1. 概述
本文将介绍基于内容的图像检索(Content-Based Image Retrieval,简称 CBIR)的基本概念、工作原理以及其与基于文本的图像检索(TBIR)的区别。
CBIR 在多个领域有广泛应用,例如医学影像分析、司法鉴定、安全监控和遥感图像处理等。掌握其核心原理,有助于我们更好地理解现代图像检索系统的设计思路。
2. 什么是基于内容的图像检索(CBIR)
CBIR 是一种从图像数据库中检索图像的技术。与传统的基于文本的检索方式不同,CBIR 不依赖图像的元数据或标签,而是直接根据图像的视觉内容进行匹配。
具体来说,CBIR 会提取图像的颜色、形状、纹理、空间结构等视觉特征,并通过相似度计算,找出与查询图像最相似的图像。
如下图所示,用户提交一张查询图像后,CBIR 系统会从庞大的图像数据库中找出最相似的图像并排序返回。
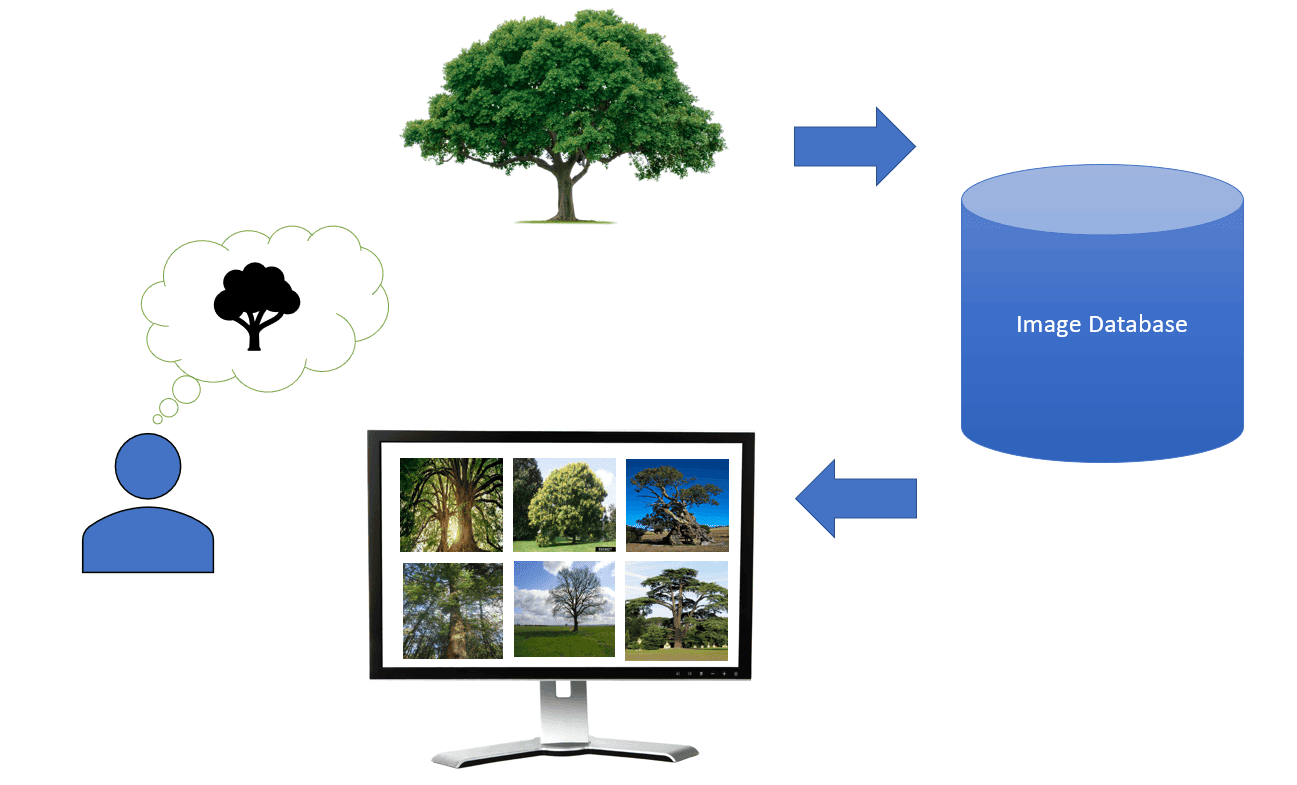
3. CBIR 与 TBIR 的区别
在 TBIR 中,图像通常由人工添加标签、关键词或描述信息,用户通过输入文本进行检索。
例如,用户输入“一只狗在草地上奔跑”,系统会返回所有被标注为“狗”或“草地”的图像。
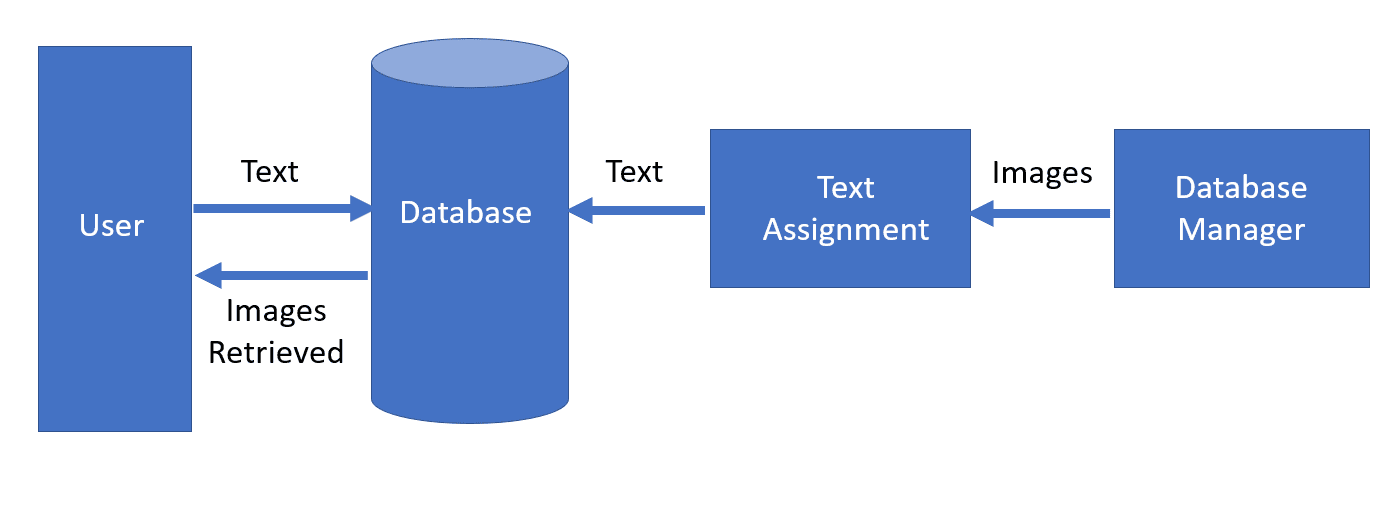
这种方式虽然直观,但存在几个明显问题:
✅ 缺点:
- 标注过程费时费力(人工成本高)
- 标注内容主观性强,不同人可能给出不同标签
- 难以覆盖图像中所有视觉信息
