1. Introduction
Artificial Intelligence (AI) has been undergoing rapid advancements over the past decade, significantly transforming various fields such as image and object recognition, speech recognition, and language understanding. The concept of foundation models is at the forefront of this transformation, marking the beginning of a new era in AI.
In this tutorial, we’ll learn about foundation models, their types, the key components driving their success, practical applications, challenges, and potential solutions.
2. Overview
Foundation models are large-scale AI systems trained on extensive datasets. They can perform a wide range of tasks with remarkable accuracy. Unlike traditional AI models designed for specific tasks, foundation models have a broader scope and can adapt to numerous applications with minimal fine-tuning.
The significance of foundation models lies in their versatility and scalability. They have demonstrated superior performance in many areas, including image and object recognition, speech recognition, and natural language understanding. These models can achieve human-level performance in specific tasks, which makes them invaluable in advancing AI technology.
Traditional AI models often require extensive task-specific training and large, well-labeled datasets. In contrast, foundation models use self-supervised learning and transfer learning to generalize across different tasks. This ability reduces the need for large amounts of labeled data for each new application, streamlines the development process, and expands the potential uses of AI.
3. Types of Foundation Models
Foundation models come in various forms, each designed to tackle specific tasks or a range of tasks:
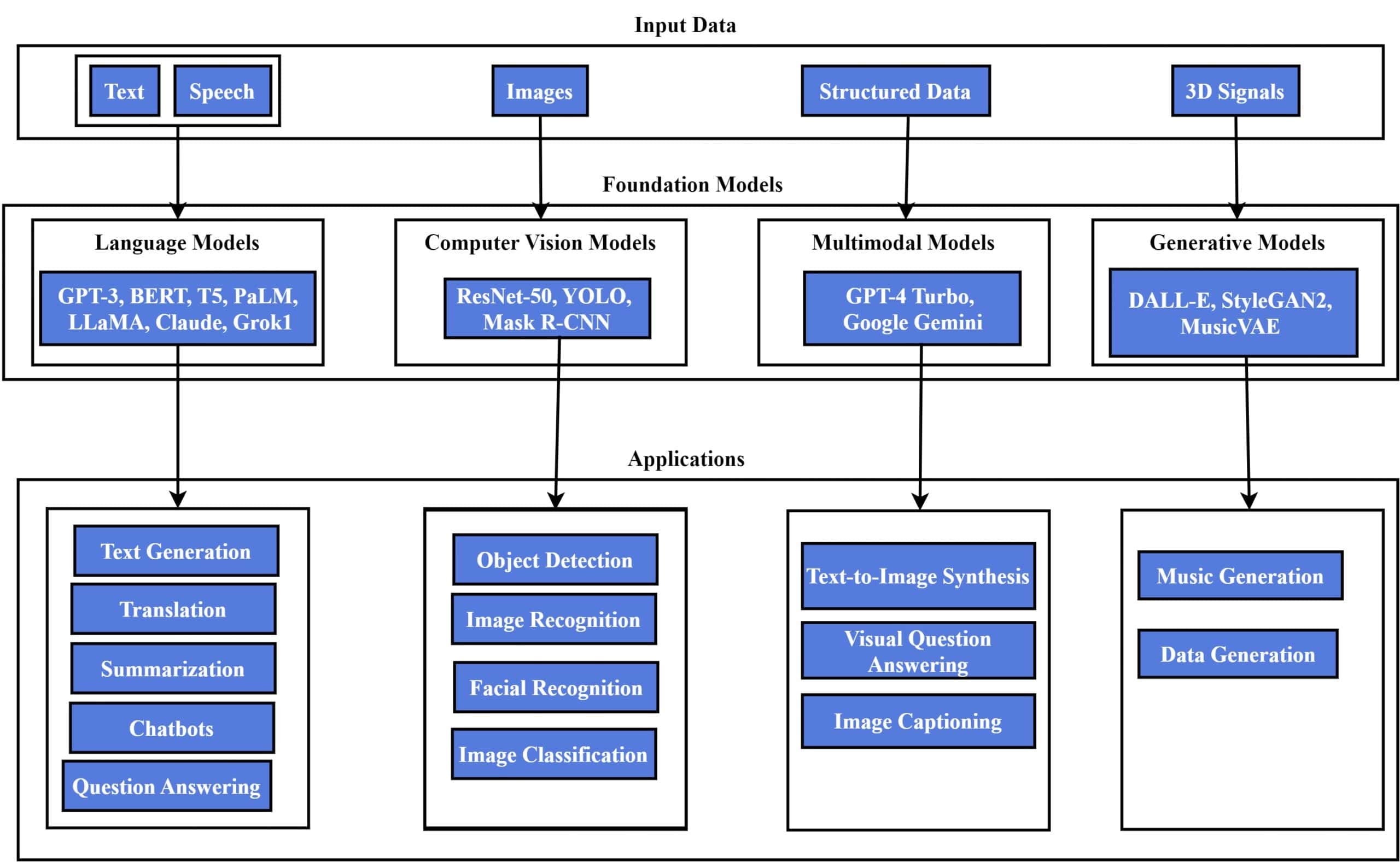
We can divide foundation models into multiple categories based on their data sources, training processes, and applications.
