1. 引言
Dijkstra 算法和 A* 算法是路径查找中非常著名的两种方法。它们都能用于在图中寻找最优路径,但在实际应用中各有特点。
本文将从算法原理、适用场景、复杂度对比等方面对 Dijkstra 和 A* 进行比较,帮助你理解它们之间的异同点。
2. 寻找最优路径
在人工智能的搜索问题中,我们通常面对的是一个图结构:
- 图中的节点表示 AI 代理的状态
- 边表示代理从一个状态转移到另一个状态所需执行的动作
- 目标是找到从起点状态到目标状态的最优路径
最优路径指的是总成本最低的路径。边的成本可以是距离、时间、能量消耗等,路径的总成本是其所有边成本的总和。
这类问题可以通过多种算法解决,包括 Dijkstra、A*、Uniform-Cost Search(UCS)等。
3. Dijkstra 算法
Dijkstra 算法的输入包括:
- 图 G = (V, E, c)
- 起点 s ∈ V
- 终点 t ∈ V
其中:
- V 是顶点集合(对应状态)
- E 是边集合
- c(u, v) 是从 u 到 v 的边成本
Dijkstra 会维护两个集合:
✅ S:已找到从起点 s 到该节点的最优路径的节点集合
✅ Q:尚未找到最优路径的节点集合,每个节点都有一个估计成本 g(u),表示从 s 到 u 的当前最短路径长度
算法流程如下:
- 初始化:所有节点加入
Q,g(u)初始化为无穷大,g(s)= 0 - 每次从
Q中取出g(u)最小的节点 u - 遍历 u 的所有邻接边 (u, v),尝试更新
g(v):- 如果
g(u) + c(u, v) < g(v),则更新g(v),这一步叫做“松弛(relax)”
- 如果
- 将 u 移入
S - 重复步骤 2~4,直到
t被移入S或Q为空
关键性质
Dijkstra 的一个重要不变性是:
当从
Q中取出一个节点 u 并将其加入S时,g(u)就等于从 s 到 u 的最优路径成本。
这保证了算法的正确性。
4. A* 算法
A* 是 Dijkstra 的改进版本,特别适用于 AI 中状态空间非常大甚至无限的场景。
4.1. 核心思想
A* 不仅考虑从起点到当前节点的成本 g(u),还引入了一个启发式函数 h(u) 来估计从当前节点到目标的成本。
因此,A* 的优先级排序是基于 f(u) = g(u) + h(u) 的。
g(u):从起点到 u 的实际成本h(u):从 u 到目标的估计成本
4.2. 启发式函数(Heuristic)
启发式函数 h(u) 是 A* 的关键。它必须满足以下条件:
- Admissible(可接受):不能高估真实成本,即
h(u) ≤ h*(u),其中h*(u)是 u 到目标的真实最优成本 - Consistent(一致):满足三角不等式,即
h(u) ≤ c(u, v) + h(v),其中c(u, v)是 u 到 v 的边成本
常见的启发式函数包括:
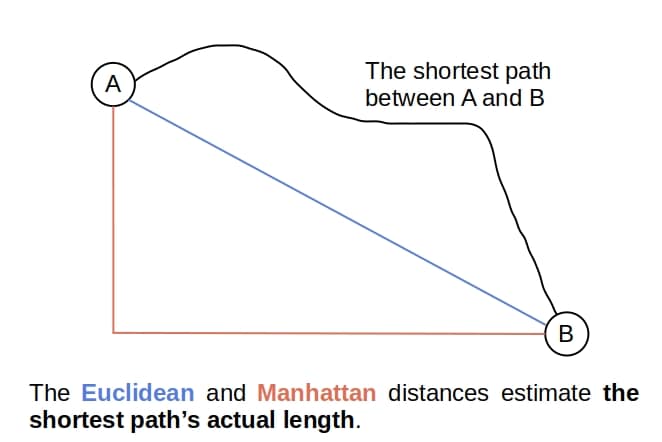
- 欧几里得距离(Euclidean Distance)
- 曼哈顿距离(Manhattan Distance)
示例图
5. 假设条件对比
| 算法 | 图的大小 | 边成本 | 是否需要启发式 |
|---|---|---|---|