CBIR 则完全绕过了人工标注环节,直接对图像内容进行分析和比对,避免了主观偏差和标注成本。
4. CBIR 中的特征提取方法
特征提取是 CBIR 的核心环节,决定了图像的表示方式和检索效果。
视觉特征通常分为两大类:
4.1 全局特征(Global Features)
全局特征描述整张图像的内容,例如:
- 颜色直方图(Color Histogram)
- 颜色矩(Color Moments)
- 形状描述符(Shape Descriptors)
- 纹理特征(Texture Features)
全局特征适用于图像整体结构较为统一的场景,但对图像的旋转、缩放较为敏感。
下图展示了几种常见的全局特征提取方法:
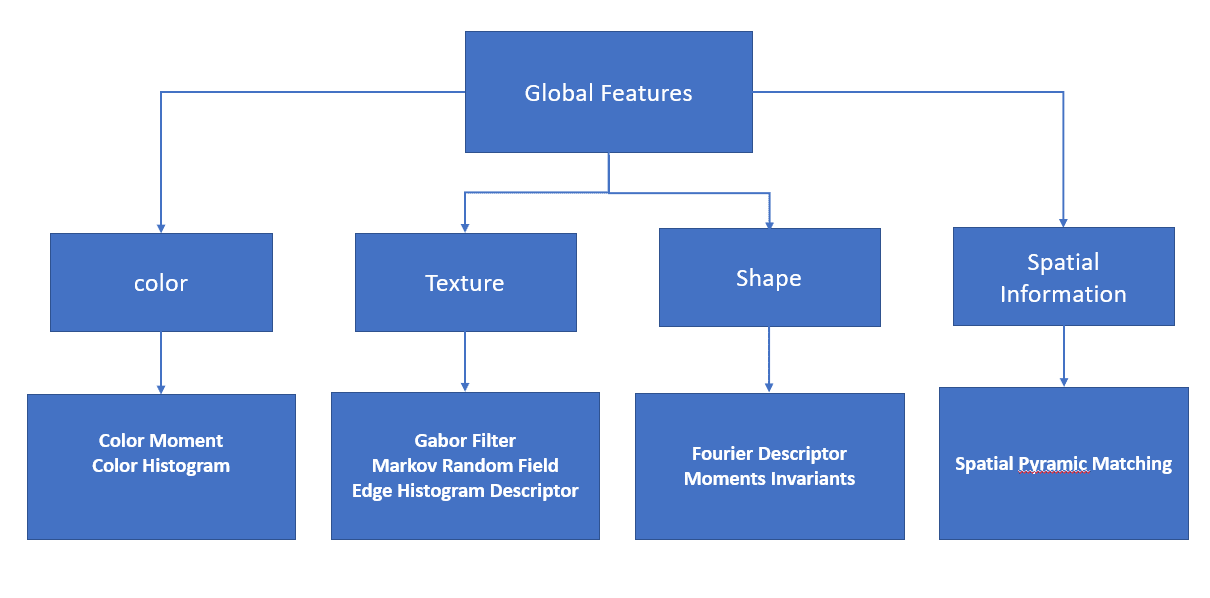
4.2 局部特征(Local Features)
局部特征描述图像中局部区域的视觉结构,如边缘、角点、斑点等。
这类特征对图像的旋转、缩放、光照变化等具有较强的鲁棒性,因此在实际应用中更为可靠。
局部特征提取的关键在于特征点检测和描述子生成。例如:
- SIFT(Scale-Invariant Feature Transform):尺度不变特征变换,具有良好的旋转和尺度不变性
- SURF(Speeded-Up Robust Features):SIFT 的加速版本
- ORB(Oriented FAST and Rotated BRIEF):轻量级且适合移动端部署
