1. 简介
在本教程中,我们将实现一个伪随机数生成器,该生成器生成服从指数分布的数值。
指数分布常用于建模事件发生前的时间间隔,例如电话通话时长、顾客在超市的消费金额等。这类现象通常表现为:小数值出现频率高,大数值稀少。
2. 指数分布
指数分布有一个参数  ,它决定了数值出现概率下降的速度。
,它决定了数值出现概率下降的速度。
其概率密度函数(PDF)为:
(1) 
其累积分布函数(CDF)为:
(2) 
这些公式说明了概率下降的速度是指数级的,这也是“指数分布”名称的由来。
2.1. 示例
以下是一组超市顾客消费金额的示例分布图:
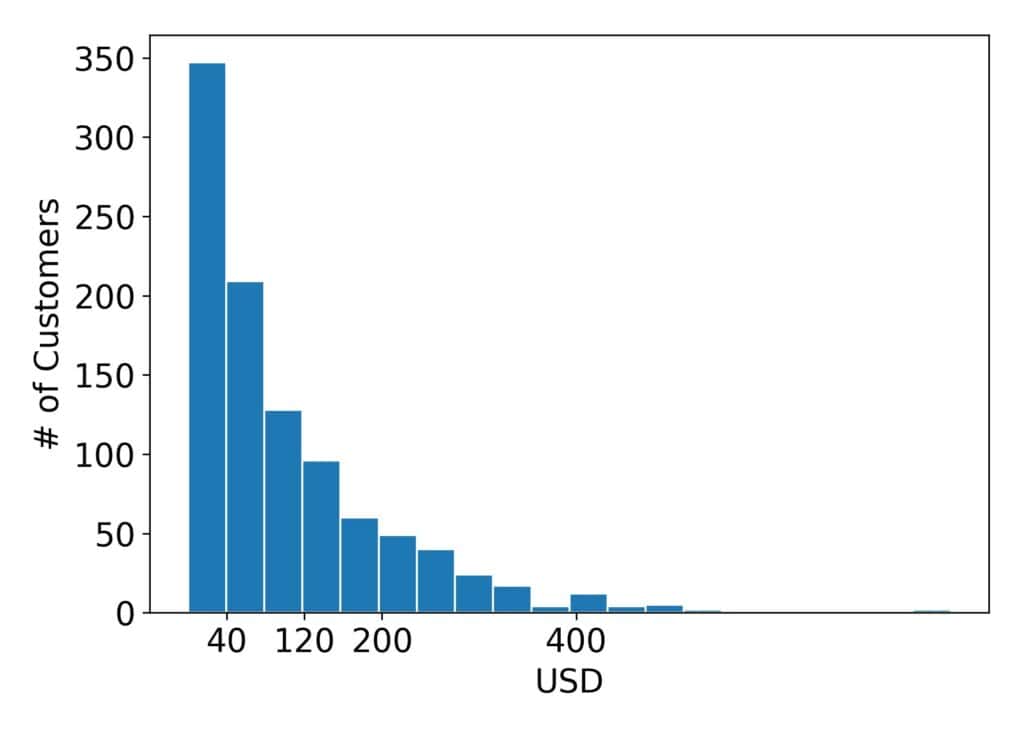
可以看出,大多数顾客消费在40美元以下,而超过1000美元的消费非常罕见。
3. 逆变换采样法(Inversion Method)
逆变换采样法利用了这样一个性质:累积分布函数(CDF)作为一个随机变量来看,服从 [0,1] 上的均匀分布。
这意味着,如果我们从指数分布中采样大量数值,并绘制它们的 CDF 值的直方图,会看到一个均匀分布。
反过来也成立:如果我们从 [0,1] 的均匀分布中采样 n 个值 u₁, u₂, ..., uₙ,然后计算它们在指数分布 CDF 的反函数下的值,就能得到服从 Exp[λ] 分布的样本。
指数分布的 CDF 反函数为:
(3) 
3.1. 伪代码
algorithm InversionMethod(λ, n):
sample <- initialize an empty array
for i <- 1 to n:
u <- draw a random number from U[0, 1]
x <- - (1 / λ) * ln(1 - u)
append x to sample
return sample
✅ 优点:实现简单、效率高
❌ 缺点:依赖于 CDF 可逆
3.2. 示例
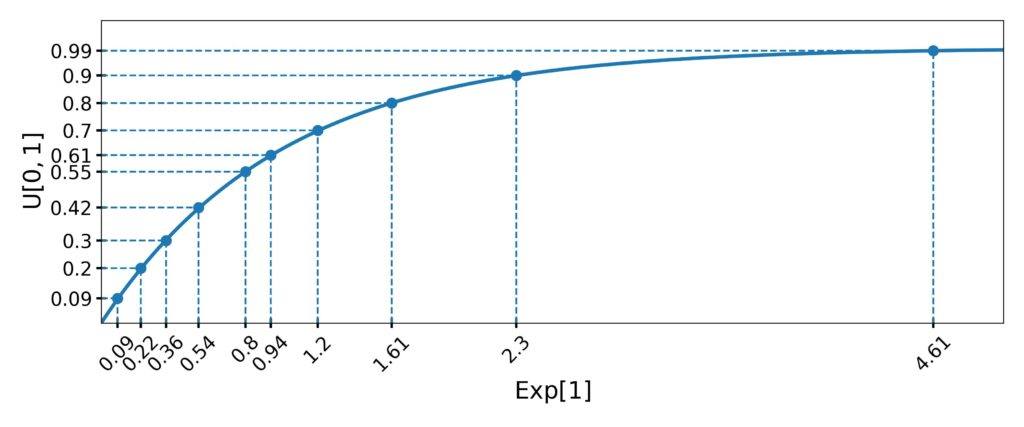
假设我们要从 Exp[1] 中采样10个数,随机生成的 u 值为:
0.09, 0.2, 0.3, 0.42, 0.55, 0.61, 0.7, 0.8, 0.9, 0.99
代入公式计算得:
\begin{aligned}
x_1 &= - \ln(1 - 0.09) = 0.09 \\
x_2 &= - \ln(1 - 0.2) = 0.22 \\
x_3 &= - \ln(1 - 0.3) = 0.36 \\
x_4 &= - \ln(1 - 0.42) = 0.54 \\
x_5 &= - \ln(1 - 0.55) = 0.8 \\
x_6 &= - \ln(1 - 0.61) = 0.94 \\
x_7 &= - \ln(1 - 0.7) = 1.2 \\
x_8 &= - \ln(1 - 0.8) = 1.61 \\
