1. 引言
在本教程中,我们将了解什么是无服务器架构(Serverless Architecture),以及它能为我们带来哪些好处。我们还将探讨一些流行的无服务器平台。在这个过程中,也会学习到这种架构风格的优缺点。
2. 无服务器架构背景
和业界的许多流行术语一样,要准确追踪“无服务器”一词的起源并不容易。但更重要的是理解它能为我们的应用带来的价值。虽然“无服务器”听起来有些奇怪,但当我们深入理解后,就会发现它的逻辑非常清晰。
2.1. 什么是无服务器架构?
通常,当我们开发一个应用时,我们需要服务器来部署和运行它。例如,当我们开发一个打包成 WAR 文件的 Java 应用时,我们需要像 Tomcat 这样的应用容器,运行在 Linux 机器上,可能还需要虚拟化支持。此外,还需要考虑高可用性、容错等基础设施配置:
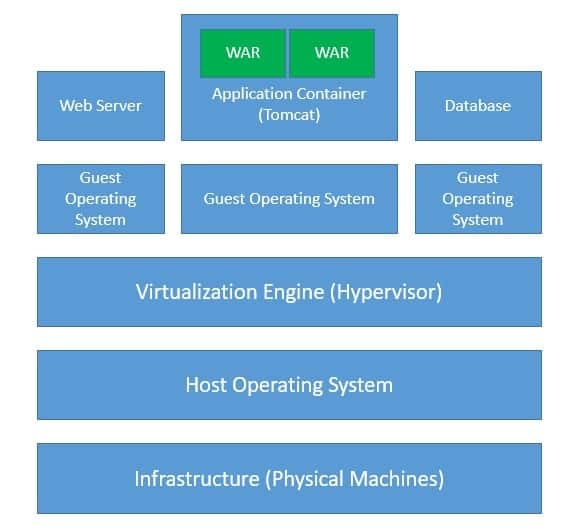
显然,这意味着在我们处理第一个请求之前,需要完成大量的准备工作。而且这还不是终点,之后还需要持续管理这套基础设施。如果我们能不用操心这些与业务开发无关的任务,岂不是很棒?
这就是无服务器架构的核心理念。无服务器架构是一种软件设计模式,我们将应用部署在第三方服务上,无需管理底层的硬件和软件栈。更进一步,我们也不必关心如何根据负载扩展基础设施。
2.2. 是 FaaS 还是 PaaS?
在业内,无服务器也常被称为函数即服务(Function-as-a-Service,FaaS)。FaaS 顾名思义,是一种云服务,允许我们以函数的形式构建、运行和管理应用,而无需管理基础设施。但这和平台即服务(Platform-as-a-Service,PaaS)有什么区别?
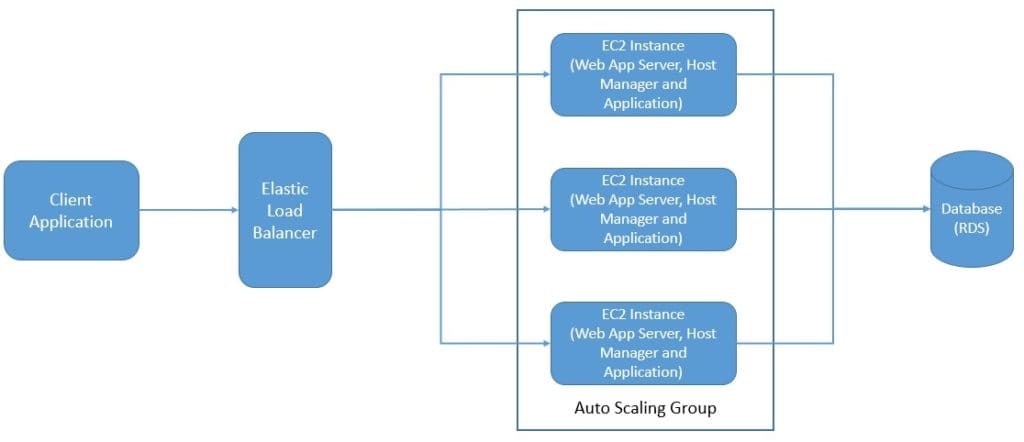
本质上两者确实有相似之处,但区别在于应用的部署单元。使用 PaaS,我们仍以传统方式开发应用,然后部署整个应用,比如 WAR 文件,并对整个应用进行扩容:
而在 FaaS 中,我们将应用拆分为多个独立、自治的函数。这样我们就可以将每个函数独立部署到 FaaS 服务上,并实现更精确的弹性伸缩:
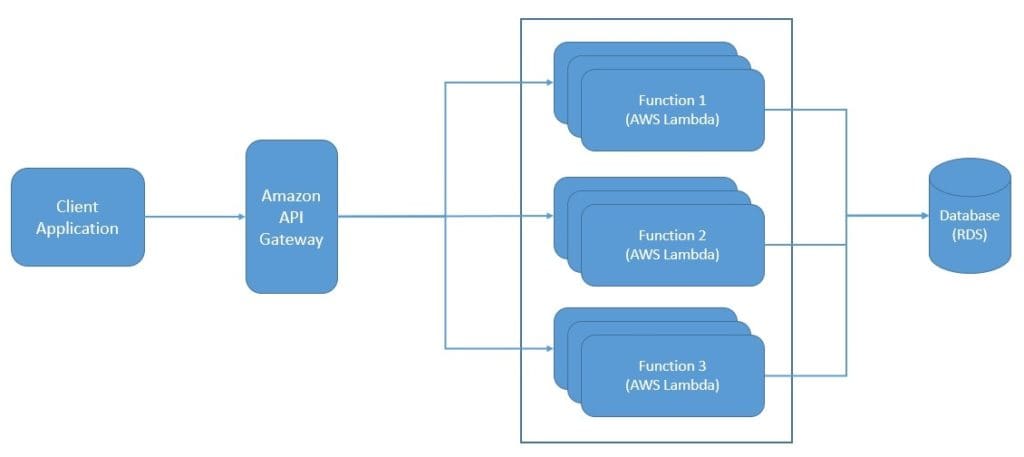
此外,使用 PaaS 时我们仍需手动或半自动地管理部分扩容逻辑,而 FaaS 则完全自动处理。FaaS 会在有请求时启动实例,任务完成后销毁实例,从而实现资源的最优利用。相比之下,像整个应用这样的大粒度部署单元很难做到这一点。
