1. Overview
In this tutorial, we’ll talk about contours in computer vision.
2. Contours and Shape Detection
To understand an object in an image, we first need to find its shape, determined by its contour. The boundary or contour marks the outline of an object in an image. So, detecting contours plays a vital role in applications for identifying and segmenting objects in an image.
A contour consists of the pixels in an object’s boundary:

These pixels are usually of the same color, differentiating them from the rest.
3. Contour Representation
We represent contours with chain codes and shape numbers. These parameters help in clear representation and a better understanding of object contour. However, computing these parameters is purely optional in the process of finding contours.
3.1. Chain Code
We can trace contours with chain codes. A chain code indicates the directions of tracing along the boundary. Tracing starts from the selected initial point and proceeds clockwise.
There are two types of chain codes, 4-directional and 8-directional:
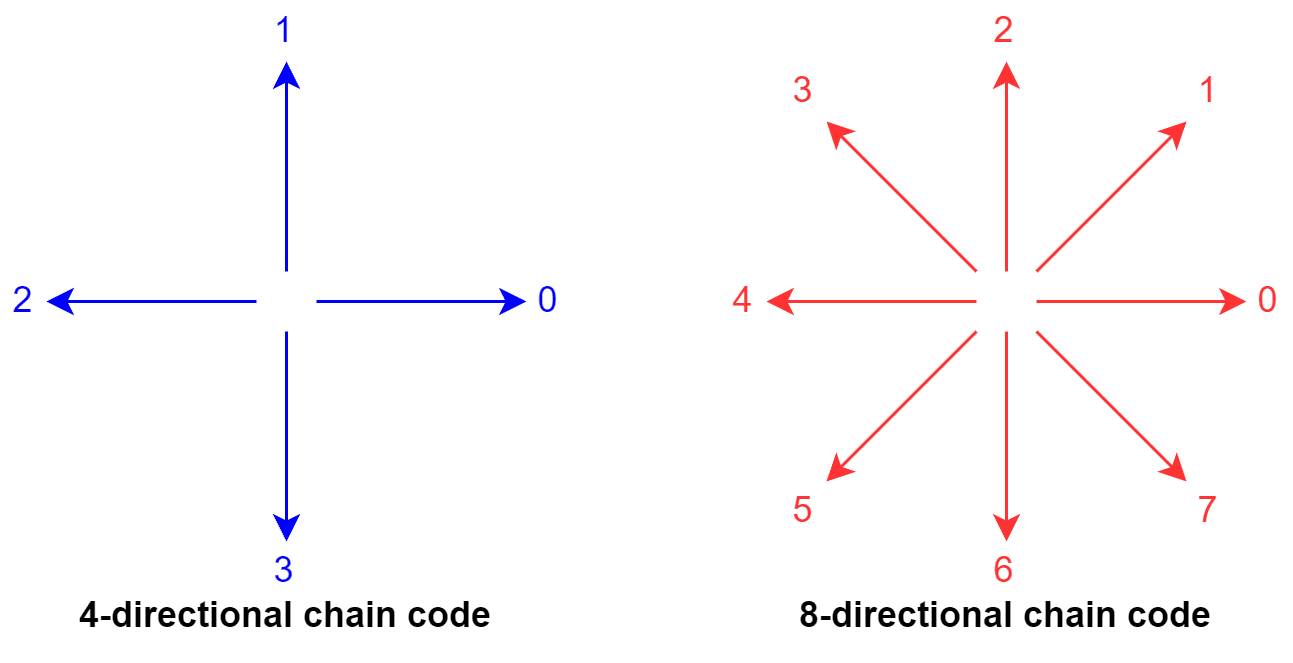
They differ in the number of directions along which we can trace a contour and specify a unique number for each direction. Let’s see how an object can be represented with chain codes:
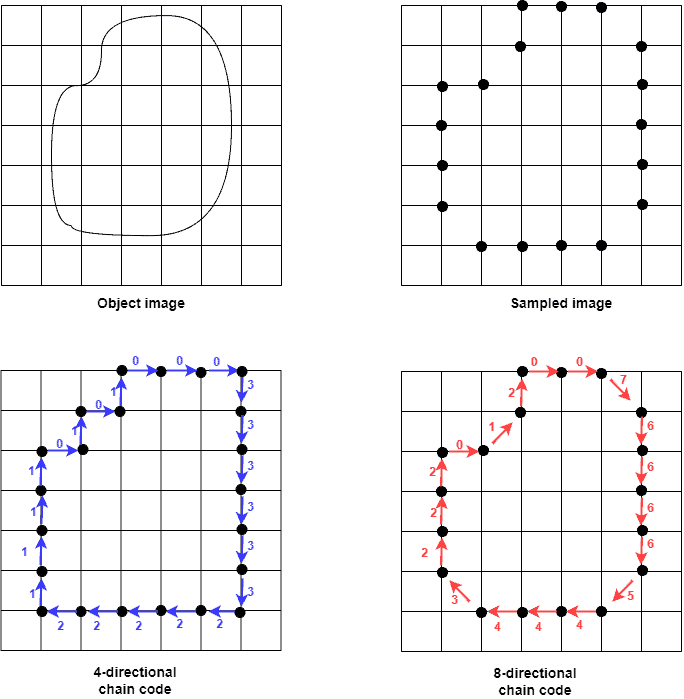
The image after sampling shows the boundary pixels. These are the contour points. Assuming the starting position is top-left, we get the chain code moving clockwise. In our example, the 4-directional and 8-directional chain codes are  and
and  .
