1. Introduction
In this tutorial, we’ll explain in-depth what ChatGPT is. Specifically, we’ll delve into how ChatGPT works, leveraging neural networks and transformer architecture. Additionally, we’ll explain the training of this model, which includes reinforcement learning from human feedback.
2. Neural Networks and NLP
Neural networks have played a significant role in the progress of Natural Language Processing (NLP) by enabling machines to process and understand language. Over the years, the development and application of neural networks have revolutionized the field, leading to outstanding advancement in machine translation, sentiment analysis, text summarization, chatbots, and many more.
Generally speaking, depending on the type of layers and neurons, we recognize three main categories of neural networks:
- Fully connected neural networks (regular neural networks)
- Convolutional neural networks
- Recurrent neural networks
One of the earliest successful applications in the domain of NLP demonstrated recurrent neural networks. They prove their ability to capture contextual dependencies within a sequence of words. Specifically, RNNs, including variants like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU), showed to be highly effective in tasks with sequential information, such as speech recognition and handwriting recognition.
Despite that, the real turning point and advancement in the field of NLP occurred with the emergence of attention mechanism and transformer models.
3. Attention Mechanism and Transformers
Before the attention mechanism, we widely used RNNs for modelling sequential dependencies in NLP tasks. However, RNNs suffer from challenges such as vanishing gradients and limited parallelization due to their sequential nature. As a result of these limitations, extracting meaningful relationships between distant elements within a text was very challenging.
In 2017, the famous “Attention is All You Need” paper was published by researchers from Google Brain. The attention mechanism was introduced as a solution to solve the limitations of RNNs. Namely, it enables neural networks to focus on specific parts of the input sequence while processing the data. This mechanism allows the model to assign different weights to different positions in the sequence, enabling it to capture the relevance and importance of each position more effectively.
The models that were using attention mechanisms, more precisely self-attention, were called “transformers”. They didn’t have any recurrent or convolution components. Despite that, they demonstrated state-of-the-art performance in various NLP tasks, including machine translation, classification, generation, and many more. The transformer model architecture presented in 2017 is below:
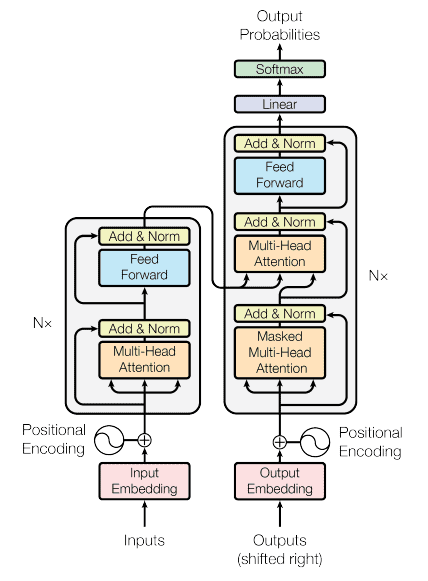
3.1. Types of Transformers
The original “Attention is All You Need” paper introduced a transformer model consisting of two components, an encoder and a decoder. However, as time progressed, subsequent developments led to the creation of new transformer models that were designed with either an encoder or a decoder component alone. This evolution resulted in transformer models specialized for specific tasks.
Following that, we can classify transformer models as:
- Encoder-only transformers – good for tasks that require an understanding of the input, such as sentence classification and named entity recognition. Some of the popular models are BERT, RoBERTa, and DistilBERT
- Decoder-only transformers – good for generative tasks such as text generation. Some of the popular models are GPT, LLaMA, and Falcon
- Encoder-decoder transformers – good for generative tasks that require input, such as translation or summarization. Popular encoder-decoder models are BART, T5 and UL2
All models from the above are also known as large language models (LLMs) because they work with human language and usually have from a few hundred million up to a few hundred trillion parameters. LLMs are a very popular topic today; many big tech companies are actively developing them. We can observe the most popular LLMs and their progress in the image below:
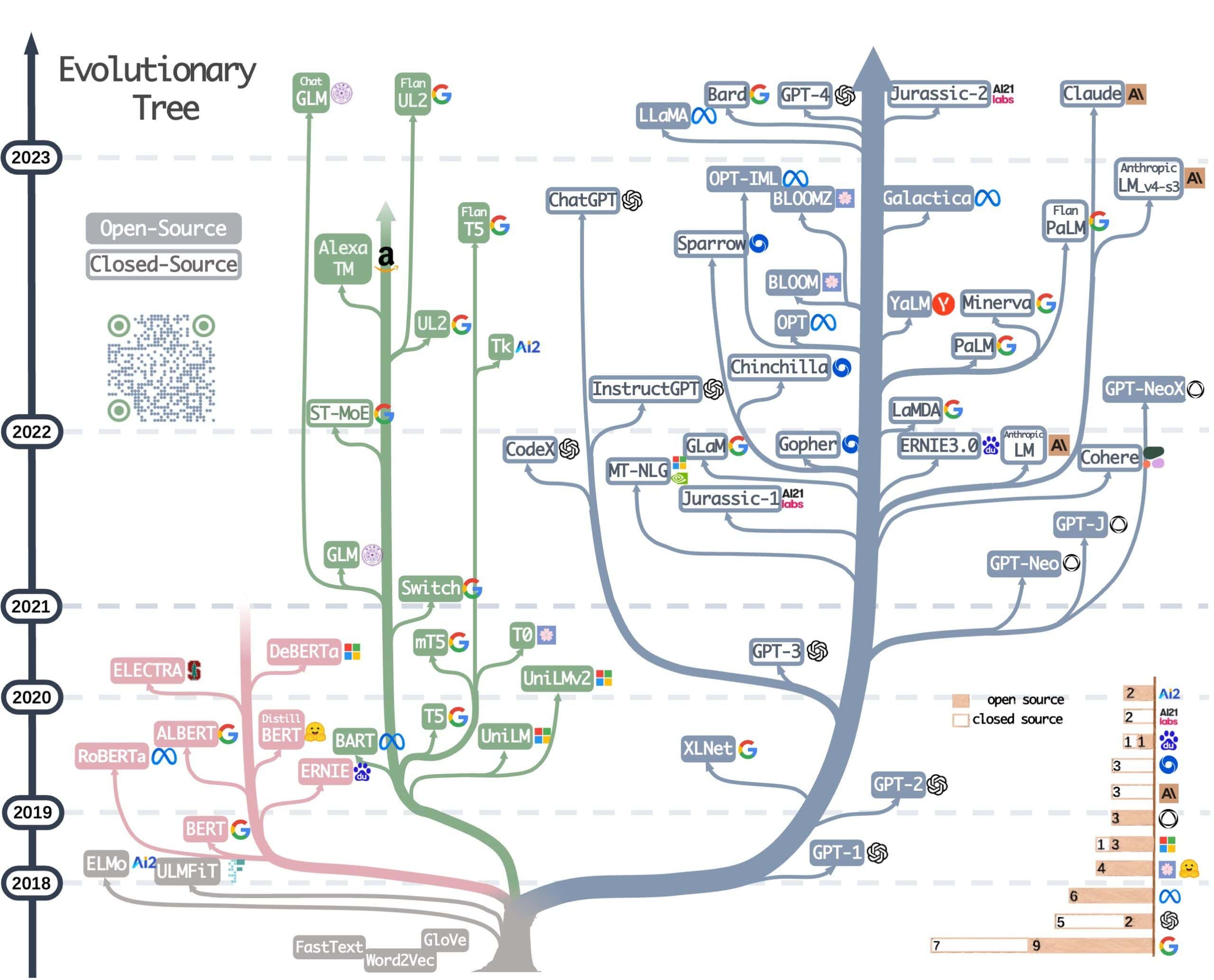
Notice that the pink branches are encoder-only models, the green branches are encoder-decoder models and the grey branches are decoder-only models. Lastly, it’s worth mentioning that in addition to language transformers, visual transformers also work with images. Additionally, hybrid transformer models operate on both images and text, combining the strengths of both modalities.
4. How Does ChatGPT Work?
Firstly, it’s important to note that ChatGPT is not an open-source model, which implies that the exact details of its development and creation are not publicly available. However, despite this limitation, we do have knowledge about prior models and the general approaches used in their development.
ChatGPT originates from earlier GPT models, namely GPT-1, GPT-2, GPT-3, InstructGPT, and finally, ChatGPT itself. These models represent a progression in the development of language models, with each iteration introducing advancements and improvements.