| Dijkstra | 有限图 | 非负 | ❌ |
| A* | 有限或无限图 | 严格正数 | ✅ |
A* 的额外要求
- 所有边成本必须大于等于某个正数 ε > 0
- 图必须有限,或者从起点可达目标节点
6. 搜索树与搜索轮廓
Dijkstra 和 A* 都会在图上构建一个搜索树,树的每个节点代表一个状态和到达该状态的路径。
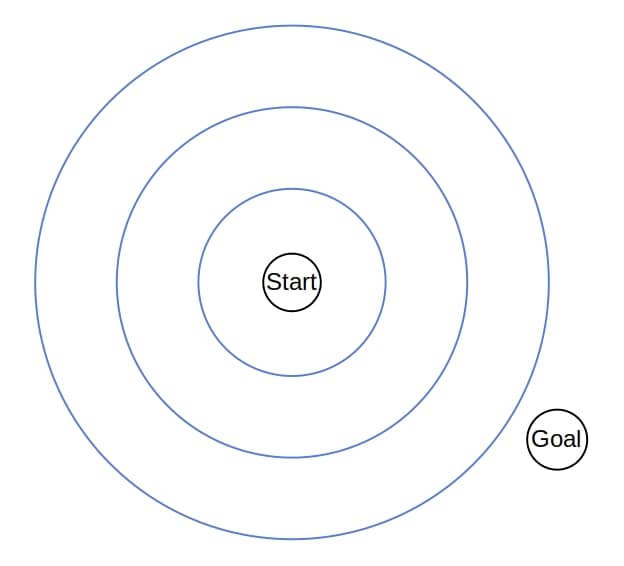
6.1. Dijkstra 的搜索轮廓
Dijkstra 会均匀地扩展搜索区域,就像波纹一样扩散开来。
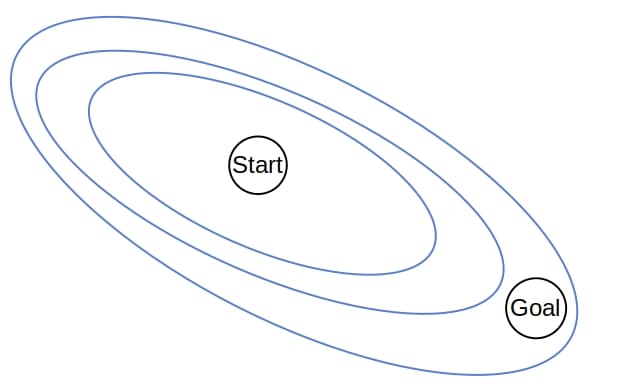
6.2. A* 的搜索轮廓
A* 利用启发式函数引导搜索方向,优先扩展靠近目标的节点。
7. 时间与空间复杂度对比
| 算法 | 时间复杂度 | 空间复杂度 | 搜索轮廓 |
|---|---|---|---|
| Dijkstra | O( | V | ²) 或 O( |
| A*(图搜索) | O( | E | + |
| A*(树搜索) | O(b^(C*/ε)) | O(b^(C*/ε)) | 向目标拉伸 |
⚠️ A* 在实际中通常比 Dijkstra 更快,因为它能通过启发式函数剪枝大量不必要的搜索路径。
8. 算法层级关系
我们可以把 A* 看作是 Dijkstra 的一种泛化:
- 如果使用
h(u) = 0,A* 就退化为 Uniform-Cost Search(UCS) - UCS 与 Dijkstra 在搜索树结构上等价
所以:
Dijkstra 是 A* 的一个特例。
9. 示例对比
考虑以下图结构:
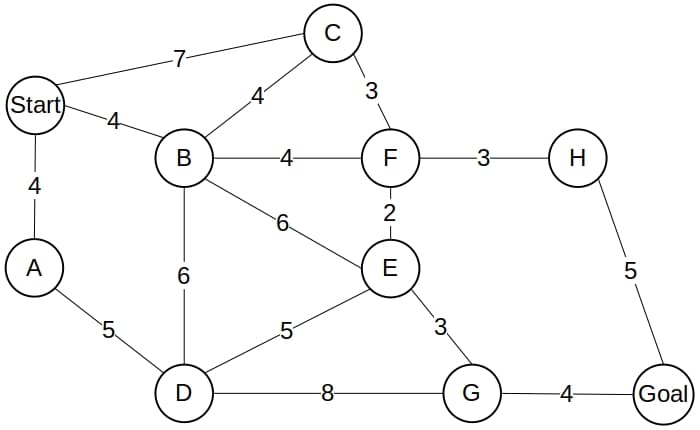
Dijkstra 的搜索树
Dijkstra 会遍历整个图,最终找到最优路径:
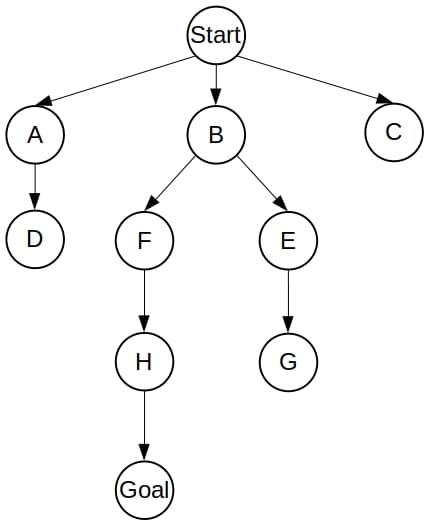
A* 的搜索树
如果我们使用以下启发式估计值:
h(A) = 13, h(B) = 10, h(C) = 10, h(D) = 9
h(E) = 7, h(F) = 7, h(G) = 2, h(H) = 3
h(Start) = 15, h(Goal) = 0
A* 只会扩展最优路径上的节点:

10. 总结对比表
| 特性 | Dijkstra | A* |
|---|---|---|
| 图类型 | 有限图 | 有限或无限图 |
| 边成本 | 非负 | 严格正数 |
| 时间复杂度 | O( | V |
| 空间复杂度 | O( | V |
| 搜索轮廓 | 均匀扩展 | 向目标拉伸 |
| 实际效率 | ✅ 稳定 | ⚠️ 依赖启发式函数质量 |
| 输入要求 | 只需图结构 | 需要启发式函数设计 |
11. 结论
Dijkstra 和 A* 都是路径查找的经典算法,但适用场景不同:
- Dijkstra:适合图结构较小、无启发式信息的场景,保证找到最优路径
- **A***:适合图结构大、有启发式信息的场景,效率更高,但依赖启发函数设计
选择哪个算法,取决于你是否拥有启发式知识、图的规模、边成本类型等因素。
✅ A* 的优势来自于启发式函数的质量,所以在实际项目中,设计一个高效的启发式函数是关键。