由于“无服务器”没有统一定义,我们不必纠结术语本身。核心思想是利用云服务带来的成本优化,即只在需要时使用计算资源,而不必关心其来源。这要求我们将应用拆分为更小、临时的部署单元。
3. 无服务器架构实践
虽然无服务器架构的理念非常吸引人,但如何具体实施并不直观。将应用拆分为多个自治函数说起来容易,做起来难。接下来我们通过一个简单的任务管理应用来理解无服务器架构的实际应用。
我们设想一个三层架构的任务管理应用:
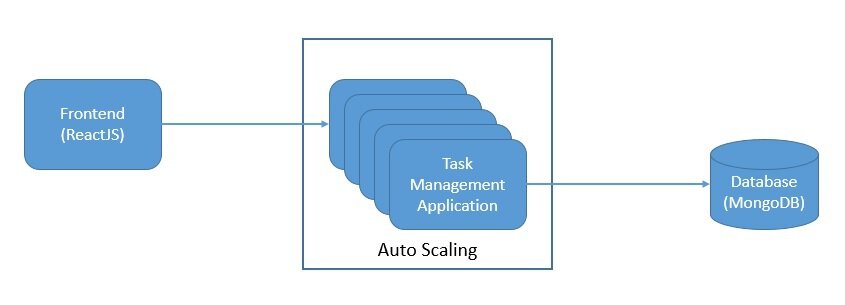
这个应用可以使用 ReactJS 做前端,Spring Boot 做后端,MongoDB 做数据库。我们可以将其部署在本地或云基础设施上。即使有自动扩容机制,我们也无法避免计算资源的浪费。
那么,用无服务器架构能解决这个问题吗?我们来看看。
我们需要将这个应用重新设计为一组独立的函数:
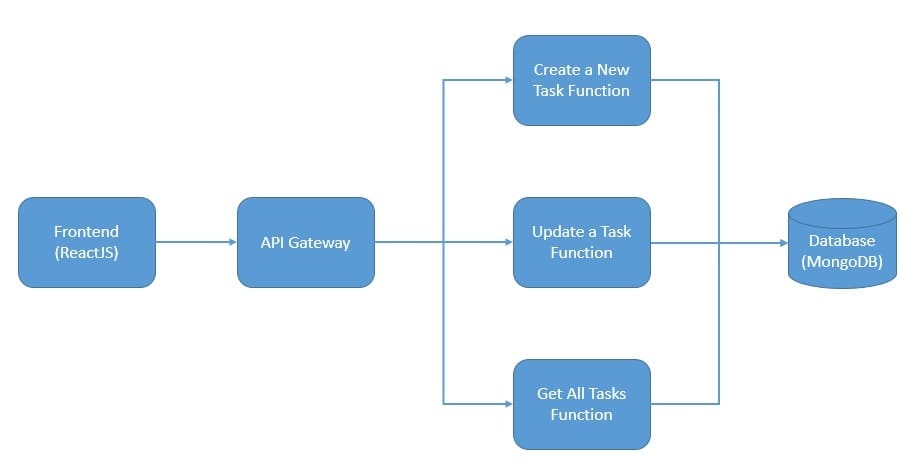
在这个架构中,我们将任务管理功能拆分为多个函数。虽然功能拆分看起来直观,但技术实现上也有一些挑战:
- 需要依赖 FaaS 提供商提供的 SDK 和 API 进行开发;
- 传统调试、监控和管理工具可能不再适用;
- 但我们可以利用 FaaS 平台的能力,按需创建和管理函数实例。
4. 流行的无服务器平台
正如前面所说,无服务器架构的一大优势是将基础设施管理交给第三方。因此,我们能否构建无服务器应用,很大程度上取决于可用服务的质量。目前主流云厂商都提供了丰富的无服务器服务。
4.1. AWS 上的无服务器服务
AWS 上最重要的无服务器服务是 Lambda。Lambda 是一种无服务器计算服务,允许我们运行代码而无需配置或管理服务器。支持多种语言,包括 Node.js、Python、Go 和 Java。我们只需将代码打包为 ZIP 文件或容器镜像上传即可。
Lambda 可以根据流量自动扩展,AWS 还提供了一系列配套服务:
- Amazon EventBridge:用于构建事件驱动应用;
- Amazon API Gateway:用于创建、发布、维护、监控和保护 API;
- Amazon S3:用于存储可扩展、高可用的数据。
4.2. GCP 上的无服务器服务
