1. 引言
本文将深入分析两种经典的文本分类算法:朴素贝叶斯(Naïve Bayes,NB) 和 支持向量机(Support Vector Machine,SVM)。我们将从理论和实践两个角度对比它们的优缺点,并探讨在不同场景下应优先选择哪种方法。
在分析过程中,我们会关注以下几个关键因素:
- 训练样本和实际应用数据的数量
- 待分类文本的长度
- 分类类别数量
- 预处理流程等
目标是帮助有经验的开发者在面对文本分类任务时,做出更合理的模型选择。
2. 朴素贝叶斯(Naïve Bayes)分类器
朴素贝叶斯是一种基于贝叶斯定理的简单分类器,其核心假设是:所有特征之间相互独立。
这种假设虽然“朴素”,但在很多实际应用中效果出奇地好,尤其在文本分类任务中表现优异。
优点:
✅ 训练速度快:由于不考虑特征之间的相关性,NB只需学习每个特征与类别的独立关系,复杂度大大降低
✅ 适合小数据集:对训练样本量要求低,适合数据量有限的场景
✅ 抗高维灾难能力强:文本数据通常维度极高,NB表现稳定
缺点:
❌ 特征独立性假设可能不成立:实际文本中词语之间存在语义关联,NB无法建模这种关系
❌ 对输入数据分布敏感:若数据不符合模型假设(如多项式NB假设词频服从多项分布),效果会下降
时间复杂度:
朴素贝叶斯的时间复杂度为 O(NK),其中 N 是特征数量,K 是类别数量。
示例代码:
// 示例:使用Sklearn训练一个朴素贝叶斯分类器
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
y = labels
model = MultinomialNB()
model.fit(X, y)
3. 支持向量机(Support Vector Machine, SVM)
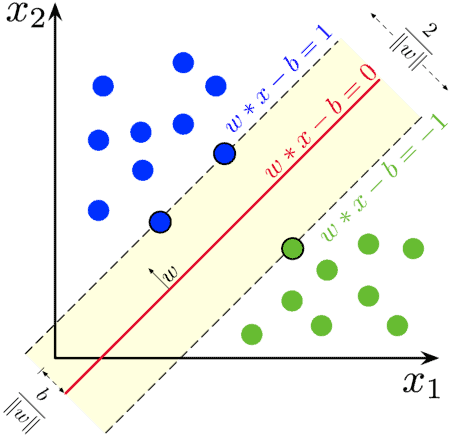
SVM 是一种非常流行的分类模型,其核心思想是通过几何方式寻找一个最优超平面,将不同类别的数据尽可能清晰地分开。
核心概念:
- SVM 默认是二分类器
- 将数据映射到高维空间,寻找一个 N-1 维的超平面来分割 N 维数据
- 寻找最大间隔超平面(maximum margin hyperplane),以提升模型的泛化能力
- 使用支持向量(support vectors)来定义这个超平面
处理非线性问题:
当原始空间无法线性分割时,SVM 使用 kernel trick(核技巧) 将数据映射到更高维空间,从而实现非线性分类。
常用核函数包括:
- 线性核(Linear)
- 多项式核(Polynomial)
- 高斯核(RBF)
优点:
✅ 高维空间表现优异:非常适合处理高维稀疏的文本数据
✅ 泛化能力强:通过最大间隔策略,减少过拟合风险
✅ 支持多类分类:虽然本质是二分类,但可通过组合方式实现多类分类
缺点:
❌ 训练耗时长:尤其在大规模数据集上,训练时间显著增加
❌ 参数调优复杂:需要选择合适的核函数和超参数(如 C、gamma),调参过程耗时且需要经验
❌ 对噪声敏感:异常值可能影响支持向量的选择,进而影响分类效果
示例代码:
from sklearn.svm import SVC
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(texts)
y = labels
model = SVC(kernel='linear', C=1.0)
model.fit(X, y)
4. NB 与 SVM 的对比分析
| 特性 | Naïve Bayes | SVM |
|---|---|---|
| 训练速度 | ✅ 极快 | ❌ 慢,尤其在大数据集 |
| 适用数据规模 | ✅ 小数据集友好 | ⚠️ 更适合中等规模数据 |
| 维度容忍度 | ✅ 高维数据表现好 | ✅ 非常适合高维数据 |
| 分类能力 | ✅ 支持多类分类 | ✅ 支持多类分类 |
| 调参难度 | ✅ 简单 | ❌ 复杂 |
| 对特征相关性敏感 | ❌ 敏感(假设特征独立) | ✅ 不敏感 |
| 模型理论基础 | ✅ 概率模型 | ✅ 几何模型 |
实际表现对比:
- 有研究表明,在垃圾邮件分类任务中,朴素贝叶斯在未调参的情况下达到了 97.8% 的准确率,优于 SVM
- 但在合理调参后,SVM 也能达到 90% 以上的准确率
- 总体来看,SVM 在理论上更强大,但 NB 更实用、更轻量
5. 总结与建议
没有一种分类器在所有场景下都优于另一种。选择 NB 还是 SVM,应根据以下因素综合判断:
✅ 数据量较小 ➜ 优先考虑 NB
✅ 需要快速部署、轻量模型 ➜ 优先考虑 NB
✅ 特征维度极高但样本量有限 ➜ SVM 更合适
✅ 有调参时间和资源 ➜ SVM 更有潜力
在实际项目中,建议:
- 先用 NB 快速验证效果
- 再尝试 SVM 调参优化
- 根据最终性能指标选择最终模型
📌 踩坑提醒:不要迷信“SVM 更高级”,在数据量有限、时间紧张的情况下,朴素贝叶斯往往更实用。也不要低估 NB 的表现力,它在文本分类中依然非常有竞争力。
参考资料: