1. 简介
在本篇文章中,我们将深入对比两种常见的神经网络结构:常规神经网络(Fully Connected Neural Network, FCNN) 和 卷积神经网络(Convolutional Neural Network, CNN)。
虽然两者都属于神经网络的范畴,但在结构设计、适用场景以及参数效率等方面存在显著差异。通过本文,你将了解:
- 两种网络的核心结构差异
- 激活函数的选择与影响
- 各自适用的应用场景
- 实际使用中的一些“踩坑”点
2. 神经网络概述
神经网络是模拟生物神经网络行为的算法模型,旨在模仿人脑处理信息的方式。根据结构和信息流动方式的不同,主要可以分为三类:
✅ 全连接神经网络(FCNN)
✅ 卷积神经网络(CNN)
✅ 循环神经网络(RNN)
本文重点对比 FCNN 与 CNN 的结构和应用场景差异。
3. 常规神经网络(FCNN)
FCNN 是最早期、最经典的神经网络结构,也被称为多层感知机(Multilayer Perceptron, MLP)。它的每个神经元都与前一层的所有神经元相连,因此称为“全连接”。
3.1. 人工神经元
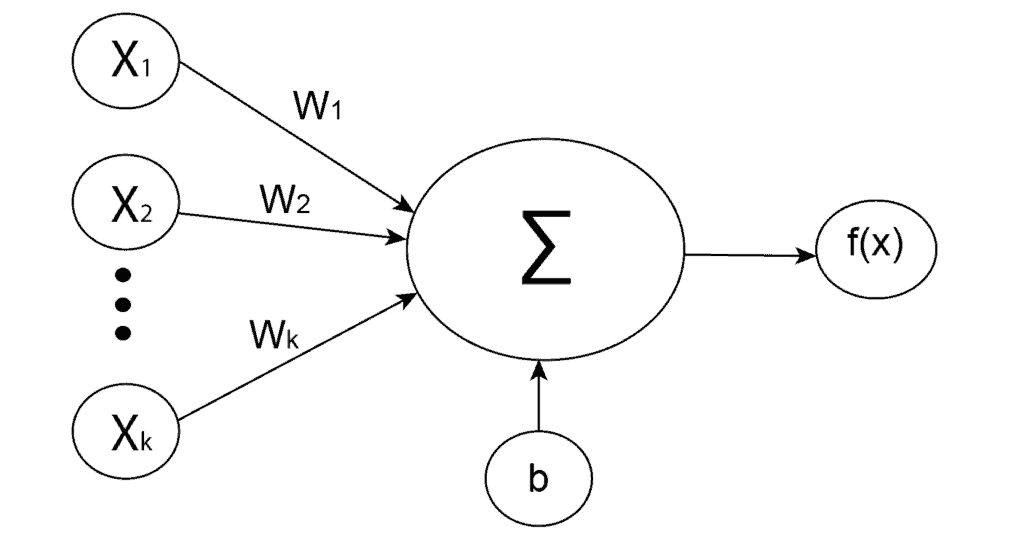
神经元是神经网络的基本单元,接收输入信号并输出一个结果。其计算过程如下:
- 对输入值与权重进行加权求和
- 加上偏置项
- 通过激活函数得到输出
公式如下:
(1)
$$
z^{(i)} = w_{1}x_{1}^{(i)} + w_{2}x_{2}^{(i)} + \cdots + w_{k}x_{k}^{(i)} + b
$$
其中:
- $ w_i $:权重
- $ x_i $:输入
- $ b $:偏置
之后,将 $ z^{(i)} $ 传入激活函数,得到神经元的最终输出。
下图展示了神经元的基本结构:
3.2. 常用激活函数
以下是一些常用的激活函数及其特点:
Sigmoid 函数:
$$ s(x) = \frac{1}{1 + e^{-x}} $$