4.1. What Is the Architecture of ChatGPT?
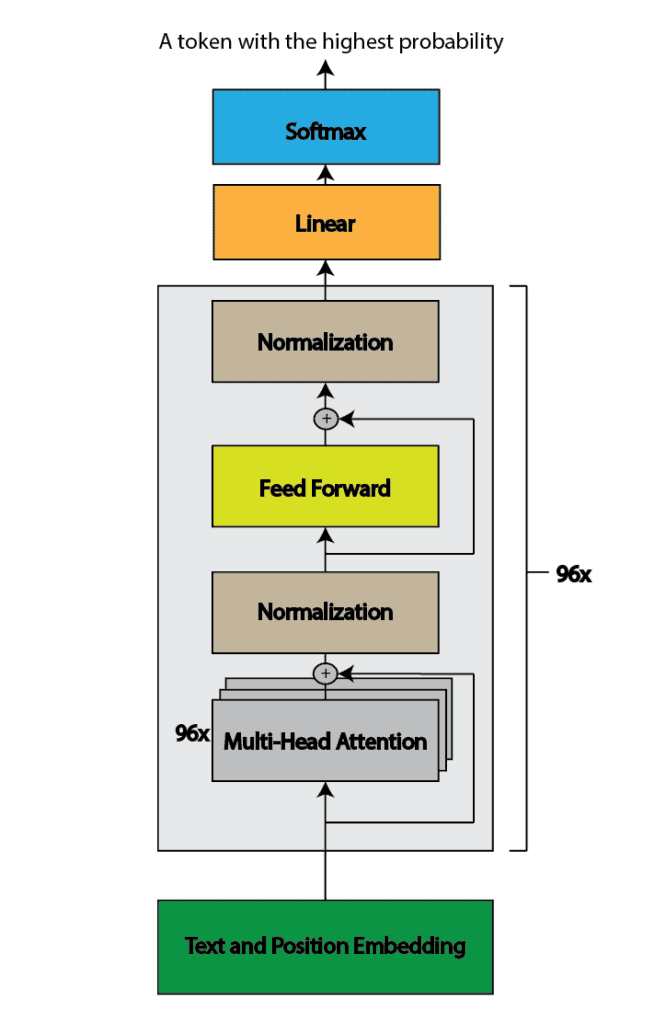
ChatGPT follows a similar architecture to the original GPT models, which is based on the transformer architecture. It uses a transformer decoder block with a self-attention mechanism. As GPT-3, it has 96 attention blocks, each containing 96 attention heads with a total of 175 billion parameters:
4.2. Does ChatGPT Use Embedding?
ChatGPT uses word embeddings to represent words in its model. Word embeddings are dense vector representations that capture the semantic meaning of words. They allow the model to encode and process textual information effectively. The model learns word embeddings during the training process.
Also, text processing involves several steps to convert the input text into a format that the model can understand and generate responses from. These steps include:
- Tokenization
- Context vector of tokens
- Embedding matrix
- Position embedding
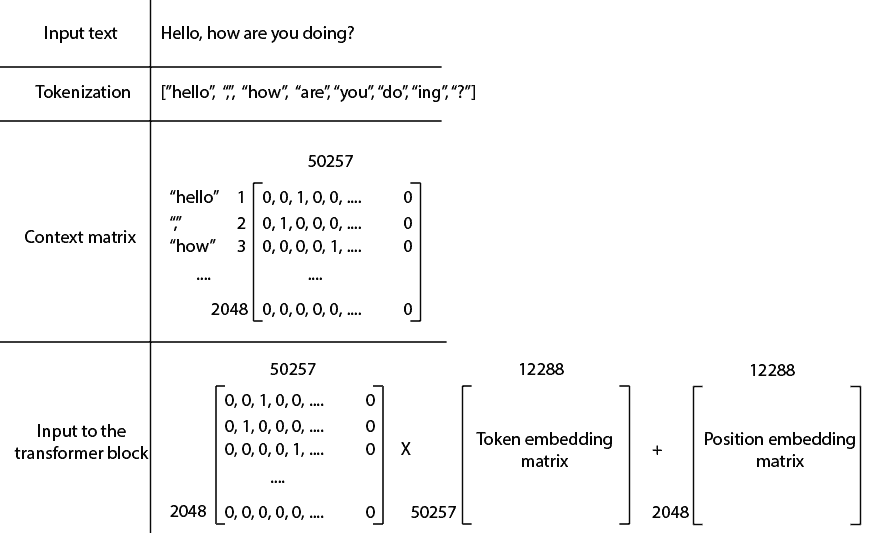
Firstly, the input text is split into tokens. Tokens can represent words, subwords, punctuation marks or characters. ChatGPT recognized  different tokens. These tokens have been defined using byte pair encoding.
different tokens. These tokens have been defined using byte pair encoding.
