1. 引言
在自然语言处理(NLP)领域,文本相似度是一个活跃的研究方向,也是众多实际应用的基础。本文将介绍文本相似度的基本定义、类型,重点讲解语义相似度的概念、方法与应用场景。
2. 文本相似度
文本相似度用于衡量两个词语、短语或文档之间的接近程度。这种接近可以是词汇层面的,也可以是语义层面的。
- ✅ 语义相似度:强调含义的接近程度。
- ❌ 词汇相似度:关注词汇集合的重合度。
举个例子:
- “The dog bites the man”
- “The man bites the dog”
从词汇角度看,这两个句子几乎相同,但从语义角度看,含义完全不同。
2.1 实现方式
计算文本相似度通常包括以下几个步骤:
- 将文本转化为特征向量
- 选择合适的表示方式(如 TF-IDF)
- 使用相似度算法计算向量之间的距离或夹角
2.2 常见方法
- Jaccard 相似度
- 余弦相似度
- K-Means 聚类
- 潜在语义索引(LSI)
- 潜在狄利克雷分布(LDA)
- 结合词向量(如 Word2Vec)的算法
3. 语义相似度
语义相似度衡量的是两个文本在意义上的接近程度。通常以 0 到 1 的分数表示,1 表示含义几乎一致,0 表示毫无关联。
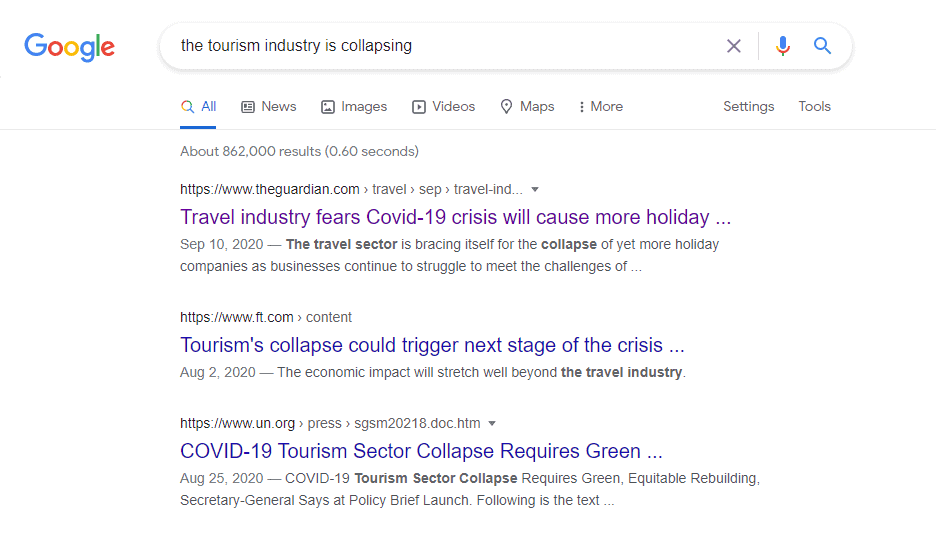
来看一个 Google 搜索的例子:
- 查询词:“The tourism industry is collapsing”
- 返回结果中出现了:“Travel industry fears Covid-19 crisis will cause more holiday companies to collapse”
虽然两个句子词汇差异大,但语义非常接近:
4. 语义相似度的类型
4.1 基于知识的相似度
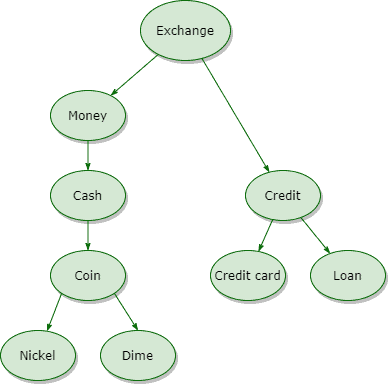
通过本体图谱(Ontology)中的节点表示概念,节点之间的边数越少,语义越接近。这种方法也被称为拓扑方法。
例如下图中,“coin” 与 “money” 更接近,而与 “credit card” 关系较远:
4.2 基于统计的相似度
通过语料库学习特征向量来计算语义相似度。常用技术包括:
- LSA(潜在语义分析)中的词频或 TF-IDF
- ESA(显式语义分析)中的维基百科概念权重
- PMI(点互信息)中的同义词关系
- HAL(语言类比超空间)中的共现词
这些方法常结合词向量(如 Word2Vec、GloVe)使用,以增强语义捕捉能力。
4.3 基于字符串的相似度
虽然不能单独用于语义相似度,但可以与其他方法结合使用,用于衡量特征向量之间的距离:
- 曼哈顿距离(Manhattan Distance)
- 欧几里得距离(Euclidean Distance)
欧几里得距离公式如下:
$$ d(x, y) = \sqrt{\sum_{i=1}^{n} (y_{i} - x_{i})^{2}} $$
其中 $ n $ 是特征向量的维度。
- 余弦相似度(Cosine Similarity)
余弦相似度公式如下:
$$ \text{Similarity}(A, B) = \frac{A \cdot B}{|A| \times |B|} = \frac{\sum_{i=1}^{n}A_{i} B_{i}}{\sqrt{\sum_{i=1}^{n}A_{i}^{2}}\sqrt{\sum_{i=1}^{n}B_{i}^{2}}} $$
4.4 基于语言模型的相似度
该方法于 2016 年提出,假设两个英文短语语法正确,主要步骤如下:
- 去除停用词
- 使用词性标注(POS)
- 构建解析树(parsing tree)
- 构建加权无向图
- 计算节点之间的最短路径作为相似度得分
5. 示例代码
目前已有多种成熟的库实现了上述算法,例如 Python 中的 Sematch,它基于知识图谱计算语义相似度。
以下代码展示了如何使用 sematch 计算“dog”和“cat”之间的语义相似度:
from sematch.semantic.similarity import WordNetSimilarity
wns = WordNetSimilarity()
similarity = wns.word_similarity('dog', 'cat', 'li')
print(similarity) # 输出 0.5
6. 应用场景
语义相似度在多个领域都有广泛应用:
6.1 自然语言处理(NLP)
- 情感分析
- 机器翻译
- 问答系统
- 聊天机器人
- 搜索引擎与信息检索
6.2 信息科学
- 生物医学:构建基因本体(Gene Ontology)依赖语义相似度方法。
- 地理信息:地理特征本体常使用拓扑与统计语义相似度方法。例如 OpenStreetMap 中使用的 OSM 语义网络,用于计算标签之间的语义相似度。
7. 小结
本文系统介绍了文本相似度的基本概念、分类与实现方法,重点讲解了语义相似度的定义、类型与典型应用场景。同时,我们也演示了如何使用 Python 中的 sematch 库进行语义相似度计算。
✅ 踩坑提示:语义相似度计算不是万能的,尤其在中文场景下,词向量与语义模型的质量直接影响结果准确性,建议结合实际业务进行调优。