1. 简介
尽管 Transformer 模型已经在自然语言处理(NLP)领域占据主导地位,但 word2vec 仍然是构建词向量的一种流行方法。
在本文中,我们将深入探讨 word2vec 算法,并解释词嵌入背后的逻辑。通过这种解释,我们可以理解如何最好地使用这些向量,并通过 相加(Add)、拼接(Concatenate) 或 取平均(Averaging) 等操作来计算新向量。
2. 词嵌入的类型
词嵌入是用向量形式表达词语语义的一种方式。它不仅可以用于单个词语,也常用于短语或句子的表示。
在 NLP 中,我们常用它来进行向量空间建模。我们可以用这些向量来衡量不同词语之间的相似性(通过向量空间中的距离),或将它们直接输入机器学习模型中。
常见的词嵌入方法包括:
- One-hot 编码
- TF-IDF(词频-逆文档频率)
- Word2vec
- GloVe(全局词向量)
- BERT(基于 Transformer 的双向编码器表示)
本文将专注于 word2vec 方法。
3. Word2vec 简介
Word2vec 是一种通过构建词向量来建模词相似性的流行技术。它使用神经网络来建模词与词之间的关系。
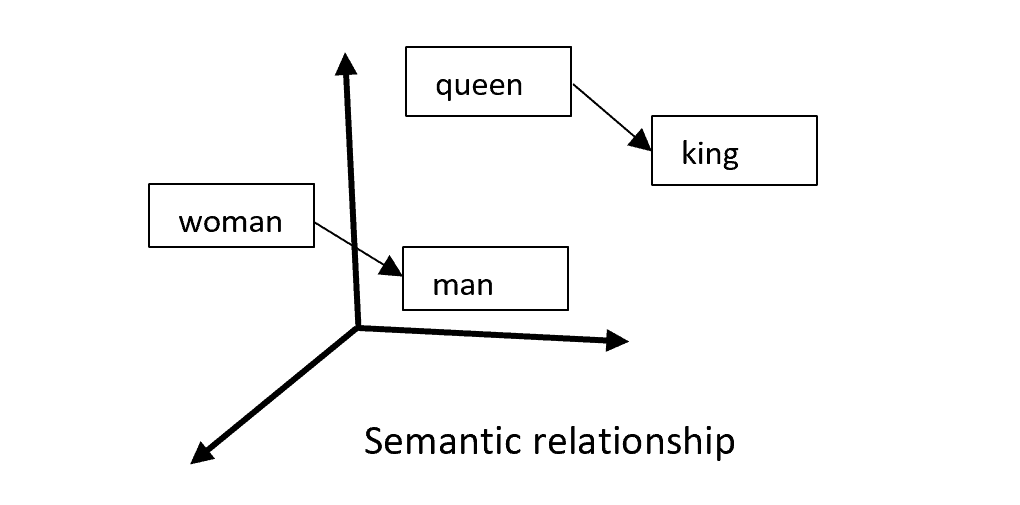
其核心思想是:在文本中相邻出现的词往往具有语义上的相似性。例如,“king” 和 “queen” 通常语义相近,在文本中也常相邻出现,并与 “man” 或 “woman” 等词相关。
Word2vec 将这一观察应用到机器学习算法中:
最终,word2vec 会为每个输入词生成两种类型的向量:
- 词嵌入(Word Embedding):当这个词是中心词时的表示
- 上下文词嵌入(Context Word Embedding):当这个词是上下文词时的表示
下面我们分别介绍这两种向量。
3.1. 词嵌入(Word Embedding)
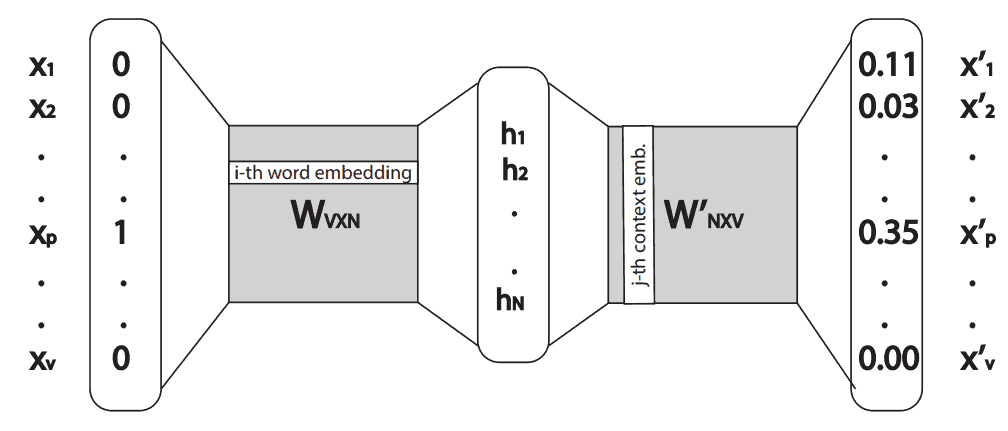
构建 word2vec 模型的一种方式是使用 skip-gram 架构。它是一个仅含一个隐藏层的简单神经网络。输入是一个 one-hot 向量,输出是一个通过 softmax 得到的概率向量。
假设输入的 one-hot 向量为  ,隐藏层向量
,隐藏层向量  是 one-hot 向量的转置与权重矩阵
是 one-hot 向量的转置与权重矩阵  的乘积:
的乘积:
(1) 
由于  是 one-hot 向量,所以隐藏层向量
是 one-hot 向量,所以隐藏层向量  就是权重矩阵
就是权重矩阵  中与 one-hot 向量中 1 所在位置对应的那一行。
中与 one-hot 向量中 1 所在位置对应的那一行。
例如:
(2) ![\begin{equation*} [0, 0, 1, 0, 0] \cdot \begin{bmatrix} 4 &8 &16 \\ 17 &0 &11 \\ 2 &13 &4 \\ 9 &5 &4 \\ 28 &31 &19 \\ \end{bmatrix} = [2, 13, 4]. \end{equation*}](/wp-content/ql-cache/quicklatex.com-9446e70311e798e30ffc30816eb8a584_l3.svg "Rendered by QuickLaTeX.com")
因此,对于某个词 "w",如果输入其 one-hot 向量,就能在隐藏层得到它的词嵌入向量 。权重矩阵 的每一行代表一个词的嵌入向量。
3.2. 上下文词嵌入(Context Word Embedding)
在得到隐藏层后,我们将其与第二个权重矩阵  相乘。乘积结果是一个输出向量
相乘。乘积结果是一个输出向量  ,我们对其应用 softmax 激活函数以获得概率分布:
,我们对其应用 softmax 激活函数以获得概率分布:
(3) 
输出向量的维度与输入相同,每个元素表示某个词与输入词处于相同上下文中的概率。
因此,第  个词的上下文嵌入是矩阵
个词的上下文嵌入是矩阵  的第 列。整个网络结构如下图所示:
的第 列。整个网络结构如下图所示:
4. 词向量的组合方式:相加、拼接还是取平均?
要理解如何处理这两种嵌入向量,我们需要进一步理解权重矩阵 和  的关系。
的关系。
4.1. 两种嵌入之间的关系
以单词 "cat" 为例,它的词嵌入为  ,上下文嵌入为
,上下文嵌入为  。如果我们计算它们的点积:
。如果我们计算它们的点积:
(4) 
也就是说,一个词出现在自己上下文中的概率非常低。
根据点积定义:
(5) 
如果点积接近 0,说明这两个向量夹角接近 90°,即 正交(orthogonal)。
4.2. 相加 vs 取平均
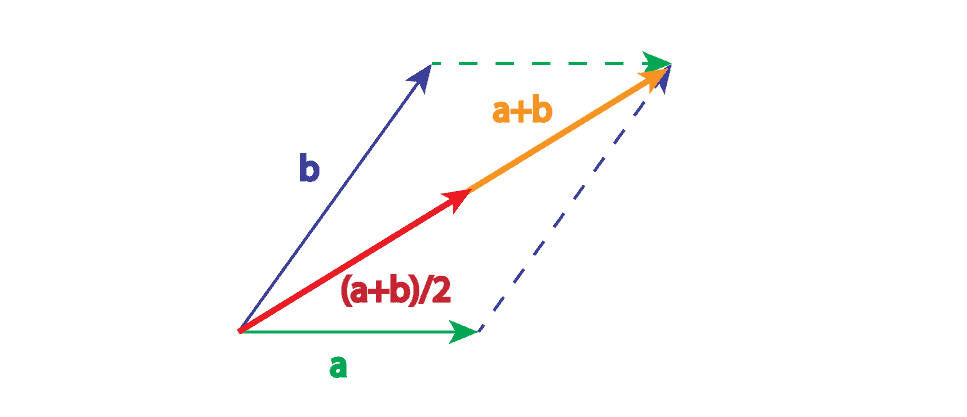
