1. 概述
编程语言根据其抽象层级可以分为高阶语言(如 Java、Python、JavaScript、C++、Go)、低阶语言(汇编)以及机器码。
每种高级语言代码,比如 Java,都需要被翻译成机器原生代码才能执行。这个翻译过程可以是编译(Compilation)或解释(Interpretation),当然也有第三种方式:混合使用两种机制,以兼顾效率与灵活性。
本文将深入探讨 Java 是如何在不同平台上进行编译和运行的,并结合 JVM 的设计特性来判断 Java 到底属于编译型语言、解释型语言,还是两者的结合体。
2. 编译型 vs 解释型语言
我们先来看看 编译型语言与解释型语言的基本区别。
2.1. 编译型语言
编译型语言(例如 C++、Go)会通过编译器直接转换为机器原生代码。
它们通常需要一个显式的构建步骤才能运行,所以每次修改代码后都需要重新构建程序。
✅ 编译型语言通常比解释型语言更快更高效,但生成的机器码是平台相关的。
2.2. 解释型语言
解释型语言(如 Python、JavaScript)则没有构建步骤。解释器会在程序运行时逐行读取并执行源代码。
过去解释型语言被认为明显慢于编译型语言。但随着即时编译(JIT)技术的发展,性能差距正在缩小。需要注意的是,JIT 编译器也会在运行过程中将解释型语言的代码转化为机器原生代码。
⚠️ 此外,解释型语言的代码可以在 Windows、Linux、Mac 等多个平台上运行,因为它不依赖特定的 CPU 架构。
3. Write Once, Run Anywhere(一次编写,到处运行)
Java 和 JVM 在设计之初就考虑到了可移植性。因此目前大多数主流平台都能运行 Java 代码。
这听起来像是暗示 Java 是纯解释型语言。但实际上,在执行前,**Java 源代码必须先被编译为 字节码**。字节码是一种专用于 JVM 的机器语言。
JVM 在运行时解释并执行这些字节码。
真正为各个平台定制的是 JVM,而不是我们的程序或库。
现代 JVM 还集成了 JIT 编译器。✅ 这意味着 JVM 可以在运行时优化我们的代码,从而获得接近编译型语言的性能表现。
4. Java 编译器
命令行工具 javac 负责编译 Java 源代码到包含平台无关字节码的 class 文件中:
$ javac HelloWorld.java
源文件以 .java 结尾,而生成的 class 文件以 .class 结尾。
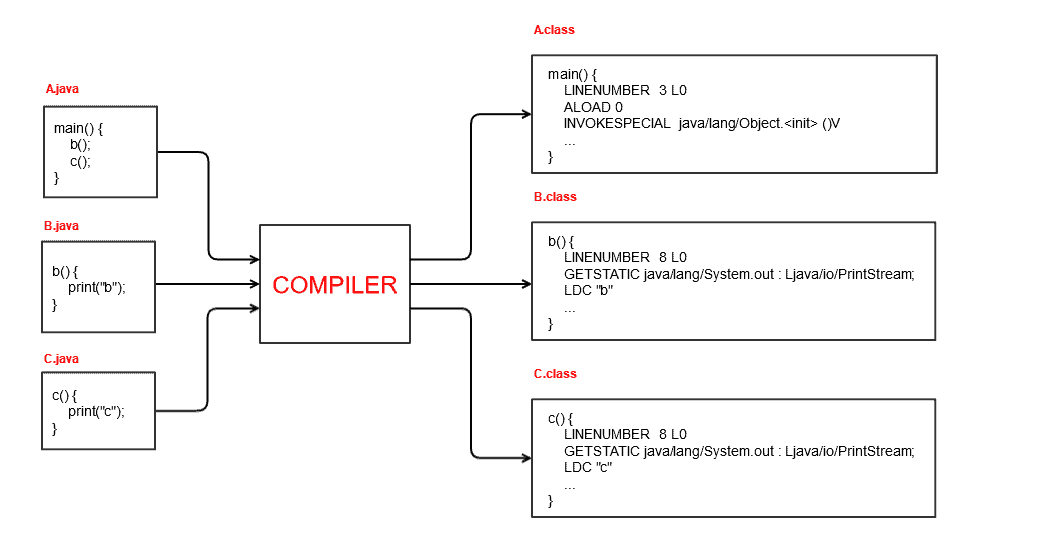
5. Java 虚拟机(JVM)
编译后的 class 文件(即字节码)可以由 Java 虚拟机(JVM) 来 执行:
$ java HelloWorld
Hello Java!
