是现代复杂网络中不可或缺的机制。
- 距离向量:适合小型网络,配置简单,但收敛慢、易环路
- 链路状态:适合大型网络,收敛快、稳定性好,但资源消耗大
在实际部署中,要根据网络规模、拓扑复杂度、设备性能等因素综合选择。没有绝对“最好”的协议,只有“最合适”的选择。
✅ 建议:
- 小型办公室或实验室:使用 RIP
- 企业骨干网或 ISP:使用 OSPF 或 IS-IS
⚠️ 踩坑提醒:
- RIP 的最大跳数限制为 15,超过即不可达
- OSPF 的邻居关系建立失败常见于网络类型不匹配、Hello/Dead 时间不一致
- IS-IS 的配置较为复杂,需注意层级划分
合理选择路由协议,是构建高效、稳定网络的第一步。