Google Cloud Platform(GCP)的核心无服务器产品是 Cloud Functions。它是一个可扩展、按使用计费的 FaaS 服务,无需管理服务器即可运行代码,并能根据负载自动扩展。它还提供内置的监控、日志和调试功能,以及基于角色和函数级别的安全机制。
GCP 还提供 App Engine,适合更复杂的场景。Cloud Functions 更适合简单、独立、事件驱动的函数,而 App Engine 更适合组合多个功能的复杂应用。此外,GCP 还有 Cloud Run,可用于部署打包为容器的无服务器应用。
4.3. Azure 上的无服务器服务
Microsoft Azure 提供了 Azure Functions,这是一个事件驱动的无服务器计算平台。它还支持 Durable Functions 扩展,用于解决复杂的编排问题,比如有状态协调。通过触发器和绑定机制,我们可以轻松连接其他服务,而无需硬编码。此外,Azure Functions 还支持在 Kubernetes 上运行。
对于更复杂的场景,Azure 提供了 App Service,它是一个完全托管的无服务器平台,可用于构建、部署和扩展 Web 应用。支持 Node.js、Java、Python 等语言,并能满足企业级性能、安全和合规需求。
5. Kubernetes 上的无服务器架构
Kubernetes 是一个开源的容器编排系统,用于自动化部署、扩展和管理容器化工作负载。在其之上还可以部署服务网格(如 Istio),用于解决服务间通信等常见问题。
在 Kubernetes 上构建无服务器架构是一个自然的选择,它能带来诸多好处:
- 减少对厂商服务的依赖;
- 提供统一的无服务器开发框架。
5.1. Knative
Knative 是一个基于 Kubernetes 的平台,用于部署和管理无服务器工作负载。它能帮助我们快速构建可扩展、安全、无状态的服务。它提供了高级抽象 API 来应对常见应用场景,并支持自定义组件用于日志、监控、网络和服务网格。
Knative 主要由两个组件组成:
- Serving:用于在 Kubernetes 上运行无服务器容器,处理网络、自动扩缩容和版本控制;
- Eventing:提供事件订阅、传递和管理基础设施,支持构建事件驱动的无服务器应用。
5.2. Kyma
