1. 简介
在本篇文章中,我们将深入讲解随机变量的概念,它是概率论与统计学中的核心工具之一。简单来说,随机变量是对随机事件的数值化描述,它帮助我们以数学的方式分析不确定性。
2. 基础概念
我们假设  是一个随机过程的所有可能结果组成的集合,称为样本空间(Sample Space)。例如抛一枚硬币的样本空间是:
是一个随机过程的所有可能结果组成的集合,称为样本空间(Sample Space)。例如抛一枚硬币的样本空间是:
$$ \Omega = {H, T} $$
如果抛四次硬币,样本空间将包含 $2^4 = 16$ 个结果:

一个事件(Event)是样本空间的一个子集。例如:

当我们为这些事件赋予一个概率 $P$,我们就得到了一个概率空间(Probability Space)。这个概率函数 $P$ 将事件映射到区间 $[0, 1]$ 上。而随机变量正是在这个框架下,用来将事件映射为数值的工具。
2.1 随机变量的定义
通常,我们更关心事件所代表的数值而非其具体形式。例如抛100次硬币时,我们可能只关心出现多少次正面,而不关心具体序列。
因此,随机变量是事件的数值化表示。它不是任意的数值,而是反映我们关心的量。
形式上,一个随机变量 $X$ 是从样本空间 $\Omega$ 到实数集 $\mathcal{B}$ 的映射:
$$ X: \Omega \to \mathcal{B} $$
通过概率函数 $P$,我们可以推导出 $X$ 取值于 $\mathcal{B}$ 的概率分布 $P_X$。
例如,若硬币是公平的,我们可以定义 $X$ 为四次抛掷中正面的个数,其概率分布为:
$$ \begin{pmatrix} 0 & 1 & 2 & 3 & 4 \ \frac{1}{16} & \frac{1}{4} & \frac{3}{8} & \frac{1}{4} & \frac{1}{16} \end{pmatrix} $$
3. 离散型随机变量
我们称一个随机变量 $X$ 是离散型的,如果它取值的集合是可数的(countable)。
3.1 可数性(Countability)
例如,我们抛硬币直到出现连续两个正面。这个过程所需的抛掷次数构成一个无限但可数的集合:
$$ {2, 3, 4, \ldots} $$
尽管这个集合是无限的,但它仍然是可数的,因此 $X$ 是一个离散型随机变量。
3.2 概率质量函数(PMF)
离散型随机变量的概率分布通常用概率质量函数(Probability Mass Function, PMF)表示。PMF 将每个可能的取值映射到其发生的概率:
$$ p_X(x) = P_X({x}) \quad (\forall x \in \mathcal{B}) $$