⚠️ 注意: 虽然 SIFT 性能稳定,但计算复杂度较高,且需要大量内存存储特征向量。
5. 深度神经网络在 CBIR 中的应用
近年来,深度学习技术在 CBIR 中得到了广泛应用。相比传统方法,基于深度神经网络的特征提取能力更强,能更有效地捕捉图像的语义信息。
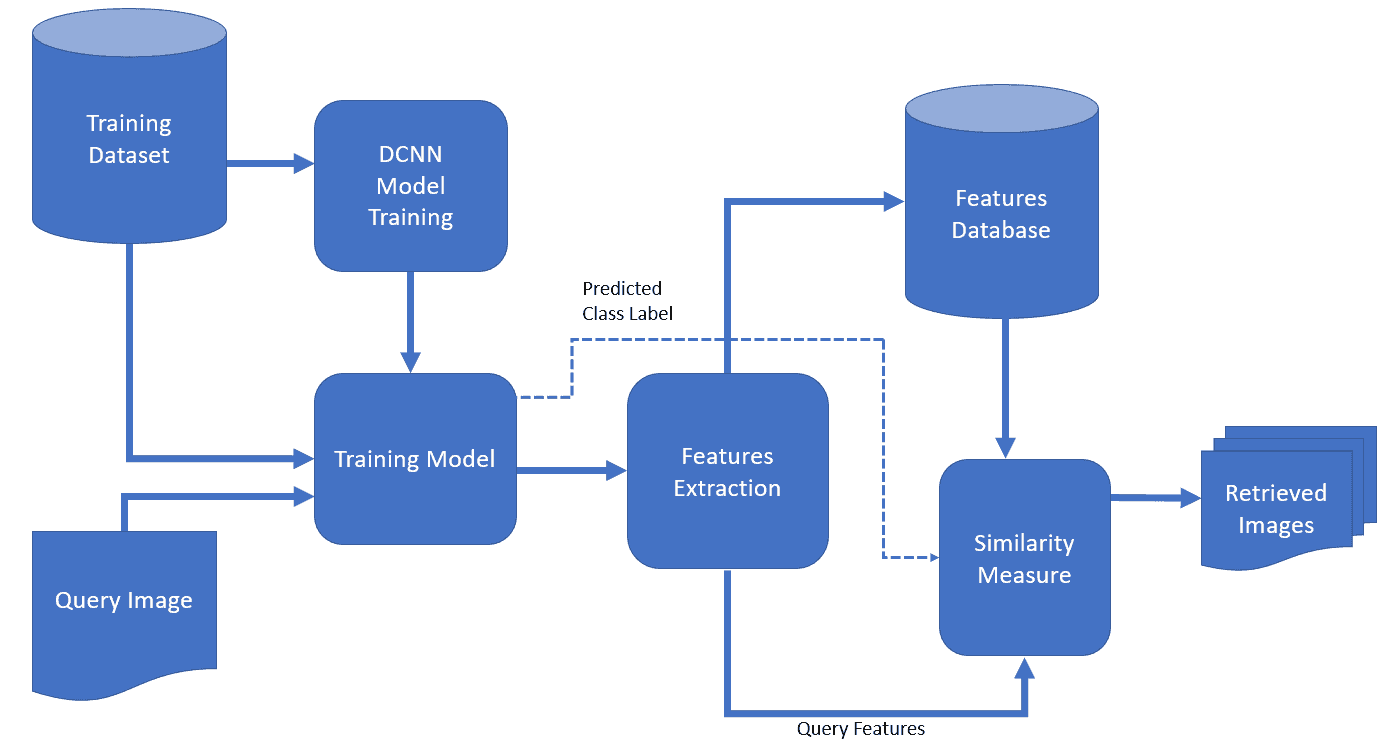
典型的 CBIR 流程如下:
- 使用深度卷积神经网络(DCNN)提取查询图像的特征向量
- 将该特征向量与数据库中图像的特征向量进行比对
- 根据相似度排序,返回最匹配的结果
如下图所示,DCNN 在图像特征提取中起到了核心作用:
目前,许多预训练模型(如 AlexNet、GoogLeNet、ResNet50)可以直接用于特征提取,无需从头训练网络,大大提升了开发效率。
✅ 深度学习优势:
- 自动提取图像特征,无需人工设计特征
- 提取的特征更具语义性
- 可以结合迁移学习,快速适配新任务
6. 相似度度量方法
在 CBIR 中,相似度度量是决定检索结果质量的关键步骤。根据度量方式的不同,可分为两类:
6.1 距离度量(Distance Measures)
距离度量用于衡量两个特征向量之间的“不相似性”。距离越小,表示图像越相似。
常见的距离度量包括:
- 曼哈顿距离(Manhattan Distance)
- 马氏距离(Mahalanobis Distance)
- 直方图交集距离(Histogram Intersection Distance, HID)