3.1. Language Models
Language models can understand and generate human language. These models are typically trained on vast corpora of text data, including books, articles, and websites. Examples include:
- GPT-3 and GPT-4 (Generative Pre-trained Transformers): These models are part of the broader GPT family, which includes its predecessors like GPT and GPT-2. We use GPT-3 and GPT-4 for text generation, translation, summarization, and question answering. It’s trained on diverse textual data from the Internet.
- BERT (Bidirectional Encoder Representations from Transformers): BERT is ideal for sentiment analysis, text classification, and named entity recognition. BERT is pre-trained on the text of Wikipedia and BooksCorpus.
- T5, PaLM, LLaMA, Claude, Grok1: These models handle a variety of natural language processing tasks by being trained on extensive datasets of written language.
3.2. Computer Vision Models
Computer-vision models focus on understanding and processing visual information. They are trained on large datasets of labeled images and videos. Some specific examples of foundational computer vision models include:
- ResNet-50 and ResNet-101: These models are developed by Microsoft. These models are iterations of Residual Networks that are well-known for their deep-learning capabilities in image recognition. This model is trained on image ImageNet.
- YOLO (You Only Look Once): YOLO is effective for real-time object detection. It was trained on the COCO dataset, which contains labeled images of objects.
- Mask R-CNN (Mask Region-based Convolutional Neural Networks): An extension of the R-CNN framework, Mask R-CNN is specifically designed for object instance segmentation. It combines the efficiency of R-CNNs with accuracy for object detection and segmentation. It is trained on datasets like PASCAL VOC and COCO.
3.3. Multimodal Models
Multimodal models handle multiple types of data inputs, such as text and images, to perform tasks that involve integrating different data modalities such as, textual, visual, or auditory. Examples include:
- GPT-4 Turbo: GPT-4 Turbo integrates text and image data for training. It’s capable of answering visual questions and creating image captions.
- Google Gemini: This model can perform text-to-image synthesis and other multimodal tasks. It uses datasets that include both text and visual elements.
3.4. Generative Models
Generative models generate new data instances that resemble the input data used for training. These models can generate text, images, music, and other types of content. It is important to understand that not all generative AIs are foundation models. Some generative models are designed on top of foundation models for a specific purpose. Examples include:
- DALL-E: Developed by OpenAI, DALL-E can create images from textual prompts. It is trained on a large dataset consisting of text-image pairs.
- StyleGAN2 and StyleGAN3: These are iterations of Generative Adversarial Networks developed by Nvidia. They are known for their applications in digital art and synthetic data creation and are used to generate photorealistic images. These models are trained on image datasets, such as FFHQ (Flickr-Faces-HQ) and LSUN.
- MusicVAE: MusicVAE is a specific implementation of Variational Autoencoders tailored to generate musical sequences. The model is trained on large datasets of music files.
4. Key Components and Techniques
Now that we know about different types of foundation models, let’s examine their critical components.
4.1. Transformer Architecture
The transformer architecture is a crucial driver behind the success of foundation models. Initially developed for natural language processing, transformers use an attention mechanism to efficiently model dependencies between tokens in input and output data. This architecture has proven to be highly scalable and adaptable, extending its applications beyond text to images, videos, and audio.
For example, both BERT and GPT-3 are built on Transformer architecture. We can use BERT for tasks like question answering and sentiment analysis, while GPT-3 can generate human-like text based on prompts, demonstrating the flexibility and power of Transformers.
4.2. Scale
Scaling is another crucial factor in the effectiveness of foundation models. By increasing the model size and the volume of training data, we can achieve significant performance improvements. More comprehensive models with additional parameters and diverse datasets have displayed emerging capabilities, where new abilities become apparent as the model increases in size.
For instance, GPT-3 has 175 billion parameters, making it one of the most significant models ever created. Its size enables it to perform different tasks, from writing essays and generating code to translating languages and answering questions. This scale allows the model to understand and generate text with high accuracy.
4.3. In-Context Learning
In-context learning represents a paradigm shift that allows models to perform new tasks using prompts without additional training. This capability reduces the reliance on large, task-specific datasets and enables models to adapt quickly to various applications.
The extensive training on various datasets helps foundation models develop a broad and deep understanding of different tasks and contexts. These models can be used across different applications with minimal fine-tuning. The diverse training data allows the models to build a rich repository of knowledge and patterns, which they can use to perform new tasks through prompt-based learning.
In GPT models, learning in prompt mode involves using the patterns and information acquired during their extensive pre-training. When we provide a prompt, the model uses its pre-existing knowledge to understand the context and generate an appropriate response. This process involves recognizing the structure of the task described in the prompt and applying relevant aspects of its training to perform the task accurately.