我们也可以通过 PMF 计算任意事件的概率:
$$ P_X(E) = \sum_{x \in E} p_X(x) \quad (\forall E \subseteq \mathcal{B}) $$
3.3 累积分布函数(CDF)
累积分布函数(Cumulative Distribution Function, CDF)定义为:
$$ \mathrm{CDF}_X(x) = P_X(X \leq x) $$
对于离散变量,我们通过累加小于等于 $x$ 的所有 PMF 值来计算 CDF:
$$ \mathrm{CDF}X(x) = \sum{z \in \mathcal{B} \mid z \leq x} p_X(z) $$
以四次抛硬币为例,设 $X$ 表示正面的个数,其 CDF 图形如下:
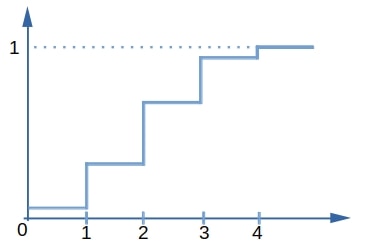
从图中可以看出,CDF 是一个非递减的“阶梯函数”。
3.4 常见离散分布
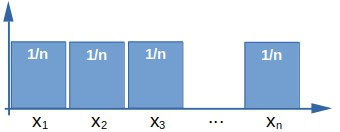
均匀分布(Uniform):所有取值的概率相等
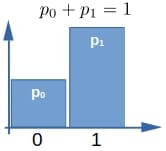
伯努利分布(Bernoulli):只取两个值(通常是 0 和 1)
4. 连续型随机变量
连续型随机变量与离散型最大的区别在于:它取任何一个具体值的概率都是零。
例如,设 $X$ 表示在餐厅等待上菜的时间(单位:分钟),且最大等待时间为15分钟。那么 $X$ 的取值范围是:
$$ X \in [0, 15] $$
由于这个区间内有不可数无穷多个值,每个值的概率趋近于零:
$$ P_X(x) = 0 \quad (\forall x \in [0, 15]) $$
但这并不意味着这些值不可能出现,而是说我们只能讨论某个区间内的概率。
4.1 连续型 CDF
连续型随机变量的 CDF 是一个连续函数,没有跳跃点:
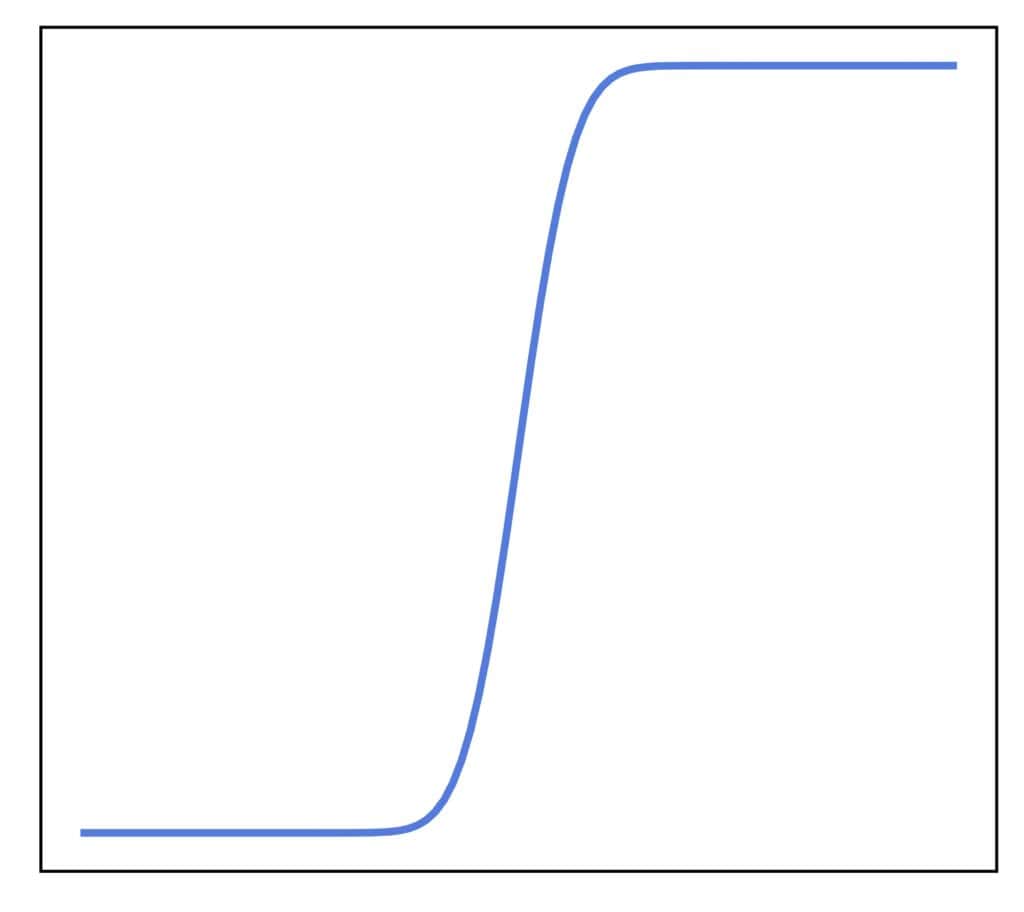
因为每个点的概率为零,所以 CDF 是平滑的,没有离散变量那样的“阶梯”形状。
4.2 概率密度函数(PDF)
如果 CDF 存在导数 $f_X(x)$,则我们称其为概率密度函数(Probability Density Function, PDF):
$$ \mathrm{CDF}X(x) = \int{-\infty}^{x} f_X(u) du $$
PDF 的性质如下:
PDF 的积分在整个实数轴上为 1: $$ \int_{-\infty}^{\infty} f_X(u) du = 1 $$
PDF 本身不是概率,而是概率的“密度”,它反映的是不同取值之间的相对可能性。