.
3.2. The Shape Numbers and First Differences
A shape number represents a normalized version of the corresponding chain code’s first difference. The first difference shows how many counterclockwise directional changes were made in the chain code.
We compute the first difference by considering adjacent pairs one at a time. For example, the 4-directional chain code pair  needs no (counterclockwise) directional changes, so their first difference is
needs no (counterclockwise) directional changes, so their first difference is  . However, the chain code pair
. However, the chain code pair  takes
takes  changes, so the first difference is .
changes, so the first difference is .
We concatenate the differences of the consecutive pairs to get the first difference of a chain code. For example, the first difference of the four-directional code is  .
.
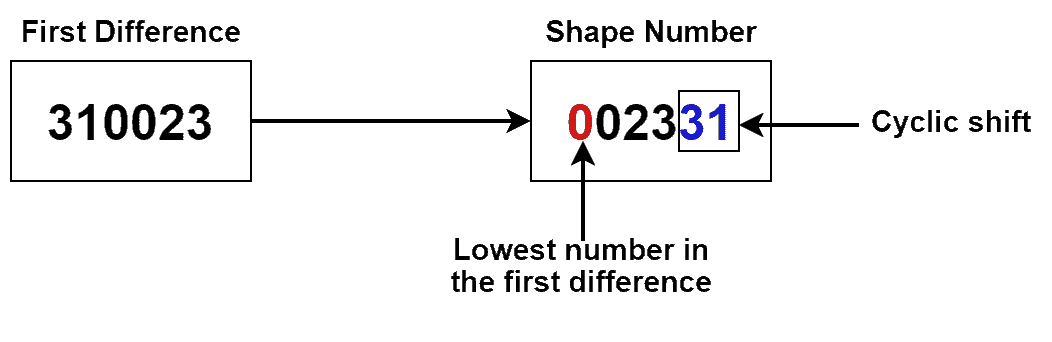
A shape number’s the same as the first difference, except it starts from the lowest number in the first difference. For instance, assuming the object’s first difference is  , its shape number is
, its shape number is  . The differences before the first lowest number are cyclically shifted to the left:
. The differences before the first lowest number are cyclically shifted to the left:
 4. Procedure
4. Procedure
Let’s talk about how to find a contour.
4.1. Binarization
We first need to binarize our image:
Binarization converts our image from the commonly used red-green-blue (RGB) form to binary. A binary image contains only zeros and ones. One indicates the white color, and zero stands for black. Notably, the most commonly used binarization technique is Otsu’s threshold method. Converting to binary form helps in identifying contour points.
4.2. Contours Extraction
The result of finding contours is a bounding line drawn on the object’s outline in an image. However, binarization doesn’t reveal all boundary pixels. The popular operators addressing this issue are the Canny and Roberts operators. They produce discontinuous contours.
