1. Introduction
Even though cloud computing is becoming more popular, it still faces challenges, such as unreliable latency, poor mobility support, and a lack of location awareness. To overcome these problems, fog computing offers flexible resources and services directly to users on the edge of the network.
In this tutorial, we’ll examine the fog computing paradigm: its definition, benefits, reference architecture, application scenarios, and potential issues in the field of fog computing.
2. Definition of Fog Computing
Fog computing is a decentralized computing system that extends cloud computing capabilities to better accommodate the Internet of Things (IoT) ecosystem. It aims to bring intelligence, processing, and storage closer to the network’s edge to provide quicker and more localized computing services for the connected smart devices that make up the IoT.
The terms “fog computing” and “edge computing” are often used interchangeably, but there are slight differences between them. While fog computing serves as a computing layer between the cloud and the edge, edge computing refers to the movement of computing tasks to the network’s edge. Data streams generated at the edge nodes are first processed by fog nodes, which then decide whether to forward the data to cloud nodes or perform additional processing at the fog nodes. For these reasons, fog computing can be seen as a superdivision of edge computing.
A fog device (or fog node) is a highly virtualized IoT node that provides computing, storage, and network services between edge devices and the cloud. It has characteristics similar to those of the cloud. It can be considered a mini-cloud that leverages its own resources and the data collected from edge devices in combination with the vast computational resources available from the cloud. By bringing computational resources closer to end devices, fog computing enables the development and deployment of low-latency applications directly on devices like routers, switches, small data centers, and access points.
3. Benefits of Fog Computing
Fog computing provides effective solutions to many limitations faced by cloud computing, including:
- Latency sensitivity: Fog computing provides the ability to perform computing tasks closer to the end-user, making it ideal for applications that require low latency and cannot be deployed in the cloud
- Network bandwidth constraints: By performing data processing at the network’s edge, fog computing reduces the amount of raw data transmitted to the cloud, allowing for faster data analysis and providing only filtered data to the cloud for storage
- Resource-constrained devices: Fog computing can support computational tasks for resource-limited edge devices, such as smartphones and sensors, by offloading some of the application’s workload to nearby fog nodes, reducing energy consumption and overall cost
- Improved availability: Fog computing allows for autonomous operation without reliable network connectivity to the cloud, enhancing the application’s availability
- Enhanced security and privacy: A fog device can locally process sensitive data without transmitting it to the cloud, providing better privacy and giving the user full control over collected data. These devices can also enhance security by performing various security functions, managing security credentials for constrained devices, and monitoring the security status of nearby devices
4. Reference Architecture of Fog Computing
Now take a look at the OpenFog Reference Architecture, the most well-known fog computing architecture, which was proposed by The OpenFog Consortium in 2017. The OpenFog Consortium is a consortium founded by high-tech industry companies and academic institutions worldwide, such as Cisco Systems, Intel, Microsoft, Princeton University, Dell, and ARM:
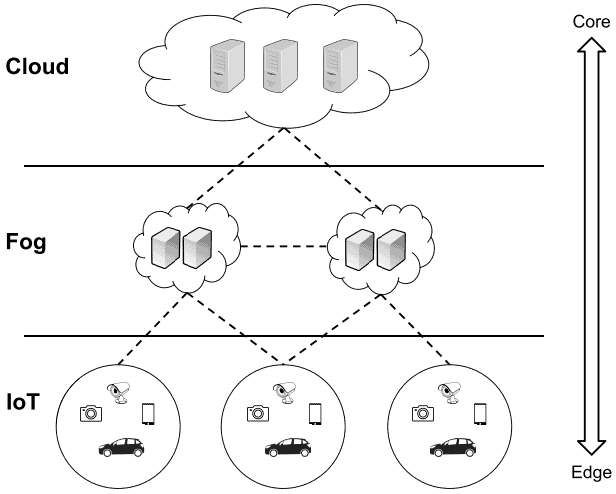
The three layers composing the architecture are described below:
- IoT layer: This layer comprises IoT devices, such as sensors or smartphones. These devices are usually geographically distributed and mainly aimed at sensing data and sending them to the upper layer for storage or processing.
