1. 简介
本文将介绍立体视觉(Stereo Vision),这是一种使用两个或多个摄像头从不同视角拍摄图像,从而重建完整视场三维信息的技术。它广泛应用于高级驾驶辅助系统(ADAS)、机器人导航、增强现实(AR)等领域。
2. 什么是立体(3D)视觉?
立体视觉是指从二维图像中提取三维信息的技术。 它通过对比多个视角的图像数据,结合物体在不同视图中的相对位置,来还原场景的深度信息。
人类视觉系统就是典型的立体视觉系统。我们双眼分别看到的二维图像,在大脑中融合后产生深度感知能力,这种能力被称为立体视(Stereopsis):
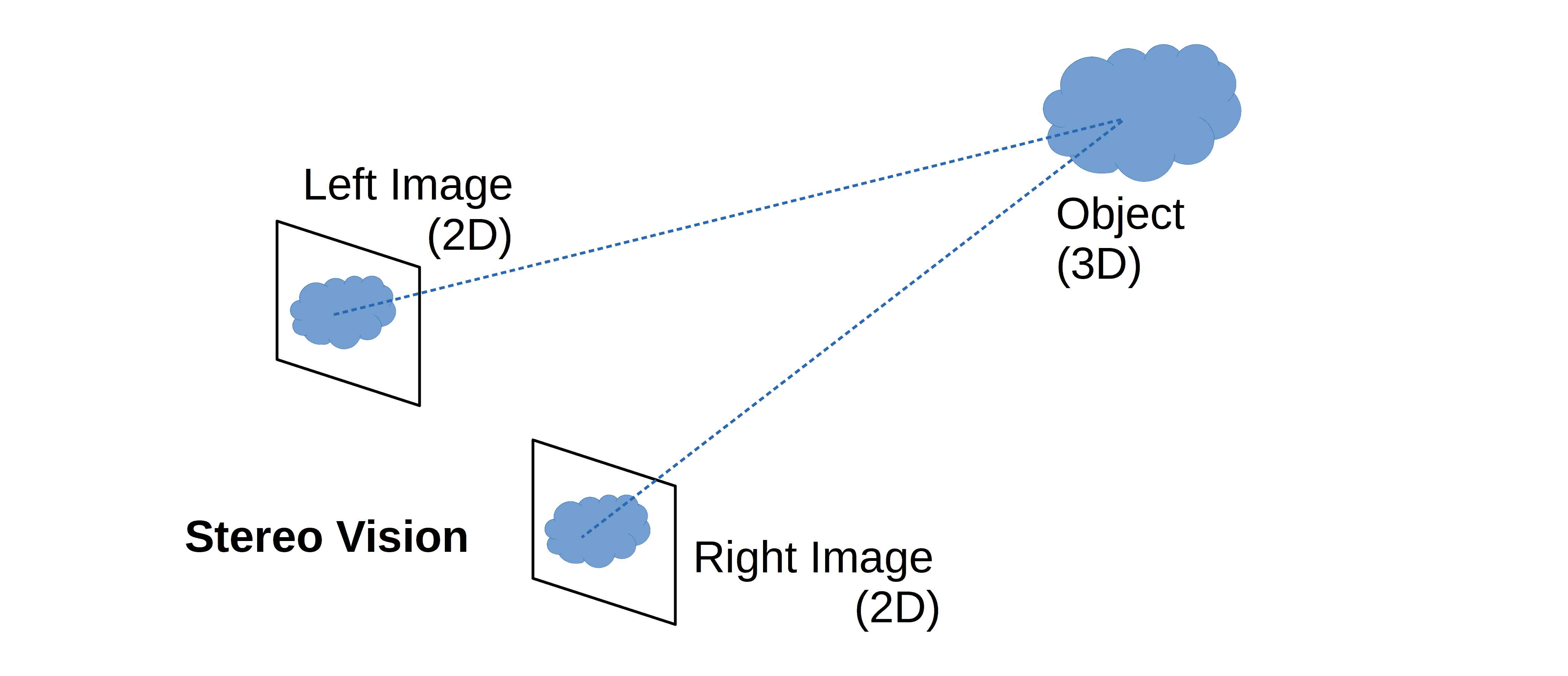
虽然每只眼睛接收到的只是二维图像,但通过双眼图像的差异,大脑可以感知深度,这种能力就是立体视觉的核心。
3. 深度感知原理
假设我们有两个摄像头,分别从左右两侧拍摄同一场景。设 S 为场景中某个真实三维空间中的点:
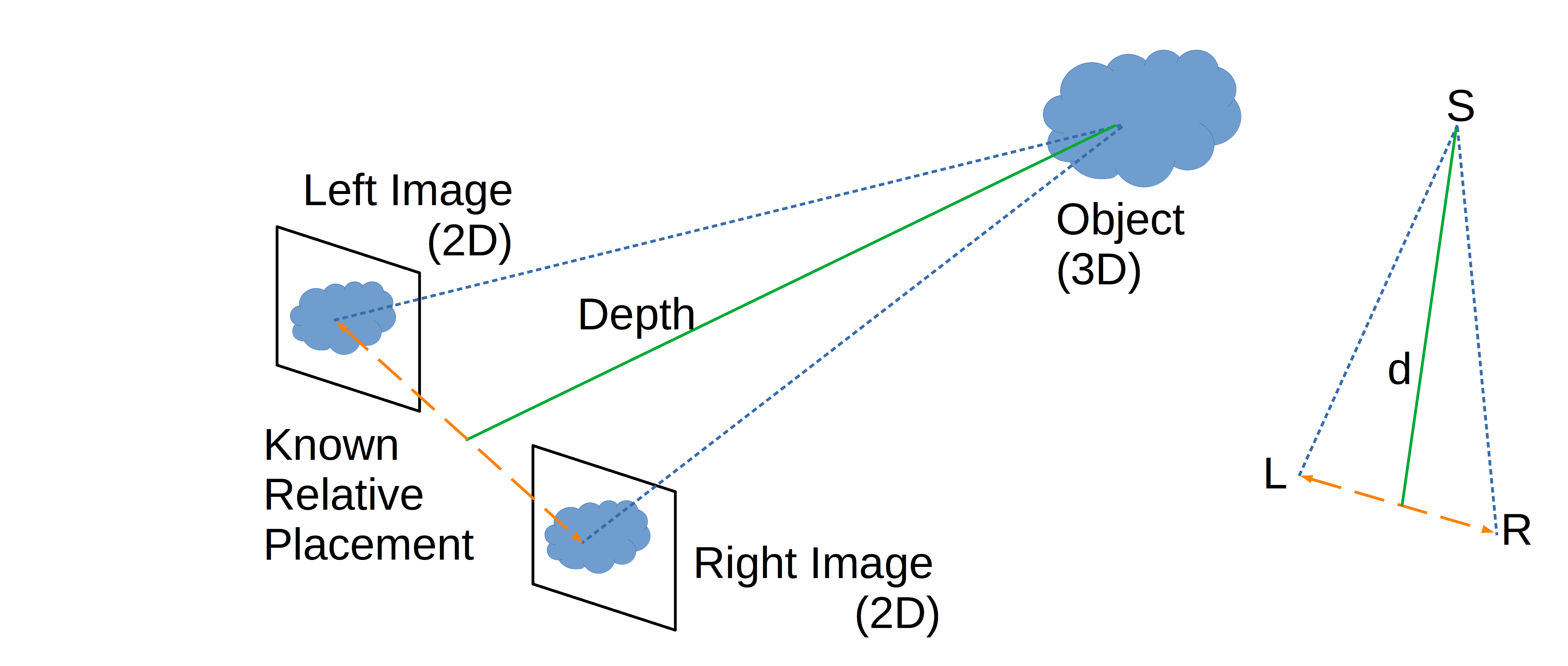
要确定 S 在三维空间中的深度,我们需要找到它在左右图像中的对应像素 L 和 R。已知两个摄像头之间的相对位置关系,系统可以通过三角测量法估算出深度 d。