两个向量相加的几何意义是将一个向量的尾部连接到另一个向量的头部。而取平均则是将这个和向量缩放 1/2 倍。
✅ 从几何角度看,相加与取平均差别不大,只是后者向量长度更小。因此在实际应用中,我们更倾向于使用取平均的方法。
4.3. 组合嵌入向量
回到 "cat" 的例子,假设我们有一个词 "kitty",并且 word2vec 模型已经学习到它们是同义词,出现在非常相似的上下文中。
假设 与  的余弦相似度为 1,夹角为 0°,而它们的上下文向量与自身正交。
的余弦相似度为 1,夹角为 0°,而它们的上下文向量与自身正交。
如果我们把词嵌入和上下文嵌入相加,可能会出现如下情况:
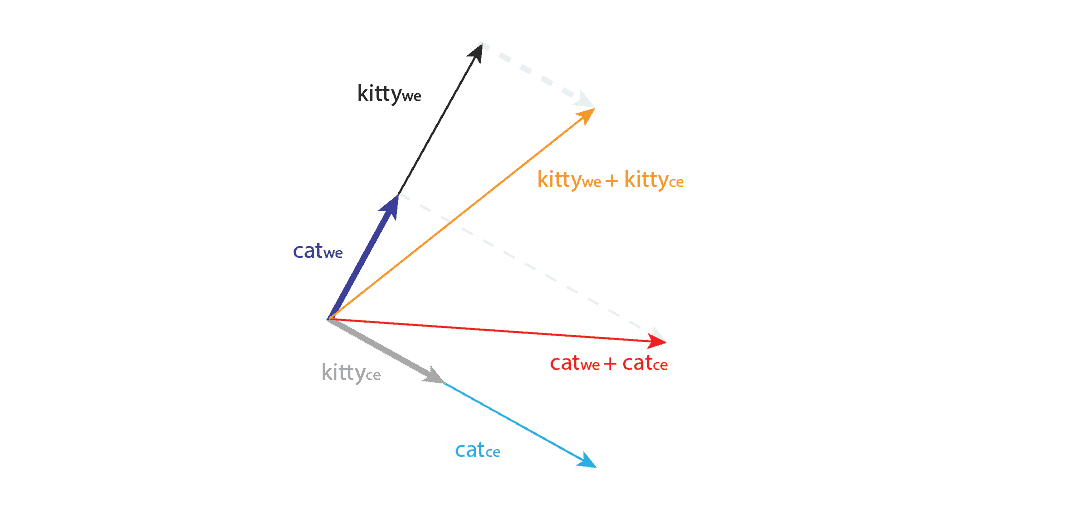
✅ 即使在理想情况下,词嵌入与上下文嵌入相加后,它们之间的角度也不再为 0°,说明这种操作可能会破坏嵌入空间中已学到的语义关系。
4.4. 实验结果
尽管添加上下文向量可能会破坏语义关系,但一些实验表明,这种操作可以引入额外知识,小幅提升模型性能。
例如,将人类对相似性和相关性的判断与词向量组合的余弦相似度进行比较发现:
- 使用词嵌入(W)可以更好地预测词语相似性
- 使用一个来自 W、一个来自 W' 的向量可以更好地预测词语相关性
比如对于 “house”,使用 W 得到的最相似词是 “mansion”、“farmhouse” 和 “cottage”,而使用 W 与 W' 的组合得到的相关词是 “barn”、“residence”、“estate” 和 “kitchen”。
此外,GloVe 方法在其论文中使用了词嵌入与上下文嵌入的 和,也获得了性能上的小幅提升。
5. 结论
本文讨论的是 如何处理单个词的词嵌入与上下文嵌入之间的操作,而不是如何组合句子中的多个词向量(这在这篇文章中有详细说明)。
我们详细解释了 word2vec 的工作原理,并讨论了如何处理词向量的问题。在原始的 word2vec 论文中,作者只使用词嵌入作为词向量表示,上下文向量被丢弃。
✅ 一些实验表明,词嵌入与上下文嵌入的和可以引入额外信息,但并不总是带来更好的效果。
⚠️ 从几何角度看,相加与取平均的行为几乎相同,因此在实际中可以根据需求选择。
❌ 没有证据表明拼接操作能带来明显收益。
✅ 推荐做法是仅使用词嵌入,因为这是业界通行做法,上下文向量不会显著提升效果。但在研究场景中,可以尝试使用相加或取平均的方法进行探索。