- Fog layer: Composing many fog nodes, this layer is the core of the fog computing architecture. Fog nodes can compute, transmit, and temporarily store data, and they can be located anywhere between cloud and end devices
- Cloud layer: This layer is mainly composed of the centralized cloud infrastructure. It is composed of several servers with high computational and storage capabilities and provides different services
5. Applications Scenarios
Here we’ll see the three scenarios that will benefit from the concept of fog computing.
- Augmented Reality (AR) and real-time video analytics: The use of fog computing can enhance the processing speed and responsiveness of high-volume video streaming and improve the scalability of services for low-bandwidth output data
- Content delivery and caching: Fog computing can optimize performance for high-volume video streaming and improve service scalability for low-bandwidth output data. Similarly, the caching technique can be better implemented within the fog nodes to save the bandwidth further and reduce latency for content delivery
- Mobile big data analytics: Fog computing provides an alternative solution to traditional cloud computing by offering scalable resources that can be utilized for large data processing systems without the drawback of high latency
6. Potential Issues
While the benefits of fog computing are attractive, it is important to be aware of and understand the various challenges of its use and deployment. In addition to the challenges inherited from cloud computing, there are also fog-specific issues. In what follows, we’ll look at the specific issues of fog computing.
6.1. Security and Privacy
Another security concern in fog computing is the protection of data privacy and confidentiality. As fog nodes collect and process sensitive data from IoT devices, it is important to protect this data against unauthorized access and misuse. Additionally, using multiple fog nodes in a network can lead to complex security management and maintenance, making it difficult to ensure that all fog nodes comply with security policies and regulations. Finally, using virtualized infrastructure in fog nodes can introduce new security challenges, such as vulnerabilities in hypervisors and virtual machine (VM) migration.
6.2. Fog Networking
Managing a heterogeneous fog network located at the edge of the network, particularly in large-scale IoT scenarios, is challenging due to the difficulties in maintaining connectivity and providing services. Emerging techniques such as software-defined networking, network function virtualization, and network slicing are proposed to create a flexible and easily maintained network environment. Employing these techniques can improve the implementation and management of a heterogeneous fog network, increase its scalability, and reduce costs in various aspects of fog computing, including resource allocation, virtual machine migration, traffic monitoring, application-aware control, and programmable interfaces.
6.3. Quality of Service (QoS)
QoS is an important metric for fog service and can be divided into four aspects: connectivity, reliability, capacity, and delay. For instance, latency-sensitive applications, such as streaming mining or complex event processing, typically require fog computing for real-time streaming processing instead of batch processing.
6.4. Interfacing and Programming Model:
To make it easier for developers to transfer their applications to the fog computing platform, a unified interface and programming model are crucial for designing fog computing systems. Unfortunately, existing programming models tend to be based on a tree-like network structure where nodes have a fixed location. This limits their usefulness in diverse networks where fog nodes are mobile and change position frequently.
The combination of fog and cloud computing results in a three-layer system consisting of devices, fog, and cloud. Performing computation in such an infrastructure presents new challenges and opportunities, such as determining the appropriate level of granularity for offloading, deciding how to partition applications across different levels of fog and cloud dynamically, and adapting to changes in the network, fog devices, and resources.
6.5. Computation Offloading and Resource Management:
The main difficulty in performing these tasks is dealing with the dynamic nature of network resources and node mobility. The federation of fog and cloud actually presents us with a three-layering construction: device-fog-cloud. Computation offloading in such infrastructure faces new challenges and opportunities. There are questions such as which granularity to choose for offloading at the different hierarchies of fog and cloud; how to dynamically partition applications to offload on fog and cloud; and how to make offloading decisions to adapt dynamic changes in the network, fog devices, and resources.
7. Conclusion
Fog computing can address the unsolved issues in cloud computing (e.g., unreliable latency, lack of mobility support, and location awareness) by providing elastic resources and services to end users at the edge of network. In this brief article, we covered the definition of fog computing, introduced representative application scenarios, and identified various issues we may encounter when designing and implementing fog computing systems.