这种机制与人脑的深度感知机制一致,我们称之为“立体视”。
4. 计算机如何实现立体视觉
要从二维图像中重建三维信息,首先需要估算每个像素点的深度。然后通过这些深度信息,构建出一张深度图(Depth Map):
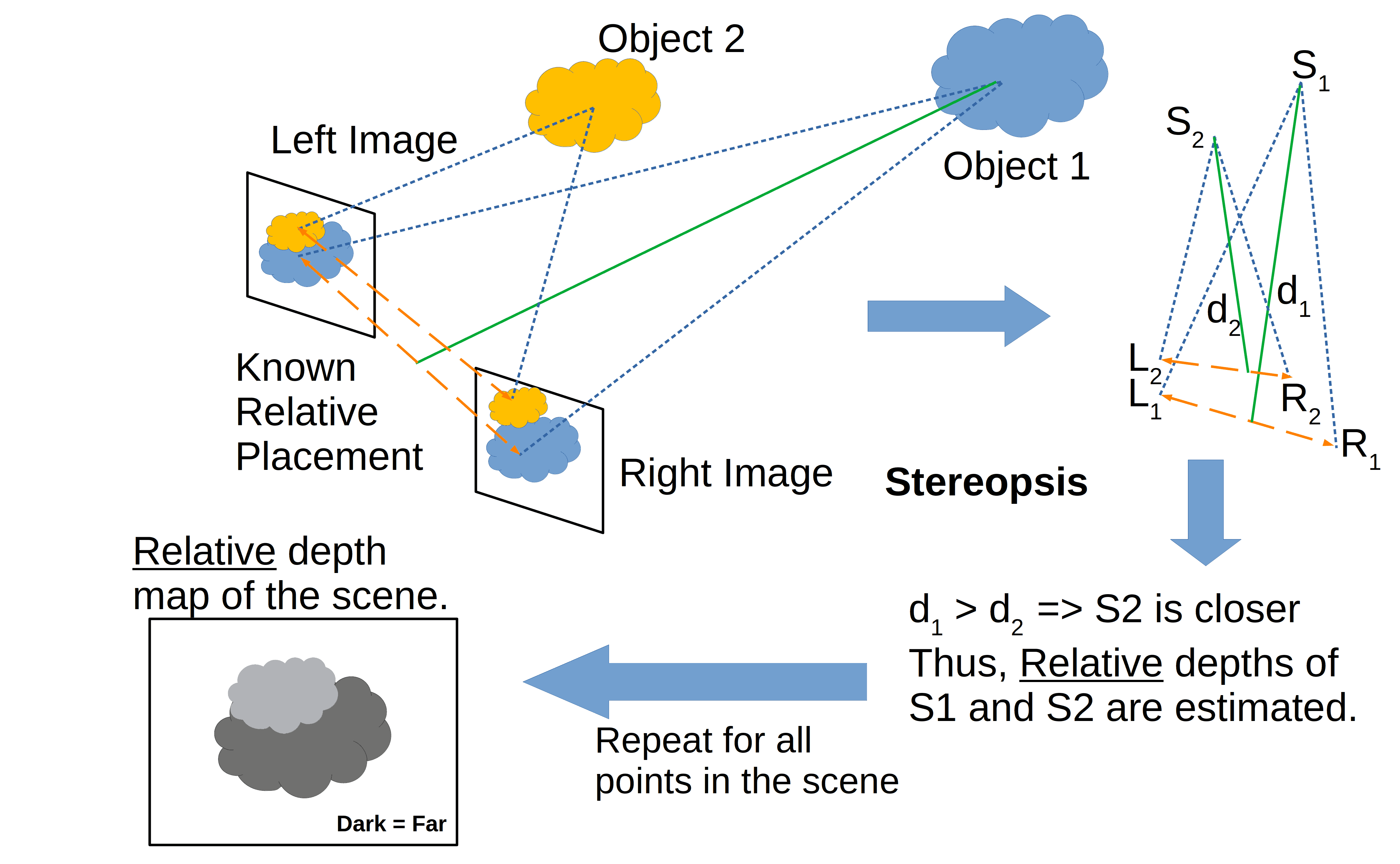
深度图是一种图像或图像通道,表示场景中物体表面与观察点之间的距离。 它是三维计算机图形学和计算机视觉中最常见的深度表示方式。上图左下角即为一个深度图示例。
5. 立体视觉的几何基础
极几何(Epipolar Geometry)是立体视觉的几何基础。 它描述了三维空间点与其在二维图像中投影之间的几何关系。极几何模型基于针孔相机模型(Pinhole Camera Model)建立,适用于大多数普通相机的建模。
当一个三维物体被投影到二维图像平面上时,会丢失深度信息。而立体图像之间的差异(Disparity)正是恢复深度的关键。
差异(Disparity)是指同一物体在左右图像中投影位置的水平偏移量。 当你闭上一只眼再迅速睁开另一只眼时,近处物体看起来移动较多,远处物体几乎不动,这种现象就是“差异”。
5.1 方向向量
在极几何中,方向向量是从图像像素出发指向三维空间的向量。
