1. 引言
注意力机制(Attention)是一种人工智能和机器学习中常用的机制,其核心思想是动态地突出输入数据中最重要的部分。这一机制在深度学习模型中具有显著的提升作用,尤其是在处理长序列任务时表现尤为突出。
在本教程中,我们将介绍两种广泛应用的注意力机制:Luong Attention 和 Bahdanau Attention。我们会分别分析它们的技术实现、数学公式、优缺点以及常见应用场景,帮助你理解它们在实际任务中的差异和适用性。
2. 什么是注意力机制?
注意力机制广泛应用于自然语言处理(NLP)任务中,特别是在处理长序列输入时。其核心思想是让神经网络“关注”输入中某些关键部分,而忽略其他不相关或次要的信息。
以机器翻译为例,当翻译一句话时,注意力机制可以让模型聚焦于源语言中与当前目标词最相关的部分,从而更好地理解上下文。
具体来说,注意力机制通过以下步骤实现:
- 编码器将输入序列编码为一组隐藏状态(hidden states)
- 解码器根据当前状态计算注意力权重(attention weights)
- 使用权重对编码器的隐藏状态加权求和,得到上下文向量(context vector)
- 解码器结合上下文向量生成当前输出
下图展示了注意力机制在句子翻译中的应用示例:
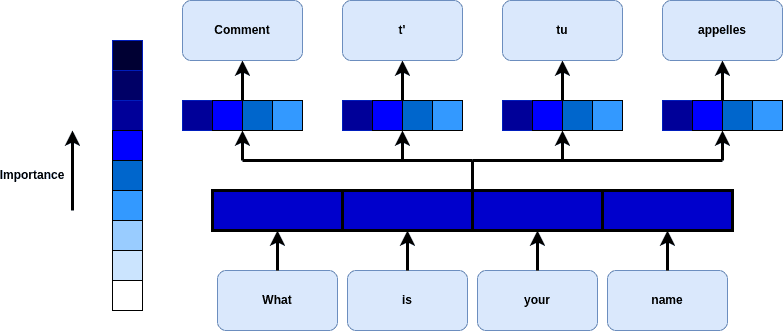
这种机制不仅提升了模型处理长序列的能力,也缓解了传统 RNN 中的梯度消失问题。
3. Luong Attention
Luong Attention 又称“点积注意力”(Scaled Dot-Product Attention),由 Minh-Thang Luong 等人在 2015 年的论文《Effective Approaches to Attention-based Neural Machine Translation》中提出。它常用于基于 RNN 的模型,如 LSTM。
Luong Attention 的核心思想是:使用解码器当前的隐藏状态与编码器的所有隐藏状态进行点积运算,生成注意力权重。这些权重决定了每个编码器状态对当前解码器输出的贡献程度。
3.1. Luong Attention 的类型
Luong Attention 提供了三种常见的注意力计算方式:
| 类型 | 公式 | 描述 |
|---|---|---|
| 点积注意力(Dot Product) | ✅ attention_weights = softmax(encoder_states * decoder_state) |
最简单的方式,直接计算点积 |
| 通用点积注意力(General Dot Product) | ✅ attention_weights = softmax(V_a * (encoder_states * decoder_state)) |
在点积基础上加入一个可学习参数 V_a |
| 拼接注意力(Concat) | ✅ attention_weights = softmax(V_a * W_a * [encoder_states; decoder_state]) |
将编码器状态与解码器状态拼接后通过一个全连接层计算 |
其中:
encoder_states是编码器的隐藏状态矩阵decoder_state是当前解码器的隐藏状态V_a、W_a是可学习参数[]表示向量拼接操作
这些方法在计算效率和表达能力上各有侧重,可根据具体任务选择。
4. Bahdanau Attention
Bahdanau Attention 又称“加性注意力”(Additive Attention),由 D. Bahdanau 等人在 2014 年的论文《Neural Machine Translation by Jointly Learning to Align and Translate》中提出。
与 Luong 不同,Bahdanau 使用了一个全连接神经网络来计算注意力权重。其计算公式如下:
✅ attention_weights = softmax(V_a * tanh(W_a * encoder_states + U_a * decoder_state + b_a))
其中:
encoder_states是编码器的隐藏状态矩阵decoder_state是当前解码器的隐藏状态V_a,W_a,U_a,b_a是可学习参数tanh是双曲正切激活函数
Bahdanau 的优势在于:
- 可以学习更复杂的输入与输出之间的对齐关系
- 更适合处理长序列任务
- 能够结合前一步的注意力状态,增强上下文建模能力
5. Luong 与 Bahdanau 的主要区别
虽然两者都属于注意力机制,但在实现方式和应用场景上有明显差异:
| 比较维度 | Luong Attention | Bahdanau Attention |
|---|---|---|
| 计算方式 | 数学公式(点积) | 神经网络(全连接) |
| 参数数量 | 少,模型更轻量 | 多,模型更复杂 |
| 上下文建模 | 仅使用当前解码器状态 | 使用当前解码器状态 + 前一步注意力状态 |
| 对齐能力 | 较弱 | 强 |
| 适用场景 | 简单任务、快速实现 | 复杂任务、长序列建模 |
⚠️ 注意:Bahdanau 虽然表达能力更强,但参数更多,训练成本更高。如果数据量较小,容易过拟合。
6. 优缺点对比
| 注意力机制 | 优点 | 缺点 |
|---|---|---|
| Luong | ✅ 实现简单 ✅ 计算高效 ✅ 更灵活 |
❌ 对复杂数据建模能力弱 ❌ 缺乏输入输出对齐建模 |
| Bahdanau | ✅ 更强的对齐能力 ✅ 更适合长序列建模 |
❌ 实现复杂 ❌ 参数多、训练成本高 ❌ 灵活性略差 |
7. 典型应用场景
注意力机制广泛应用于以下领域:
- ✅ 自然语言处理(NLP):机器翻译、对话系统、文本摘要
- ✅ 语音识别:语音转文本
- ✅ 推荐系统:提升推荐相关性
- ✅ 计算机视觉:图像描述生成、视觉问答
Bahdanau Attention 在机器翻译中表现尤为突出,因为它能显式建模输入与输出之间的对齐关系,提升翻译准确性。
8. 总结
本文介绍了两种主流注意力机制:Luong 和 Bahdanau。它们都旨在帮助模型聚焦于输入中最重要的部分,但在实现方式、参数复杂度和适用场景上有显著差异。
| 项目 | Luong | Bahdanau |
|---|---|---|
| 提出者 | Luong et al., 2015 | Bahdanau et al., 2014 |
| 核心机制 | 点积 | 全连接网络 |
| 对齐建模 | 否 | 是 |
| 适用场景 | 简单任务、快速实现 | 复杂任务、长序列建模 |
在实际项目中,建议根据任务复杂度、数据规模和计算资源选择合适的注意力机制。对于数据量大、任务复杂的场景,Bahdanau 是更优选择;而对于快速验证或轻量级部署,Luong 更加合适。