适合用于二分类输出层,但容易导致梯度消失。Tanh 函数:
$$ \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} $$
输出范围为 [-1, 1],比 Sigmoid 更适合隐藏层。ReLU 函数:
$$ \text{ReLU}(x) = \max(x, 0) $$
解决了梯度消失问题,但可能导致“死神经元”问题。Leaky ReLU 函数:
$$ \text{LReLU}(x) = \begin{cases} x & \text{if } x \geq 0 \ a \cdot x & \text{otherwise} \end{cases} $$ 其中 $ a $ 通常为 0.01,解决 ReLU 的“死神经元”问题。
下图展示了这些激活函数的图形对比:
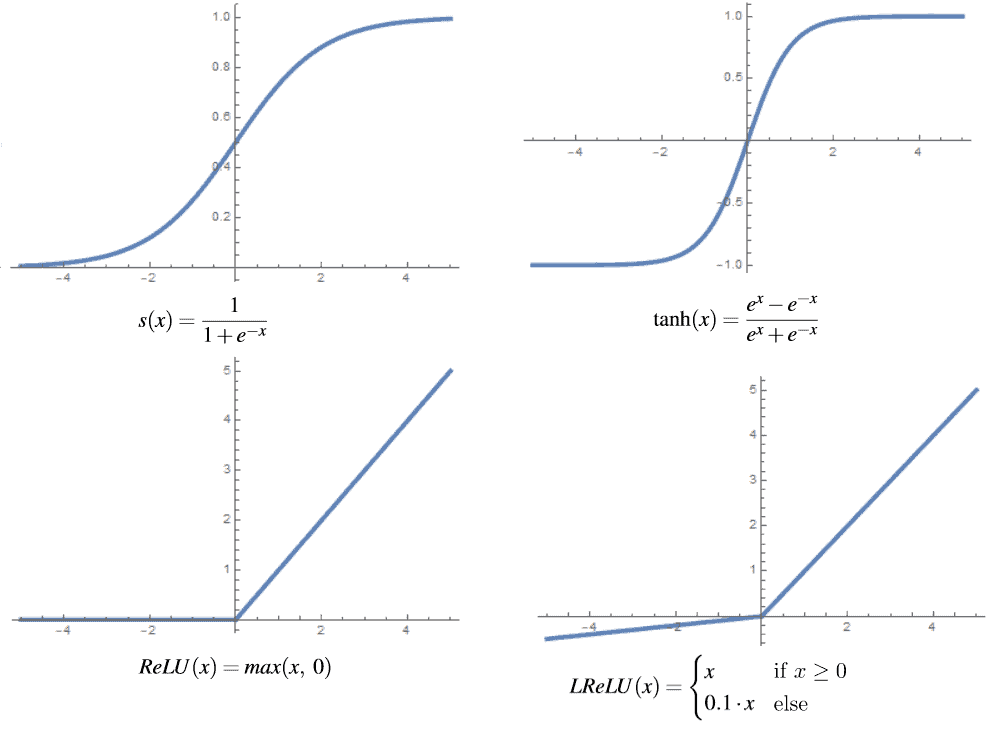
3.3. 应用场景
全连接神经网络适合处理结构化数据(如表格数据)或简单分类任务,常见应用包括:
✅ 股票价格预测
✅ 垃圾邮件分类
✅ 社交趋势预测
✅ 天气预报
✅ 投资组合管理
✅ 信用评级评估
✅ 欺诈检测等
⚠️ 但 FCNN 在处理图像、语音等高维数据时效率较低,参数数量庞大,容易过拟合。
4. 卷积神经网络(CNN)
CNN 是一种专门用于处理具有空间结构数据(如图像)的神经网络,至少包含一个卷积层。它通过局部感受野和参数共享机制,显著减少了模型参数数量,提高了模型效率。
4.1. 卷积神经元
与全连接神经元不同,卷积神经元只连接输入数据的一个局部区域(称为“感受野”),而不是整个输入。这种设计模拟了人类视觉系统对局部特征的敏感性。
卷积神经元通常以二维或三维网格形式排列,称为“滤波器(Filter)”或“卷积核(Kernel)”。每个滤波器会提取输入数据中的不同特征,例如边缘、角点、纹理等。
卷积操作示意图如下:
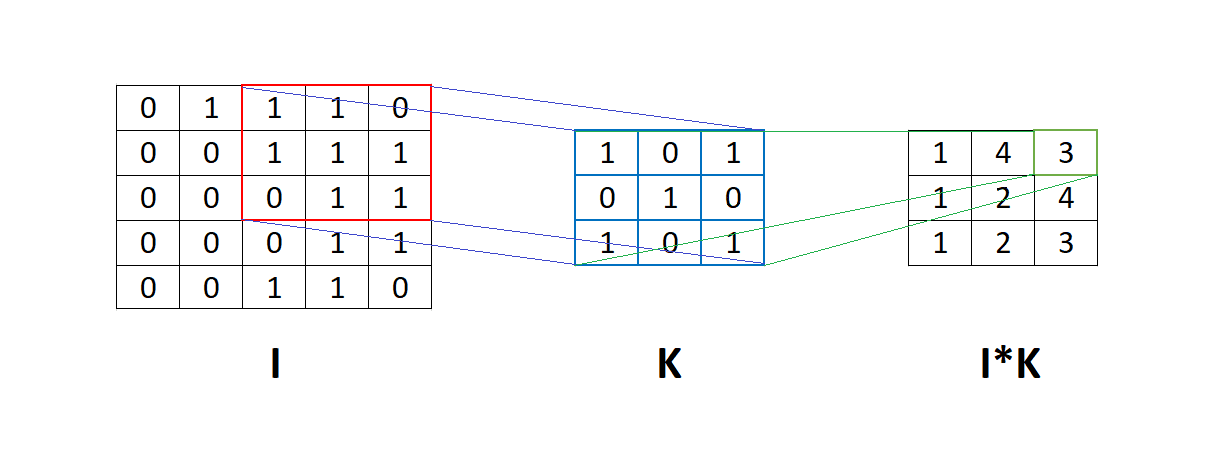
图中展示了如何用滤波器 K 对输入矩阵 I 进行逐元素相乘并求和,得到一个输出值。
4.2. 激活函数
在 CNN 中,激活函数的使用与 FCNN 类似,最常用的是:
✅ ReLU
✅ Tanh
✅ Leaky ReLU / ELU(用于缓解“死神经元”)
ReLU 因其非线性、计算效率高、缓解梯度消失等优点,是 CNN 中最主流的选择。
4.3. 应用场景
CNN 主要用于处理图像、视频、文本等具有空间结构的数据,常见应用包括:
✅ 人脸识别
✅ 自动驾驶中的目标检测
✅ 医学图像分析与分割
✅ 推荐系统
✅ 图像描述生成等
⚠️ 虽然 CNN 也可以用于文本处理,但在 NLP 领域,Transformer 等架构已逐渐成为主流。
5. 总结
本文对比了全连接神经网络(FCNN)与卷积神经网络(CNN)的核心差异:
| 特性 | FCNN | CNN |
|---|---|---|
| 结构 | 全连接,每个神经元连接所有输入 | 局部连接,参数共享,使用卷积核提取特征 |
| 参数量 | 大,易过拟合 | 小,更适合图像等高维数据 |
| 激活函数 | Sigmoid、Tanh、ReLU、Leaky ReLU | ReLU、Tanh、Leaky ReLU 等 |
| 适用场景 | 表格数据、简单分类 | 图像、视频、文本等空间数据 |
| 优势 | 易实现、适合结构化数据 | 特征提取能力强、参数效率高 |
✅ 简而言之:FCNN 更适合处理结构化、低维数据;CNN 更适合处理图像、语音等高维、具有空间结构的数据。
📌 踩坑提醒:
- 在图像任务中使用 FCNN 会导致参数爆炸,训练效率极低
- CNN 中的卷积层虽然参数少,但需要合理设置卷积核大小和步长
- 使用 ReLU 时注意“死神经元”问题,可考虑使用 Leaky ReLU 或 ELU 替代
希望本文能帮助你更好地理解两种神经网络的区别,并在实际项目中做出合理选择。