1. 简介
在本教程中,我们将学习如何为一个图结构指定一个根节点,从而将其转换为一棵有向的树结构。
2. 树、图与根节点
通常,树是一种层次结构,其中有一个节点被指定为根节点:
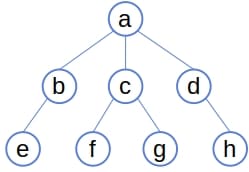
根节点是整个树的入口点,通过它我们可以访问树中的所有其他节点,只需沿着父子关系的边遍历即可。
然而,有时候树结构是以图的形式存储的,也就是说它没有明确的根节点,而是以邻接表或邻接矩阵的形式表示。
我们的目标就是将这样的图结构转换为一棵以指定节点为根的树。
3. 为树结构指定根节点
要将节点  设为根节点,我们可以使用 深度优先搜索(DFS) 从该节点出发遍历所有节点:
设为根节点,我们可以使用 深度优先搜索(DFS) 从该节点出发遍历所有节点:
algorithm RootTree(neighbors, r):
// INPUT
// neighbors = 返回图中节点邻居的函数
// r = 想要设为根的节点
// OUTPUT
// T = 一棵以 r 为根、包含图中所有节点的树
T <- 创建一个空树
T.root <- r
leaves <- 创建一个空栈
leaves.push(T.root)
while leaves 不为空:
u <- leaves.pop()
for v in neighbors(u):
将 v 添加为 u 的子节点
leaves.push(v)
return T
这里的  栈用于保存当前的候选叶子节点,也就是我们尚未探索其子节点的节点。每次我们从栈中取出一个节点,检查它的所有邻居,并将这些邻居设为它的子节点并压入栈中。
栈用于保存当前的候选叶子节点,也就是我们尚未探索其子节点的节点。每次我们从栈中取出一个节点,检查它的所有邻居,并将这些邻居设为它的子节点并压入栈中。
一旦我们遍历完所有节点,就能得到一棵覆盖整个图的树。
3.1 示例
假设我们想将以下图结构以节点 5 为根进行树化:
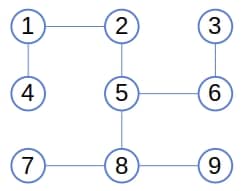
初始时,栈中只有根节点 5。接着我们取出它,访问其邻居节点 2、6、8,并将它们加入树中并压入栈中。然后依次取出这些节点并重复该过程,最终得到如下树结构:
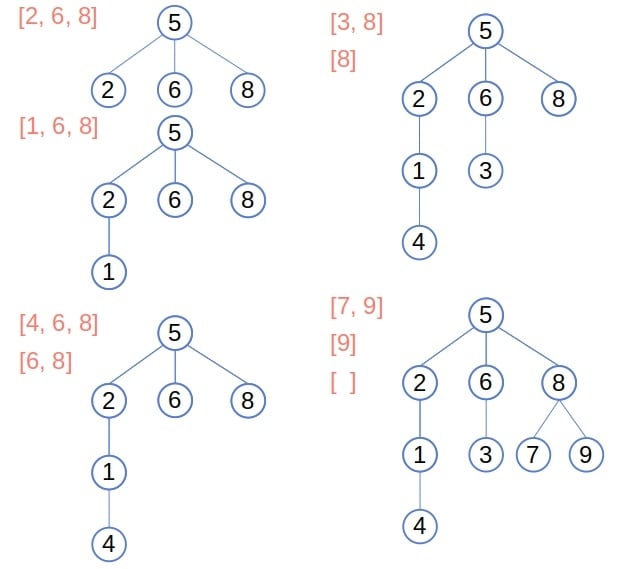
当栈为空时,算法结束。
3.2 时间与空间复杂度分析
设  为一个节点最多拥有的子节点数,
为一个节点最多拥有的子节点数, 为节点总数。
为节点总数。
✅ 如果使用邻接表:
- 每条边会被访问两次(父到子、子到父),每个节点最多被访问 次。
- 如果 是常数,则时间复杂度为
 。
。 - 空间复杂度也为 。
❌ 如果使用邻接矩阵:
- 存储空间为
 。
。 - 每次调用
neighbors(u)需要遍历整行,时间复杂度也为。
4. 潜在问题
我们的算法假设根节点已经选定,但实际中:
✅ 建议选择树的中心节点作为根节点,这样可以最小化树的高度,提高遍历效率。
✅ DFS 只适用于无环图。如果输入中存在环,DFS 会陷入死循环。为避免这一点,我们可以为每个访问过的节点做标记。
❌ 如果图是非连通的,那么构造出的树只会覆盖根节点所在连通分量的节点,其余部分不会被包含。
5. 小结
本文我们介绍了如何使用深度优先遍历为一个图结构指定根节点,从而构建一棵树。该方法的时间复杂度为 。
⚠️ 但需要注意:该方法仅适用于树结构的图(即无环且连通),否则需要进行额外处理。