1. Introduction
The ability of artificial intelligence (AI) to understand and process multiple languages has far-reaching implications for global connectivity and accessibility. However, the current state of multilingual AI reveals significant gaps and challenges.
In this tutorial, we’ll explore why current AI models don’t “speak” every human language.
2. Overview
Data availability varies greatly, with widely spoken languages like English and Mandarin having abundant resources, unlike many others. However, each language requires customized approaches in AI algorithms and models due to significant differences in syntax, morphology, phonology, and semantics. Consequently, it’s hard to implement solutions that work well for all languages but can be trained on the corpora available for a few.
Further, the resource-intensive nature of training AI models poses significant computational challenges to supporting multiple languages. For example, biases in training data can result in unfair outcomes for underrepresented languages. Understanding these challenges is crucial for advancing AI to be more inclusive globally.
3. Challenges
There are several challenges to overcome.
3.1. Data Availability and Quality
The world is home to over 7,000 languages, each with its unique structure and cultural significance.
This vast diversity poses significant challenges for AI systems, which require extensive, high-quality data to understand and process multiple languages effectively. While languages like English and Spanish have extensive digital footprints, allowing for the creation of robust AI models, languages with fewer speakers suffer from a severe lack of datasets suitable for training.
Additionally, the lack of diverse linguistic data can lead to biases in AI models, resulting in unfair outcomes for speakers of underrepresented languages. We should incorporate more languages and dialects in training datasets, which is essential to ensure fair AI outcomes across diverse linguistic communities.
3.2. Structural Variability
Languages vary widely in their syntax, morphology, phonology, and semantics.
For example, English has a relatively simple morphological structure compared to languages like Finnish or Turkish, which feature complex inflectional systems. Additionally, tonal languages such as Mandarin present unique challenges due to their reliance on pitch to distinguish meaning.
This variability requires AI models to be highly adaptable and sophisticated to handle different linguistic features. Developing language models that can handle this diversity while remaining cost-effective is a major challenge.
3.3. Computational Limitations
Training large models like OpenAI’s ChatGPT or Google’s BERT in various languages can be very expensive, as developing AI models that support multiple languages is resource-intensive. Additionally, the environmental impact of these operations is substantial due to the compute-intensive nature of model training, which significantly contributes to the carbon footprint of AI development.
It requires significant computational power, storage, and memory. Moreover, each additional language increases the complexity and resource requirements of the training process.
3.4. Scalability and Efficiency
Scaling AI models to support many languages while maintaining high performance poses a significant challenge. We must consider the trade-off between the number of languages supported and the model’s performance. For instance, a model supporting 100 languages might be less accurate in each language than a model focusing on just a few.
Moreover, there is a trade-off between efficiency and language coverage. Efficiency in AI systems refers to the optimal use of computational resources to achieve the desired performance. Increasing the number of languages a model supports requires more complex algorithms and greater computational power, which reduces efficiency. For example, adding support for languages like Japanese or Arabic in addition to English can significantly increase resource demands and make AI systems less efficient.
3.5. Linguistic Complexity and Ambiguity
Each language comes with its own set of complexities. For example, polysynthetic languages, which form words by combining many morphemes, present unique challenges for AI. Additionally, languages use idiomatic expressions and rely heavily on context for meaning, necessitating sophisticated models to understand and generate text accurately.
AI models must also effectively handle linguistic ambiguities, such as homophones—words that sound alike but have different meanings—and context-dependent meanings. Ambiguity in one language can hinder the model’s ability to process ambiguous prompts in another language. This is because the AI must differentiate meanings based on context, which can vary widely across languages.
For instance, an AI trained using English corpora may struggle with the contextual nuances of other languages, such as Mandarin or Arabic, leading to inaccuracies in understanding and generating text. This challenge requires sophisticated natural language processing techniques and extensive training data.
4. Solutions
Recent advances in AI models, such as Google’s Multilingual Neural Machine Translation, demonstrate the potential for supporting multiple languages. These models use transfer learning and other techniques to improve performance across languages with varying amounts of data.
Open-source projects and community contributions also play a crucial role in advancing multilingual AI. By sharing resources and collaborating on datasets, developers can accelerate progress and improve language support in AI models:
We must use diverse and representative datasets to train AI models and mitigate bias. Additionally, ongoing efforts to include more languages and dialects in AI research can help address these disparities. Strategies like active learning and community involvement in data collection can address the problem of data unavailability for many languages.
Future research in multilingual AI should also be focused on improving model efficiency and performance. Trends like zero-shot learning, where models can understand and generate text in new languages without direct training, are promising avenues for expanding language support.