4.3 常见连续分布
均匀分布(Uniform):PDF 在区间 $[a, b]$ 上为常数: $$ f_X(u) = \frac{1}{b - a} \quad \text{if } X \in [a, b] $$
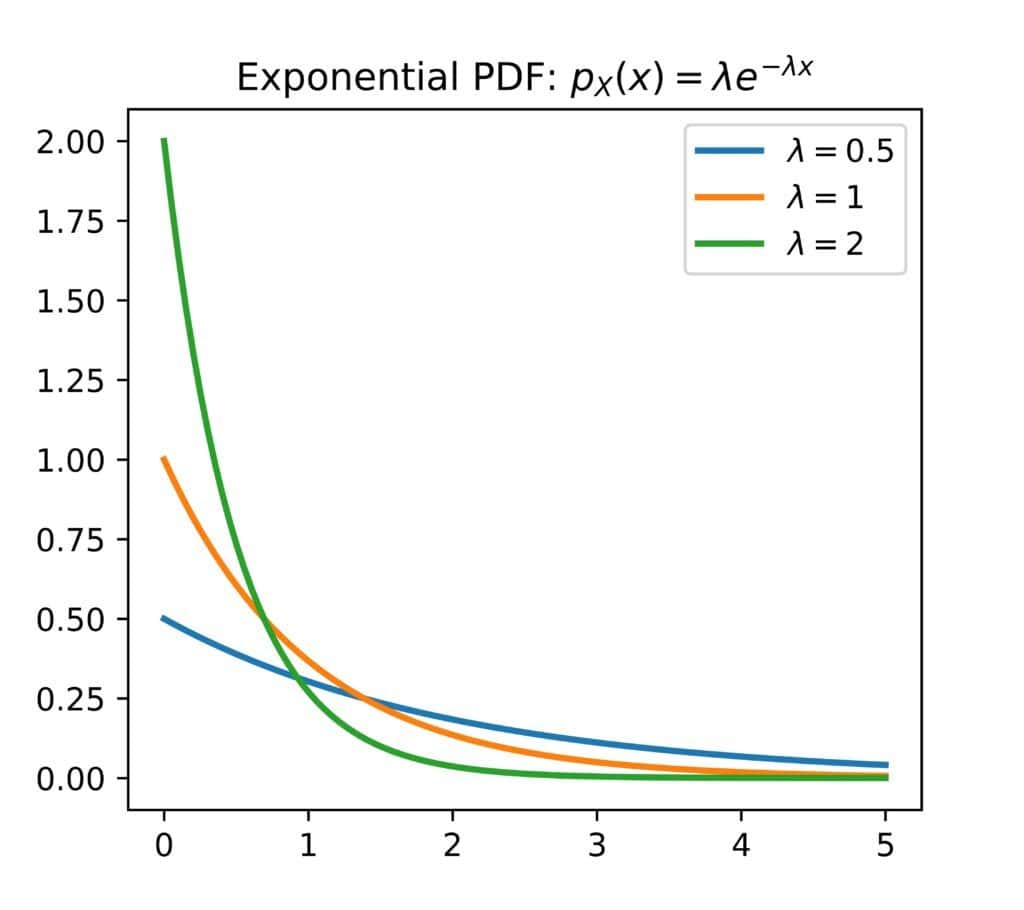
指数分布(Exponential):PDF 随着值增大呈指数衰减,常用于建模等待时间: $$ f_X(x) = \lambda e^{-\lambda x}, \quad x \geq 0 $$
5. 离散 vs. 连续变量对比
| 特性 | 离散型变量 | 连续型变量 |
|---|---|---|
| 取值数量 | 可数个(countable) | 不可数个(uncountable) |
| 概率 | 每个值有正概率 | 每个值概率为 0 |
| CDF 形状 | 阶梯状、非连续 | 平滑、连续 |
| 应用场景 | 通常表示“数量”(如计数) | 通常表示“测量值”(如时间、长度) |
6. 确定性与随机性
在非概率语境中,一个变量代表一个未知但固定的值,它的值不会因随机性而变化。
在编程中,我们也可以对变量进行赋值和更新:
$$ x \leftarrow x + 1 $$
但无论怎么更新,变量在任一时刻都只有一个确定值。
而随机变量则不同,它代表一个随机过程或事件的结果。每次“使用”它时,它会根据其概率分布生成一个不同的值。
6.1 随机性的本质
频率学派观点:随机性是自然界固有的属性。某些过程本身具有随机性,概率函数描述的是长期频率。
贝叶斯学派观点:概率是主观信念的量化表达。它反映的是我们对不确定性的理解,而不是客观规律。
7. 混合型与多变量随机变量
除了离散和连续型变量,还存在混合型随机变量(Mixed Random Variables),其 CDF 由连续部分和阶梯部分组成:
$$ \mathrm{CDF}X(x) = \int{-\infty}^{x} f_X(u) du + \sum_{z_i \leq x} p_X(z_i) $$
其中,$z_i$ 是那些具有正概率的点。
我们前面讨论的都是单变量(Univariate)随机变量。在实际应用中,我们也会遇到多变量(Multivariate)随机变量,它是一个由多个一维变量组成的向量。
8. 总结
✅ 随机变量是将随机事件数值化的工具
✅ 离散型变量有可数个取值,用 PMF 和 CDF 描述
✅ 连续型变量取值不可数,用 PDF 和 CDF 描述
✅ 混合型变量同时包含离散与连续部分
✅ 多变量变量是多个一维变量的组合
通过理解随机变量的性质与分类,我们可以更好地建模和分析现实世界中的不确定性问题。