Afterwards, the tokens are transformed into a context matrix. In essence, this sparse matrix contains zeros and ones, where each row represents a one-hot encoded token. Given that ChatGPT accepts up to  tokens at a time and recognizes a vocabulary of different tokens, the dimension of this matrix is x.
tokens at a time and recognizes a vocabulary of different tokens, the dimension of this matrix is x.
Lastly, the context matrix is multiplied by the token embedding matrix, and the positional embedding is added. The model learns the embedding and positional embedding matrices during the training process, and the embedding vectors have  dimensions:
dimensions:
4.3. What Is the Attention Mechanism in ChatGPT?
The attention mechanism in ChatGPT is a fundamental component that enables the model to capture dependencies between different parts of the input text and generate contextually relevant responses. The attention mechanism lets the model focus on specific words or tokens in the input sequence while generating the output.
More about the attention mechanism is explained in our article here. The only difference is that in the GPT-3 paper, the authors mentioned that they use alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer. However, it’s not clear how exactly this alternating is done.
We only know that the locally banded sparse attention reduces the computational complexity by attending only to a limited number of nearby positions while still capturing relevant dependencies within a certain neighbourhood.
4.4. What Is the Output of ChatGPT?
After the multi-head attention component, the attention block in ChatGPT includes normalization, a feed-forward layer, and another normalization step. ChatGPT consists of  attention blocks. Following these blocks, there is a linear layer and a softmax function. The softmax function produces a probability distribution for the next token, and based on this distribution, the next token is selected.
attention blocks. Following these blocks, there is a linear layer and a softmax function. The softmax function produces a probability distribution for the next token, and based on this distribution, the next token is selected.
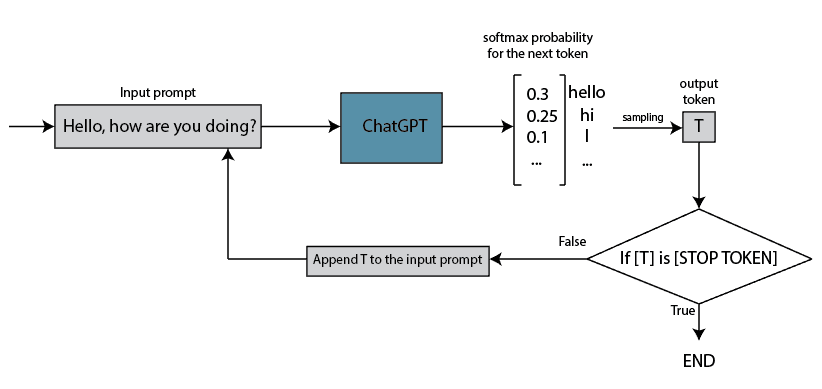
This means that after all the computations, ChatGPT outputs a single token. The sampling of this token is performed from the probability distribution generated by the softmax function. It’s important to note that the ChatGPT API includes a temperature parameter that controls the level of randomness in the softmax function. We have discussed softmax and the temperature parameter in our article, which can be found here.
After the first iteration, the output token is added back to the input prompt, and this process is repeated until the output token corresponds to the end token:
5. How Is ChatGPT Trained?
The training process of ChatGPT is arguably the most crucial aspect responsible for its remarkable ability to engage in human-like conversations. It’s also the most secretive step, with limited information disclosed about its specifics. However, we do have some insights into certain details of the training process.
Roughly, we can divide the training process into two phases:
- Pre-training
- Fine-tuning
5.1. ChatGPT Pre-training
Pre-training played a crucial role in developing a ChatGPT as it helped to learn the basic rules of language and understand common word usage and phrases. This knowledge is then used as a foundation for further customization.
At this stage, the model was trained on a vast dataset of approximately 570GB, consisting of books, articles, Wikipedia, and other internet text sources. The training objective was to predict the next token in a given text based on the context of preceding words. By comparing its prediction with the actual next token in the sentence, the model adjusts its weights during training to enhance the accuracy of future predictions.
After pre-training, the model exhibits the ability to generate meaningful sentences. However, further adjustments are necessary to enhance its performance and make it more conversational, like a chatbot.