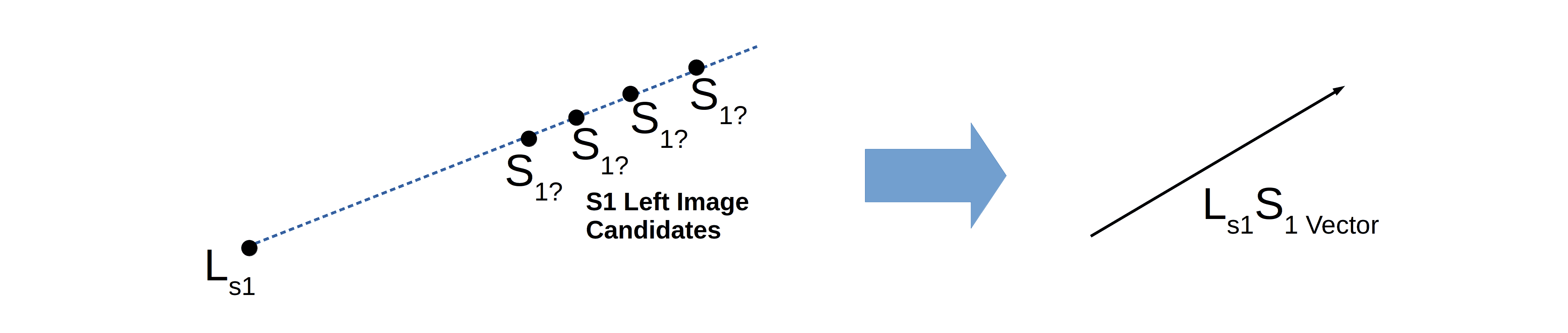
方向向量代表光线从像素传感器出发的方向。这条线上的所有三维点都可能是该二维像素的来源。例如,图中方向向量  来自于左图中的像素点
来自于左图中的像素点  ,它对应于三维空间中的点
,它对应于三维空间中的点  。
。
5.2 方向向量的交点
对于一个三维空间点,在不同视角下拍摄的图像中会对应不同的二维像素点。这些像素点的方向向量会在三维空间中交汇于一点,这个交点就是原始三维点的位置。
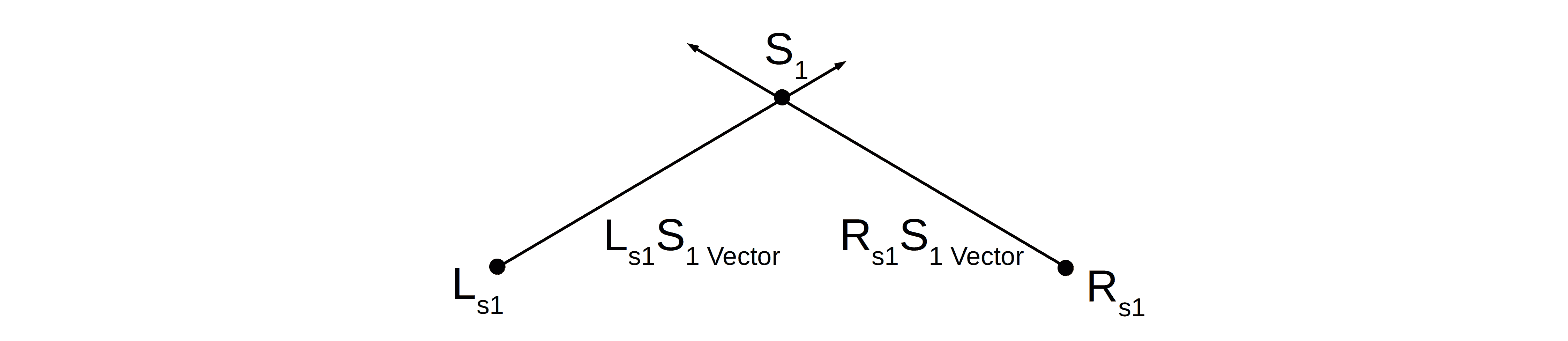
如上图所示,左图和右图中的像素点 和  的方向向量相交于 ,即该点为三维空间中真实存在的点。
的方向向量相交于 ,即该点为三维空间中真实存在的点。
5.3 深度计算
我们假设两个摄像头之间的距离远小于物体到摄像头的距离。 在此前提下,可以通过三角测量法确定三维点在空间中的位置。
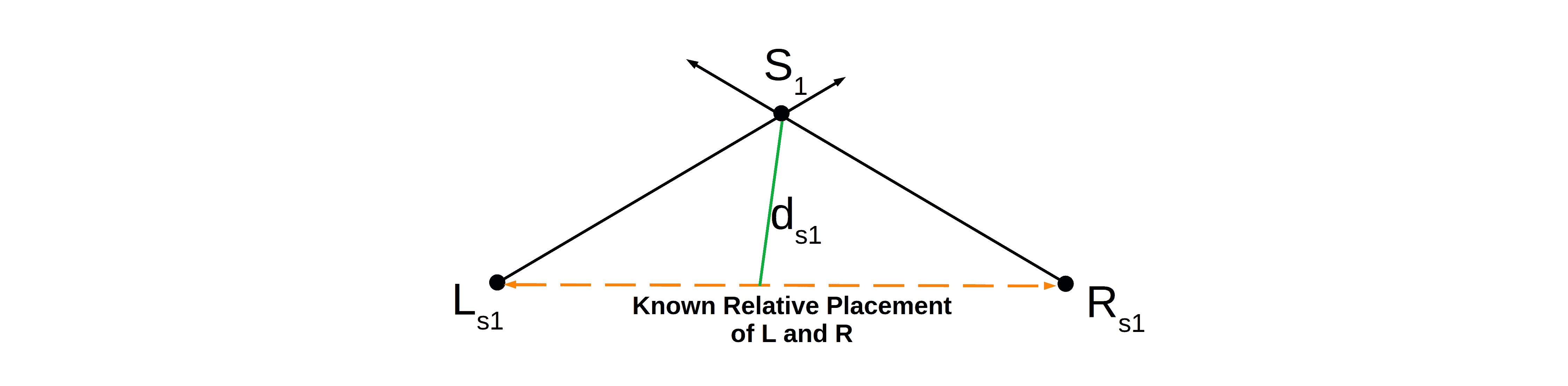
上图展示了点 的实际深度  。虽然 与
。虽然 与  之间的夹角不完全是 90°,但由于 远小于 ,可以近似认为该夹角为 90°。