x_9 &= - \ln(1 - 0.9) = 2.3 \\
x_{10} &= - \ln(1 - 0.99) = 4.61 \\
\end{aligned}
最终结果如下图所示:
4. 拒绝采样法(Rejection Sampling)
当 CDF 不可逆或难以计算时,可以使用拒绝采样法。
其核心思想是:
- 在目标分布的 PDF 图像中随机采样点
- 如果该点位于 PDF 曲线下方,则保留该点的 x 坐标
- 否则,拒绝该点并继续采样
这个过程会重复,直到收集到足够的样本。
4.1. 伪代码
algorithm RejectionSampling(λ, n, r):
sample <- an empty array
m <- 0
while m < n:
x <- draw a random number from [0, r]
y <- draw a random number from [0, λ]
if y <= f_λ(x):
append x to sample
m <- m + 1
return sample
其中:
x是在 [0, r] 范围内采样的候选值y是在 [0, λ] 范围内采样的高度值f_λ(x)是指数分布的 PDF 函数
⚠️ 注意:r 的选择很关键,太大效率低,太小会截断分布尾部
4.2. 示例
以下是一个拒绝采样过程的示例(生成 Exp[1] 的样本):
| 迭代 | x | y | f₁(x) | 决策 |
|---|---|---|---|---|
| 1 | 1.17 | 0.73 | 0.31 | 拒绝 |
| 2 | 4.38 | 0.11 | 0.01 | 拒绝 |
| 3 | 2.61 | 0.47 | 0.07 | 拒绝 |
| 4 | 1.72 | 0.98 | 0.18 | 拒绝 |
| 5 | 8.68 | 0.64 | 0.00 | 拒绝 |
| 6 | 4.79 | 0.01 | 0.01 | ✅ 保留 |
| 7 | 0.65 | 0.67 | 0.52 | 拒绝 |
| 8 | 0.38 | 0.43 | 0.68 | ✅ 保留 |
| 9 | 2.68 | 0.92 | 0.07 | 拒绝 |
可以看到,拒绝采样会产生大量无效点,效率较低。
4.3. 优化建议
- 适当减小 r 的上限:比如使用 99% 分位数,避免大量无效采样
- 调整采样区域:可以尝试使用非均匀分布采样,提高命中率
⚠️ 警告:过度截断会引入偏差,导致实际分布偏离目标指数分布
5. 总结
我们介绍了两种从指数分布中采样的方法:
| 方法 | 优点 | 缺点 |
|---|---|---|
| 逆变换采样法 | 实现简单、效率高 | 依赖 CDF 可逆 |
| 拒绝采样法 | 无需 CDF 可逆 | 效率低,可能产生大量无效样本 |
✅ 推荐优先使用逆变换法,除非 CDF 不可逆或计算成本过高。
⚠️ 拒绝采样法应作为备选方案,使用时注意优化采样区域以提升效率。