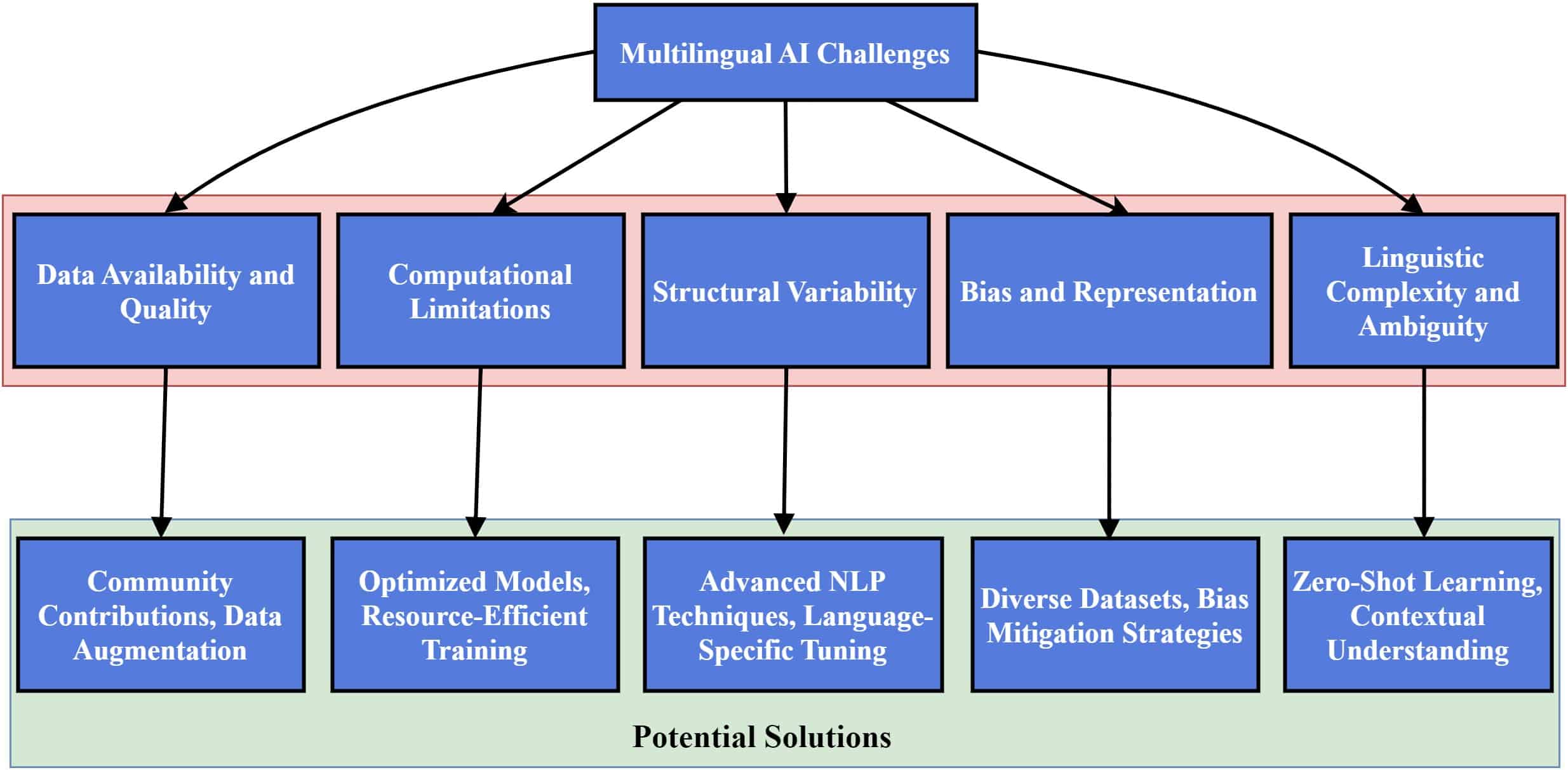
4.1. Summary of Challenges and Potential Solutions
Let’s see how we can overcome each challenge:
Challenge
Description
Potential Solutions
Language Diversity
Over 7,000 languages with unique structures and cultural significance.
Focus on widely spoken languages initially and expand gradually.
Data Availability and Quality
Limited data for many languages, especially lesser-known ones.
Community contributions, data augmentation techniques.
Computational Limitations
High resource requirements for supporting multiple languages.
Optimized models and resource-efficient training techniques.
Linguistic Complexity
Variability in syntax, morphology, phonology, and semantics.
Advanced NLP techniques, language-specific tuning.
Bias and Representation
The underrepresentation of some languages leads to biased AI models.
Diverse datasets, bias mitigation strategies.
Focusing on these areas can help us address these main challenges and significantly improve AI’s ability to support various languages.
5. Conclusion
In this article**,** we explored why AI doesn’t speak every language. We examined the challenges of language diversity, data availability, computational limitations, linguistic complexity, and biases.
Despite significant advancements, AI still struggles to adequately support many of the world’s languages. However, ongoing research and technological improvements promise a more inclusive future.