之间的夹角不完全是 90°,但由于 远小于 ,可以近似认为该夹角为 90°。
根据勾股定理可得:
$$ s^2 = d_{s1}^2 + t^2 $$
解出深度:
$$ d_{s1} = \sqrt{s^2 - t^2} $$
由于 $ s \gg t $,所以 $ d_{s1} \approx s $
6. 立体视觉的数学实现关键概念
实现立体视觉的核心工具是三角测量和差异图(Disparity Map)。
6.1 计算机视觉中的三角测量
三角测量是指通过多个视角图像中的像素点反推其在三维空间中的位置。
输入包括:
- 左右图像中对应点的齐次坐标(如 和 )
- 左右摄像头的相机矩阵
输出是一个三维点的齐次表示。
三角测量的具体实现可能涉及多种方法:
- SVD 分解
- 多项式求根
- 迭代参数估计
- 中点法(Mid-point Method)
- 直接线性变换(Direct Linear Transformation)
- 本质矩阵(Essential Matrix)
不同方法在计算效率和精度上有差异,需根据具体场景选择。
6.2 差异图(Disparity Map)
差异图是立体视觉中用于表示左右图像中像素点水平偏移量的图像。
生成差异图的步骤如下:
- 对左右图像中的每个像素进行匹配
- 计算匹配点之间的水平偏移量(Disparity)
- 将这些偏移量映射为灰度值,生成差异图
要生成差异图,首先要解决“对应问题(Correspondence Problem)”——即找出左右图像中哪些像素对应于同一个三维点。
通过图像校正(Rectification),可以将二维匹配问题简化为一维问题,从而降低计算复杂度。 这就是所谓的“维度灾难(Curse of Dimensionality)”缓解方式。
常见的像素匹配方法是块匹配算法(Block Matching),其核心思想是:
- 在左图中选取一个小窗口
- 在右图中沿水平方向滑动搜索相似窗口
- 使用 SAD(绝对差之和)或 SSD(平方差之和)作为相似度度量
✅ 差异与深度成反比:差异越大,物体越近;差异越小,物体越远。
最后,通过三角化差异图,结合摄像头几何参数,即可生成深度图。
7. 总结
本文介绍了计算机实现立体视觉的基本原理:
- 通过左右摄像头拍摄图像
- 利用极几何和三角测量原理估算深度
- 构建差异图作为中间步骤
- 最终生成深度图用于三维重建
掌握这些基础理论,有助于理解 SLAM、AR、机器人导航等高级视觉应用中的核心算法。