Kyma 提供了一个平台,用于在 Kubernetes 上通过无服务器函数和微服务扩展应用。它整合了多个云原生项目,简化了扩展应用的创建和管理流程。其核心理念是通过事件驱动的方式实现应用的扩展和回调。
Kyma 提供了已配置、监控和安全加固的 Kubernetes 集群。此外,它还集成了多个开源项目用于身份认证、日志、事件、追踪等功能。它包含多个关键模块,涵盖无服务器计算、事件处理、可观测性、API 暴露、应用连接、服务网格和用户界面。
6. 无服务器架构的局限性
到目前为止,我们已经看到无服务器架构能带来资源使用的最优化,进而降低成本。此外,用户无需管理基础设施,也降低了运营成本。再加上平台的高可扩展性,能显著缩短产品上市时间,提升用户体验。
然而,无服务器架构并不适合所有场景,我们在选择前应权衡其优缺点。只有全面了解其局限性,才能做出合理的技术选型。
6.1. 平台限制
最大的问题是厂商控制。当我们使用无服务器架构设计或重构应用时,我们主动放弃了对系统很多方面的控制权,比如可用语言、版本升级等。虽然厂商支持的范围在不断扩大,但选择仍然有限。
另一个重要问题是厂商锁定。不同厂商的无服务器服务差异很大,一旦使用,切换平台的成本可能很高。因为我们需要依赖多个基础设施服务,迁移并不容易。
安全性也是一个需要关注的方面。传统开发中我们对安全有更多控制权,但在使用无服务器服务后,安全实现更多依赖厂商机制,这会增加攻击面和复杂性。
6.2. 应用限制
还有一些限制与我们如何开发应用有关:
- 冷启动延迟:当无服务器函数长时间未使用时会被缩容为零,首次调用时可能产生显著延迟。这对偶尔触发的 JVM 应用尤其明显;
- 集成测试困难:虽然单元测试变得简单,但集成测试却变得复杂,因为整个应用依赖多个云服务。
那么,无服务器架构适合哪些场景?
✅ 适合:
- 异步、并发任务;
- 需求不频繁或波动大;
- 无状态、临时性任务;
- 对弹性要求高。
❌ 不适合:
- 长时间运行的任务;
- 对延迟敏感的实时服务;
- 重度依赖本地状态的应用;
- 对基础设施有强控制需求的场景。
7. 总结
本教程我们了解了无服务器架构的基本概念,探讨了如何将传统应用重构为无服务器架构,并介绍了主流的无服务器平台。最后,我们也分析了无服务器架构的局限性。
无服务器架构不是银弹,但在合适场景下,它能显著提升资源利用率、降低运维成本,并加快产品迭代速度。选择是否采用无服务器架构,应基于具体业务需求和技术可行性进行综合评估。