下面我们将深入了解 JVM 架构,目标是搞清楚字节码是如何在运行时被转化为机器原生代码的。
5.1. 架构概览
JVM 由五个子系统组成:
- ClassLoader(类加载器)
- JVM 内存
- 执行引擎
- 本地方法接口(JNI)
- 本地方法库

5.2. ClassLoader(类加载器)
JVM 使用 ClassLoader 子系统将已编译的类文件加载进 JVM 内存。
除了加载之外,ClassLoader 还负责链接和初始化,包括:
- 验证字节码是否存在安全漏洞
- 为静态变量分配内存
- 将符号引用替换为原始引用
- 给静态变量赋初始值
- 执行所有静态代码块
5.3. 执行引擎
执行引擎负责 读取字节码、将其转化为机器原生代码并执行。
它由三个主要组件构成:
执行引擎通过 本地方法接口(JNI) 调用本地库和应用程序。
5.4. JIT 编译器
解释器的一个缺点是:每次调用方法都需要重新解释,这比直接运行编译后的原生代码要慢得多。Java 引入 JIT 编译器来解决这个问题。
JIT 编译器并不会完全取代解释器,执行引擎仍然会使用解释器。但 JVM 会根据方法的调用频率决定是否启用 JIT 编译。
✅ JIT 编译器会将整个方法的字节码编译为机器原生代码,这样就可以重复使用。就像传统编译器一样,包括中间代码生成、优化和最终生成原生代码的过程。
JIT 编译器中的 Profiler 组件负责识别热点代码(Hotspot)。JVM 根据运行时收集的 Profile 信息决定哪些代码需要被 JIT 编译。
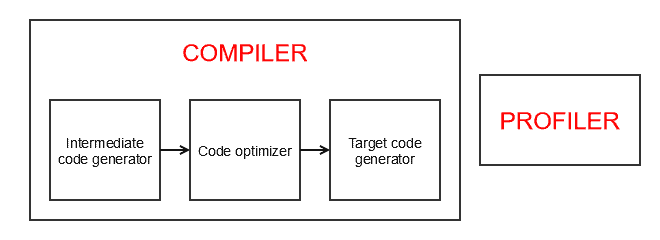
这也意味着 Java 程序可能在运行几次之后变得越来越快。一旦 JVM 识别出热点代码,就可以提前编译为原生代码,提高执行速度。
6. 性能对比测试
我们来看看 JIT 编译是如何提升 Java 运行时性能的。
6.1. 斐波那契数列性能测试
我们使用一个简单的递归方法来计算第 n 个斐波那契数:
private static int fibonacci(int index) {
if (index <= 1) {
return index;
}
return fibonacci(index-1) + fibonacci(index-2);
}
为了测量重复方法调用带来的性能差异,我们将斐波那契方法运行 100 次:
for (int i = 0; i < 100; i++) {
long startTime = System.nanoTime();
int result = fibonacci(12);
long totalTime = System.nanoTime() - startTime;
System.out.println(totalTime);
}
首先,正常编译并运行 Java 代码:
$ java Fibonacci.java
然后,禁用 JIT 编译器再次运行:
$ java -Djava.compiler=NONE Fibonacci.java
最后,我们还实现了相同的算法并运行了 C++ 和 JavaScript 版本作为对比。
6.2. 测试结果分析
以下是运行斐波那契递归测试后测得的平均性能(单位:纳秒):
- ✅ Java 使用 JIT 编译器 —— 2726 ns —— 最快
- ❌ Java 禁用 JIT 编译器 —— 17965 ns —— 慢了 559%
- ❌ C++ 未开启 O2 优化 —— 9435 ns —— 慢了 246%
- ⚠️ C++ 开启 O2 优化 —— 3639 ns —— 慢了 33%
- ❌ JavaScript —— 22998 ns —— 慢了 743%
在这个例子中,使用 JIT 编译器的 Java 性能提升了 500% 以上。当然,JIT 编译器需要运行几轮才会生效。
有趣的是,即使 C++ 启用了 O2 优化,Java 的表现依然比它快了 33%。正如预期的那样,在前几次运行中,C++ 明显优于 Java,因为此时 Java 还处于解释执行阶段。
同时,Java 也远超 Node.js 运行的 JavaScript 代码(Node.js 也使用 JIT)。结果显示 Java 快了 700% 多。主要原因在于 Java 的 JIT 编译器启动得更快。
7. 其他值得思考的问题
从技术角度看,任何静态编程语言都可以直接编译为机器码;同样地,任何语言的代码也可以被逐行解释执行。
像很多现代语言一样,Java 采用的是编译器 + 解释器的组合策略,目的是兼具两者的优点:✅ 高性能 + 平台无关性。
本文主要基于 HotSpot JVM 展开讲解。HotSpot 是 Oracle 默认的开源 JVM 实现。Graal VM 也是基于 HotSpot 的,因此适用相同原理。
当前主流的 JVM 实现大多采用 解释器 + JIT 编译器 的混合模式。当然,也可能存在采用其他机制的实现方式。
8. 总结
本文深入剖析了 Java 和 JVM 的内部机制,目的是判断 Java 属于编译型语言还是解释型语言。我们分析了 Java 编译器和 JVM 执行引擎的工作流程。
结论是:✅ Java 是编译型语言和解释型语言的结合体。
我们写的 Java 源代码首先在构建过程中被编译为字节码。然后 JVM 解释执行这些字节码。但在运行时,JVM 也会借助 JIT 编译器对热点代码进行编译优化,从而提升整体性能。
一如既往,示例代码可以在 GitHub 上获取。