1. 概述
本文将深入讲解 空间金字塔池化(Spatial Pyramid Pooling, SPP) 技术。我们会先回顾一下卷积神经网络(CNN)在视觉识别中的应用,接着引出传统CNN对输入图像尺寸的限制问题,最后详细介绍SPP层如何解决这一限制,以及它的实现原理和优势。
2. CNN在视觉识别中的应用
卷积神经网络(CNN)在计算机视觉和深度学习领域取得了革命性进展,尤其在图像分类、目标检测等任务中表现出色。CNN之所以能取得如此优异的效果,主要归功于它能自动学习具有判别能力的特征,并在面对新数据时具备良好的泛化能力。
其中,目标识别是受益最大的应用场景之一。目标识别包括两个核心任务:
- 图像分类:判断图像中包含什么对象
- 目标定位:指出对象在图像中的位置
关于目标识别的更多细节和常用评估指标,可以参考我们之前的文章。
3. 输入尺寸限制问题
尽管CNN性能强大,但存在一个显著的限制:传统CNN要求输入图像必须是固定尺寸。如果输入图像尺寸不一致,通常需要通过裁剪(crop)或拉伸(warp)的方式进行尺寸调整。
如下图所示,这是两种常见的调整方式:

但这样做会带来一些问题:
✅ 裁剪可能丢失关键信息,比如图中汽车的前后部分被裁掉,这会影响识别准确性
✅ 拉伸会导致图像内容变形,影响模型对物体形状的判断
因此,这种处理方式往往会降低模型的整体性能,尤其是在面对复杂场景时。
4. 空间金字塔池化(SPP)的引入
为了解决这个问题,我们迫切需要一种方法,让CNN可以处理任意尺寸的输入图像。那问题来了:
为什么传统CNN要求固定尺寸输入?
答案在于全连接层(Fully Connected Layer)。我们知道CNN通常由卷积层(Conv Layer)和全连接层组成。卷积层本身是支持任意尺寸输入的,因为它是通过滑动窗口进行操作的。真正限制输入尺寸的是全连接层。
为了解决这个限制,SPP层被提出并插入在最后一个卷积层和第一个全连接层之间。
✅ SPP层的作用
SPP层的核心功能是:将卷积层输出的任意尺寸特征图转换为固定长度的输出向量,以便后续全连接层可以正常工作。
如下图所示,SPP层的工作原理如下:
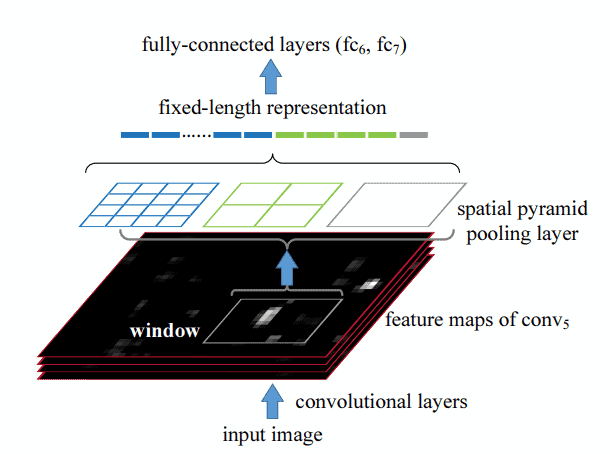
SPP层接收一组大小任意的 d 通道特征图作为输入,然后在不同尺度的局部空间区域内进行最大池化操作。这些池化区域(bins)的数量和大小是固定的,因此无论输入尺寸如何变化,输出都是固定长度的向量。
✅ SPP的池化结构
SPP层通常包含多个不同尺度的池化层:
- 1个bin(右):对整个特征图做最大池化,输出一个
d维特征 - 4个bins(中):将特征图划分为4个区域,分别池化,输出
4×d维特征 - 16个bins(左):将特征图划分为16个区域,分别池化,输出
16×d维特征
最终输出的特征维度为 (16 + 4 + 1) × d = 21d。
所有池化操作均使用最大池化(max pooling),这样可以保留特征图中的关键信息。
5. 总结
SPP层的提出,有效解决了传统CNN对输入图像尺寸的限制问题。它通过在卷积层和全连接层之间引入一个灵活的池化机制,使得模型可以处理任意尺寸的图像输入,同时又不会牺牲模型性能。
这在目标检测、图像分类等任务中尤为重要,尤其是在处理真实场景图像时,输入尺寸往往不统一。SPP的引入,为后续更高级的模型(如YOLOv3、Fast R-CNN等)提供了重要的技术基础。