1. 简介
在本教程中,我们将探讨深度优先搜索(DFS)与广度优先搜索(BFS)的基本原理。然后我们会比较它们的差异,并讨论在哪些场景下更适合使用其中某一种算法。
2. 搜索问题
搜索问题通常是指在图中寻找从起点节点到目标节点的最优路径。这类问题有多种变体:图可以是有向或无向、带权或不带权,目标节点也可能有多个。
DFS 和 BFS 适用于不带权图,因此我们通常用它们来寻找起点和目标之间的最短路径。
3. DFS 与 BFS 的核心区别
两种算法都会在图上构建一棵搜索树作为辅助结构。DFS 和 BFS 的差异在于访问节点的顺序不同。
- DFS 会优先深入探索最近加入的节点的子节点,直到无法继续深入,再回溯。
- BFS 则逐层扩展节点,先遍历完当前层的所有子节点,再进入下一层。
3.1 树状搜索 vs 图搜索
搜索算法通常有两种实现方式:
- 树状搜索(Tree-Like Search, TLS):不检查重复节点,可能陷入循环。
- 图搜索(Graph Search, GS):记录已访问节点,避免重复访问,但需要更多内存。
本文主要讨论 TLS 实现,因为更容易理解两者的区别。
4. 概念上的区别
我们通过一个搜索树示例来说明两者的区别。
如下图所示:
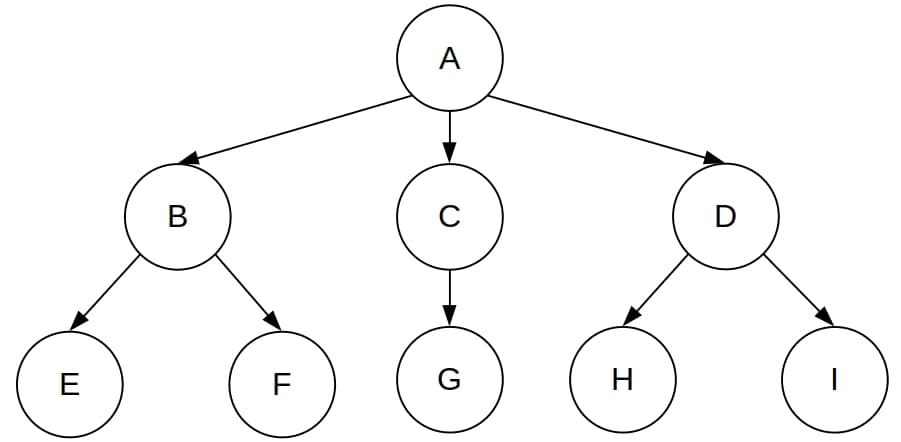
DFS 和 BFS 的节点访问顺序如下:
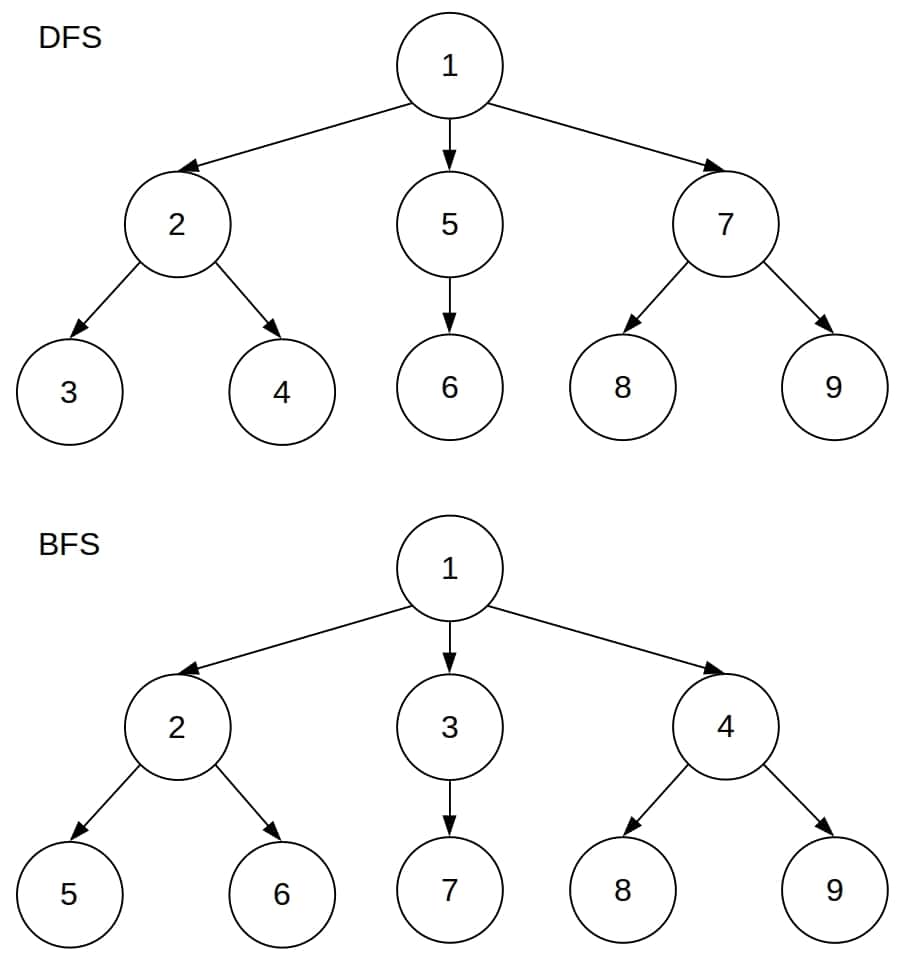
可以看到:
- BFS 是按层访问的,每一层的节点编号都小于下一层。
- DFS 则是按子树访问的,优先深入探索某一条路径。
✅ 结论:BFS 是层序扩展,DFS 是子树扩展。
5. 实现上的区别
两种算法在执行过程中都会维护一个“搜索边界”(frontier),即已发现但尚未加入搜索树的节点集合。
- BFS 使用 FIFO 队列(先进先出),优先扩展最早加入的节点。
- DFS 使用 LIFO 栈(后进先出),优先扩展最晚加入的节点。
DFS 也可以用递归实现,此时系统调用栈就充当了搜索边界。
我们可以用一句话总结它们的行为:
- ✅ DFS 扩展边界中最深的节点。
- ✅ BFS 扩展边界中最浅的节点。
6. 完备性与最优性比较
6.1 完备性(Completeness)
DFS 不是完备的:在存在循环的图中,DFS 可能陷入无限循环,即使目标节点离起点很近。
例如,以下图中,DFS 可能在 A 和 B 之间来回循环:
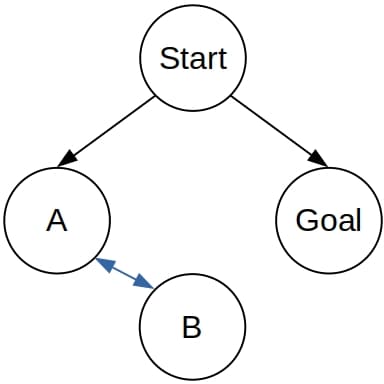
BFS 是完备的:只要图是有限的,或者满足目标可达且每个节点的子节点数有限,BFS 就能终止。
6.2 最优性(Optimality)
- DFS 不保证最优路径:它可能先找到一条更长的路径,从而返回非最优解。
- BFS 是最优的:它总是找到从起点到目标的最短路径(边数最少)。
❌ 踩坑提醒:如果你需要最短路径,不要用 DFS!
7. 时间与空间复杂度对比
我们假设:
b:树的分支因子m:最长路径的长度d:最浅目标节点的深度
7.1 时间复杂度
| 算法 | 时间复杂度 |
|---|---|
| DFS | O(b^m) |
| BFS | O(b^d) |
BFS 在最坏情况下要遍历到目标节点所在层的所有节点,而 DFS 会深入到图的最深处。
7.2 空间复杂度
| 算法 | 空间复杂度 |
|---|---|
| DFS | O(bd) |
| BFS | O(b^d) |
⚠️ 注意:BFS 需要存储整个边界队列,因此在分支因子大时,内存消耗会非常严重。
DFS 的空间复杂度可以通过优化进一步降低:
- 如果每次只生成一个子节点(而不是全部),空间复杂度可降为
O(d)。 - 如果节点可以互相转换(如状态压缩),甚至可以做到
O(1)。
8. 如何选择 DFS 或 BFS?
选择算法时应考虑以下因素:
✅ 使用 DFS 的场景:
- 目标节点可能很深。
- 内存有限。
- 可接受非最优路径。
- 问题适合递归实现(如回溯、约束满足问题)。
例如:八皇后问题、数独求解。
✅ 使用 BFS 的场景:
- 需要最短路径。
- 目标节点可能在浅层。
- 可接受高内存消耗。
- 图的分支因子小。
例如:社交网络中找最近联系人、地图中找最短路径。
⚠️ 注意:虽然 BFS 在理论上更优,但其高内存消耗常使其不适用于大规模图。
9. 结论
DFS 和 BFS 各有优劣:
| 特性 | DFS | BFS |
|---|---|---|
| 完备性 | ❌(可能陷入循环) | ✅ |
| 最优性 | ❌ | ✅ |
| 时间复杂度 | O(b^m) | O(b^d) |
| 空间复杂度 | O(bd) | O(b^d) |
在实际应用中,DFS 更常见,因为它内存消耗更低,适合大规模图搜索。如果担心 DFS 的不完备性和非最优性,可以使用迭代加深搜索(Iterative Deepening),它结合了 DFS 的低内存和 BFS 的完备性与最优性。