A prime example of in-context learning is the ability of GPT-3 and GPT-4 to generate code snippets based on a given prompt. Instead of retraining the model for each specific task, users provide a prompt, and the model leverages its pre-existing knowledge to perform the task accurately.
5. Practical Applications of Foundation Models
Foundation models have transformed numerous industries with their versatility and advanced capabilities.
5.1. Natural Language Processing
Foundation models have revolutionized natural language processing. We see their impact in chatbots, virtual assistants, and translation services. For example, OpenAI’s GPT-3 powers advanced chatbots that engage in human-like conversations. Similarly, translation services like Google Translate use foundation models to provide accurate translations across multiple languages.
One notable application is GitHub Copilot, an AI-powered code completion tool that uses GPT-3 to help developers write code more efficiently. By understanding the context of the code we are writing, Copilot can suggest entire lines or blocks of code, significantly speeding up the development process and reducing errors.
5.2. Image and Video Analysis
Foundation models make significant strides in image and video analysis. Models such as DALL-E 2 can produce high-quality images based on textual descriptions, creating new opportunities in design, advertising, and entertainment.
Similarly, models trained on vast datasets of video content perform tasks like video summarization, object detection, and content moderation.
For instance, autonomous vehicles rely heavily on image recognition models to navigate and make decisions in real time. These models identify objects, pedestrians, and traffic signals with high accuracy, contributing to the safety and efficiency of self-driving cars. The foundational aspect lies in their ability to use extensive pre-training on diverse datasets so that they can perform well in various driving conditions without task-specific fine-tuning.
5.3. Code Generation and Debugging
Foundation models show remarkable capabilities in generating and debugging code.
These models assist us in writing, optimizing, and debugging our code as they are trained on extensive datasets of code from various programming languages.
GitHub Copilot exemplifies how we can integrate these models into development tools to enhance productivity. Here’s an example of a prompt asking for a Python function to sort a list results in the model generating the appropriate code:
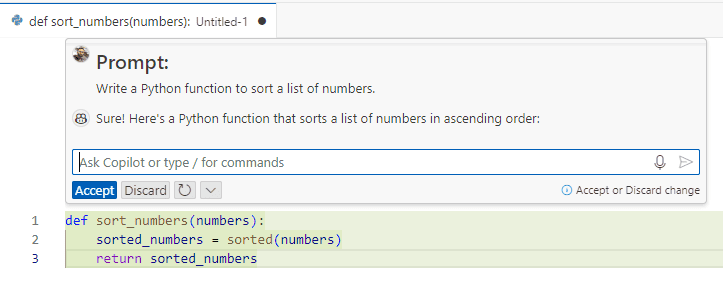
As we can see, the model generated an accurate code.
5.4. Healthcare and Drug Discovery
In healthcare, we can use foundation models for diagnostics and drug discovery. These models can identify patterns and make highly accurate predictions.
For example, AI models trained on medical images help radiologists detect abnormalities such as tumors or fractures. These AI models perform effectively because they can generalize from extensive training data, allowing them to interpret new, unseen medical images accurately and provide reliable diagnoses.
5.5. Financial Services
Foundation models benefit the financial sector through applications in fraud detection, risk assessment, and sentiment analysis.
These models analyze large financial datasets to detect suspicious activities and predict potential risks.
Sentiment analysis models assess market sentiment by analyzing news articles, social media posts, and other textual data, assisting in investment decisions.
6. Challenges
While foundation models have made remarkable progress, they also present several challenges that we need to address to get the full potential advantages of AI:
Challenges
Potential Solutions
Reliability and Safety
Develop robust testing and validation frameworks to ensure models behave as expected in diverse scenarios.
Bias and Fairness
Implement techniques to detect and mitigate bias in AI systems to prevent discriminatory outcomes.
Resource Consumption
Optimize training methods and model architectures to reduce energy consumption and carbon footprint.
Trust and Transparency
Enhance transparency with explainable AI techniques to help users understand model decisions and build trust.
To ensure reliability and safety, we need robust testing and validation frameworks that guarantee consistent performance across diverse scenarios. For bias and fairness, it’s crucial to implement techniques that detect and mitigate biases, ensuring AI systems produce fair and ethical outcomes.
We need to optimize the training methods to reduce resource consumption and environmental impact, focusing on energy efficiency and sustainability. We also need to enhance the explainability of AI models to build trust and transparency. This will help users understand how these models make decisions.
7. Conclusion
In this article, we learned about the transformative power of foundation models in artificial intelligence. These large-scale models, trained on vast datasets, excel in tasks like natural language processing, image and video analysis, and code generation.
We’ve explored their vital components, such as transformer architecture, scaling, and in-context learning, which contribute to their success. Practical applications demonstrate their impact in areas like healthcare, financial services, and software development. However, we must address challenges related to reliability, bias, resource consumption, and transparency.