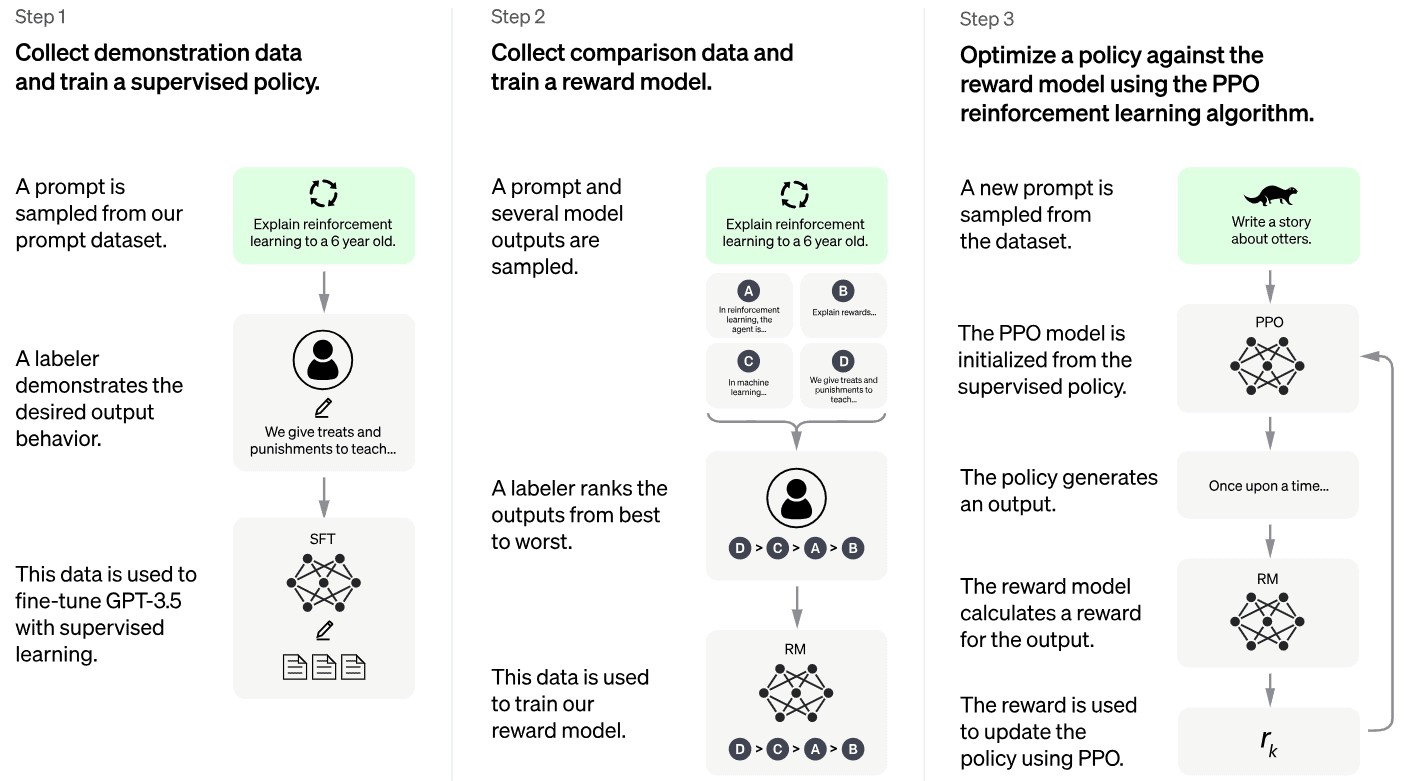
5.2. ChatGPT Fine-tuning
The fine-tuning process had three steps. The initial step involves supervised fine-tuning, where the model is trained using training data constructed from conversations between human AI trainers, who play the roles of both the user and the AI assistant. This dataset consists of question-and-answer pairs and is used to further train the pre trained ChatGPT model.
In the second step, the current model generates multiple predictions for different user prompts. Human annotators ranked those predictions from the least to the most helpful. This ranking data was then utilized to train the Reward Model, which predicts the level of usefulness of a response given a specific prompt.
In the final step, the Proximal Policy Optimization (PPO) algorithm is employed as a reinforcement learning agent to maximize rewards obtained from the Reward Model. Essentially, the model from the first step is utilized to generate responses to user prompts. Following each response, the Reward Model assesses the response and assigns a reward score. The PPO model is then trained to maximize these rewards through the learning process:
6. Conclusion
In this article, we’ve described in detail how ChatGPT work. This is an impressive language model that leverages the power of transformers with several other techniques. It combines the strengths of pretraining and fine-tuning to achieve its remarkable ability to engage in human-like conversations.
The future of language models like ChatGPT is promising, with significant potential for development and advancement. With responsible deployment and ongoing ethical considerations, language models will play a vital role in transforming various industries and revolutionizing how we interact with AI-powered systems.