1. Introduction
Considering how quickly natural language processing methods have been advancing, it is now more important to develop good language models than before. These models are used in various AI applications.
Therefore, a knowledge of the evaluative metrics that NLP researchers use to compare language models with each other might come in handy. A metric known as perplexity has been subject to praise and attention.
In this tutorial, we’ll cover mathematical foundations, a practical use case, and how it helps us understand the performance of language models. Along the way, we’ll also touch on the limitation of perplexity, and how we can combine it with other evaluation metrics to get a better picture of a model’s capabilities.
2. Unraveling the Concept of Perplexity
Perplexity is a quantity used in probabilistic model inference to measure how well a probability distribution predicts a sample. It’s the exponentiation of the entropy of the distribution, which tracks the average number of bits required to encode the samples.
For a given probability distribution  over a sequence
over a sequence  , the perplexity is calculated as
, the perplexity is calculated as  , where
, where  is the entropy.
is the entropy.
In the context of language models, it’s the exponentiation of the average negative log-likelihood of a sequence of words. For a given language model, it’s defined as:
![[ \text{PPL}(W) = P(W)^{-\frac{1}{N}} ]](/wp-content/ql-cache/quicklatex.com-2e8c1d2d0cbfdca1ad4afe669b0970f2_l3.svg "Rendered by QuickLaTeX.com")
where  is a sequence of words,
is a sequence of words,  is the probability assigned to the sequence by the language model, and
is the probability assigned to the sequence by the language model, and  is the total number of words in the sequence.
is the total number of words in the sequence.
Intuitively, it’s just the weighted branching factor of the language model, which is the geometric mean of the number of next tokens that the model thinks might be good at each point. Lower perplexity means the model is predicting better, assigning a higher probability to the correct tokens. Higher perplexity means the model is less certain about the sequence.
3. Pseudo-Code and Visual Representation for Calculating Perplexity
To get a sense of how perplexity is computed, consider the following pseudo-code:
function cal_perpl(model, t_data):
t_log_proba = 0
n_tok = 0
for seq in t_data:
log_proba = 0
for tok in seq:
log_proba += log(model.predict_proba(tok, context))
n_tok+= 1
t_log_proba += log_proba
avr_log_proba = t_log_proba / n_tok
perplexity = exp(-avr_log_proba)
return perplexity
To calculate perplexity, we first need to initialize counts for the total log probability and the number of test tokens to get started. This setup allows us to compute the average log probability later. We then iterate on the sequences in the test data to process one sequence at a time. This ensures that the context-dependent predictions preserve their integrity.
We start by making a variable that keeps track of the log probability for the sequence, then run a loop to iterate over the sequence tokens. For each token, we run the language model’s prediction function to gather the log probability of that token given the context (in this case, the context is just the previous tokens).
We then add this value to the cumulative log probability of the sequence and increment the counter for the number of tokens. In that way, we can capture the probability contribution from each token.
We calculate the arithmetic average value of log probability in all the sequences by dividing the sum of all the values of log probability by the total number of tokens. Finally, we define perplexity by taking the exponent of the negative average log probability.
We perform the exponentiation to transform the log probability scale back to a more comprehensible scale. Then, we can return the perplexity, which tells us how well our language model can predict the test data.
The visualization below provides a process used to compute perplexity according to the above-mentioned description:
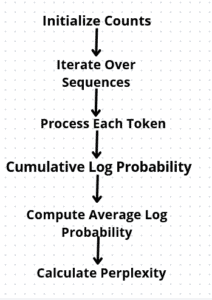
The above image exemplifies the process step at a time from starting with counts initialization to iterating through sequences and tokens. It computes log probabilities and associates them with perplexity which is finally returned.
4. Interpreting Perplexity Scores
Suppose that we’re dealing with the perplexity scores produced by a language model trained on a corpus of English text. We want to test that model’s performance on a held-out test set. If the perplexity score for this test set is 100, it means that, on average, for any position in the sequence, the model’s probability for the correctly generated next token is 1/100 (or 0.01). This reflects a relatively high level of uncertainty or perplexity in the model’s predictions.
Thus, a perplexity score of 1 would indicate that the model is perfectly certain about the sequence (by giving the right tokens a probability of 1 at all positions), but in practice this is unrealistic. Language models will always be probabilistic and need to account for the inherent ambiguity and variation of natural language.
5. Limitations and Complementary Metrics
While perplexity is popular and quite useful as a metric, it has some theoretical flaws. The first is fairly trivial: while it quantifies the probability of the observed sequence of tokens (or words), it does not quantify anything else meaningful about natural language, like semantic coherence, pragmatic appropriateness, or text quality.
A high probability given by a language model to a sequence of words could be purely syntactic. It might be a chain of words that appears elegant but is inadequate for some other reason relating to meaning or pragmatics within the context. The score assigned for perplexity will be low, but the text that will be generated will be a piece of drivel from a human point of view.