HID 的计算公式如下:
$$ HID(S, M) = \sum_{i=1}^{n} \min(M_i, S_i) $$
其中:
- $ S $:查询图像的直方图
- $ M $:目标图像的直方图
- $ n $:直方图维度
HID 的值越大表示两个直方图越相似。其几何意义如下图所示:
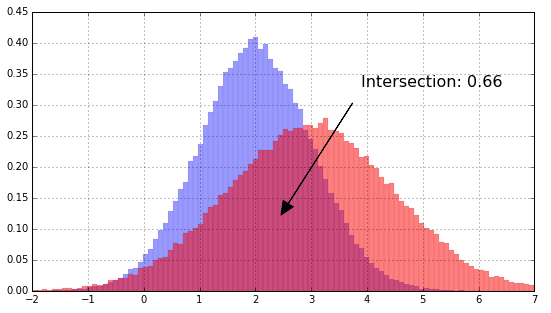
6.2 相似度度量(Similarity Metrics)
相似度度量则直接衡量两个向量之间的相似程度,值越大表示越相似。
例如:
- 余弦相似度(Cosine Similarity):计算两个特征向量之间的夹角余弦值
公式如下:
$$ \text{CosineSimilarity}(X, Y) = \frac{\langle X, Y \rangle}{|X| \times |Y|} $$
其中:
- $ X $、$ Y $:两个特征向量
- $ \langle X, Y \rangle $:向量内积
- $ |X| $、$ |Y| $:向量模长
7. 总结
本文系统介绍了基于内容的图像检索(CBIR)的基本原理、特征提取方法以及相似度度量方式。
CBIR 的核心在于:
✅ 直接分析图像内容而非依赖文本标签
✅ 结合深度学习技术实现高效、准确的图像特征提取
✅ 通过合适的相似度度量方法实现图像匹配
随着深度学习的发展,CBIR 已广泛应用于图像搜索引擎、医学图像分析、智能安防等领域,是图像处理与检索方向的重要技术基础。