Perplexity is not used in isolation because of several limitations but is typically paired with other evaluation metrics and human judgments. These include:
- BLEU score for machine translation
- Semantic similarity metrics like cosine similarity or word mover’s distance, allow us to compare sentences for their meaning preservation
- Human evaluation is an excellent gold standard for determining naturalness and appropriateness
- Task-specific metrics like F1 score, exact match for question-answering, or diversity/novelty metrics for open-ended generation
Perplexity has other failings. It’s highly sensitive to vocabulary discrepancies, so models with different vocabulary sizes can sometimes not be fairly compared. It’s not possible to compare perplexity scores between datasets, as one dataset may naturally have higher perplexity than another.
It’s a poor metric by which to evaluate a model’s handling of ambiguity and creativity because it favors training data-like outputs over more novel interpretations or generations. Consequently, sentences generated by the model would be overly constrained to reproduce that training data, rather than handling ambiguity or generating novel creative text.
complementing perplexity with other complementary metrics can give researchers and developers a better sense of how a given language model performs.
6. Practical Use Case: Evaluating Language Models for Conversational AI
An important component of conversational AI is a language model, where the text generated by the algorithm is conversational and sounds like text generated by humans. Suppose we’re building several language models using a neural network trained on an extensive corpus of conversational data.
These data can include threads of complaints or questions and answers posted by human users in forums. We can consider the following factors while developing our chatbot:
- To determine which of these models is likely to be the appropriate one for this conversational AI application, we could compute all of the models’ perplexity scores on a held-out test set of conversational data
- The model with the smallest perplexity score is probably going to perform better. As a result, it could provide conversational answers that are smoother and more human-sounding
- However, we might not be comfortable that perplexity is sufficient to produce high-quality conversational AIs. It does not directly measure factors such as coherence, relevance, and appropriateness of the response
- Therefore, we could decide to use it with other measures of what constitutes a good quality signal. Such measures could include human judgments of the quality of the response
- Additionally, we can consider task-relevant metrics such as the percentage of actions completed successfully if we’re building a virtual assistant
- We can also incorporate user engagement metrics such as the length of the utterance, or user-mood ratings
- Putting perplexity in the mix with these other metrics will provide a fuller picture of how the model that generated this language is performing
Based on this comprehensive evaluation, we can then decide which model to deploy into our conversational AI application.
7. Exploring Advanced Techniques for Perplexity Calculation
The formula for computing perplexity is well-known. However, much work in Computational Linguistics revolves around various extensions that can make it more accurate (and hence, applicable to larger training corpora).
In the context of language modeling, it’s the importance of sampling techniques that reduce the computational cost of perplexity calculations on large data sets. To reduce the computational burden, we can consider the following factors:
- We should apply this technique, weighted by sample importance or relevance. We have to calculate perplexity only over a subset of the test data. It’s critical to weigh each sample by a factor of importance (or ‘relevance’ to the model). Using this kind of so-called importance sampling, we can achieve an accurate measure of perplexity for large language models and data sets
- In our conversational AI setting, to assess which model is the best, we can measure their perplexity over the test set of conversational data. However, it’s expensive to compute over the entire test set, especially with larger language models and datasets. This is where importance sampling can be useful
- Instead of the complete test set, our sampled subset of conversational data will be drawn from an importance distribution. We’ll assign the weights according to each sample’s ‘importance’ to the language model being evaluated. The weights assigned to each sample reflect the extent to which they represent the kinds of conversational patterns that the model must correlate with
An example of more sophisticated methods involves hierarchical (or multi‑level) perplexity computation. Instead of computing perplexity over the entire corpus all at once, this method computes it at different levels of granularity. These levels include words, phrases, and sentences. This provides a detailed evaluation of the model and helps diagnose the issues.
For our conversational AI system, rather than providing an overall perplexity for each model on the test set, we can decompose it across levels:
- Word-level perplexity – Compute word-level perplexity for all the models over the test set conversations. This indicates how well the models can predict individual words in conversational contexts
- Phrase-level perplexity – Calculate it for commonly used phrases and multi-word expressions encountered in conversations. This evaluates the extent to which models can capture meaningful units of language beyond single words
- Sentence/utterance-level perplexity – Compute this metric scores for entire sentences or conversation in the test set. This gives a coherence measure over longer contexts
Using these multi-level perplexity scores, we can map out the strengths and relative weaknesses of each model at different granularity levels.
8. Conclusion
In this article, we have learned about ‘Perplexity’, which offers a metric for assessing how well language models are performing on linguistic tasks.
It’s a common metric and represents an accepted standard by which LMs from different engineers and codebases can be compared with each other.
However, this is far from perfect and doesn’t provide information about more subtle aspects of human-sounding text. To conclude, every metric has its limits, and perplexity is no exception. All the other approaches described in the article are complementary to each other.