In particular, there are point, line, and edge discontinuities:
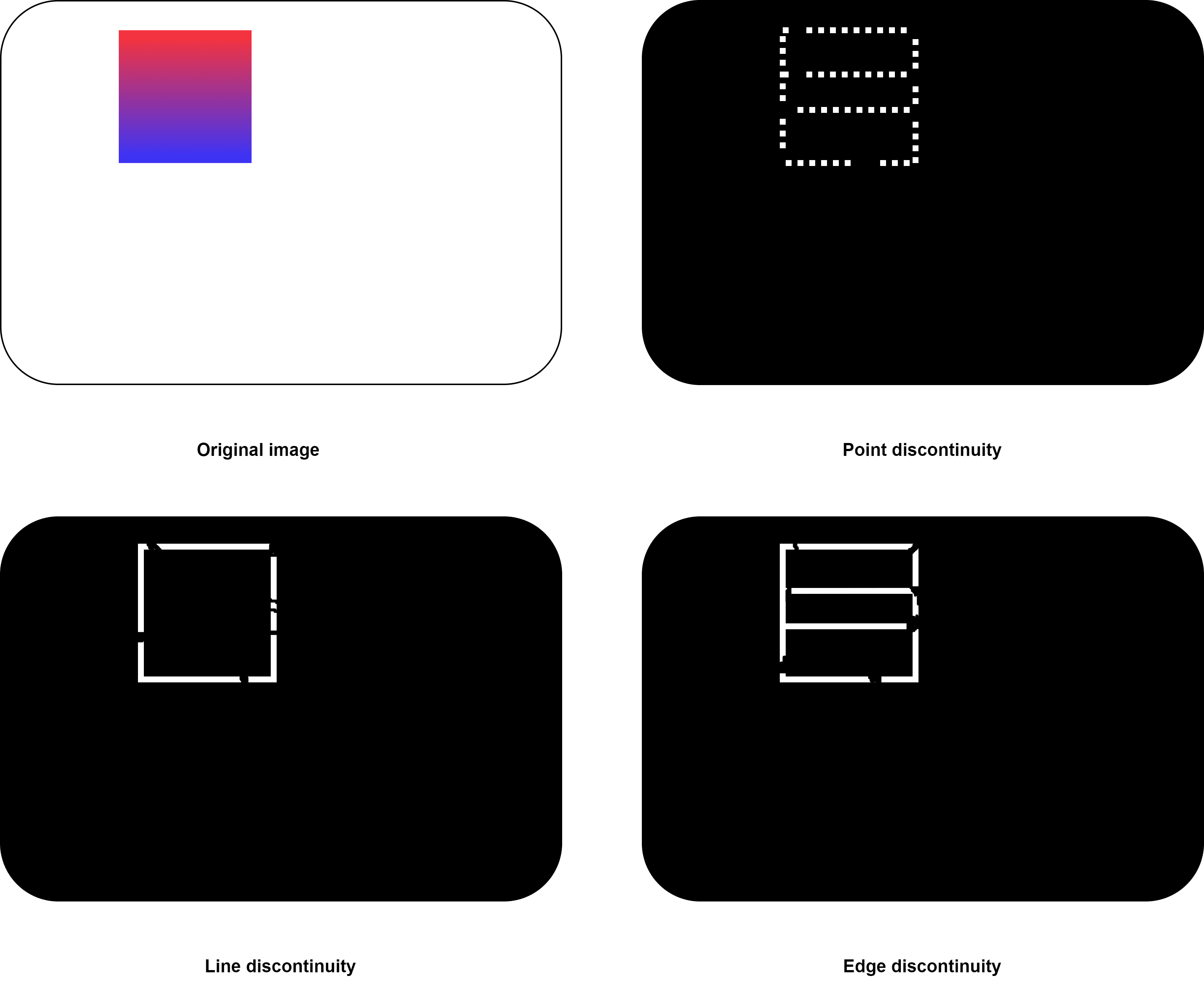
Usually, an object contains pixels of the same or similar intensity. Consequently, we can differentiate an object from its background. However, these pixel changes can sometimes be in the form of pixels or a group of pixels forming lines*.* As a result of those abrupt changes, we get edges. Unlike line discontinuity, edge discontinuity helps in finding curved objects.
To complete the contour, we need to join the discontinuous segments.
4.3. Choice of Discontinuities
We can choose the type of discontinuity to use in finding contours. However, the choice will depend on the application and image.
Point discontinuities are usually more sensitive to minor value changes. Modeling lines gives us longer segments, which we can restrict to horizontal and vertical or allow lines with an angle (e.g.,  ). While displaying the image’s edges, edge detection can be as sensitive as point detection. Additionally, detecting these discontinuities helps in obtaining the boundary of the object.
). While displaying the image’s edges, edge detection can be as sensitive as point detection. Additionally, detecting these discontinuities helps in obtaining the boundary of the object.
Usually, we consider contour detection closely similar to edge detection. However, there’s a significant difference between them. Every abrupt pixel change can be an edge, whereas only the outermost edges constitute a contour.
5. Use Cases
Contours play a key role in object recognition. Further, contours help in better compression by indicating a difference between pixels. This is helpful when deciding which pixels to eliminate.
Moreover, contours also aid algorithms that require key features in the input image to process it. For example, that’s the case if we want to use the presence of objects as features. To see if an image contains a thing, we need to see if the detected contours match those of target objects.
Also, contours help corner detection algorithms that aim to find boundary points.
6. Conclusion
In this article, we talked about contours as well as their parameters. Additionally, we showed how to find them in an image and explained what we could use them for in real-world applications.
We can identify an object by detecting its contour. A contour is a continuous line of pixels separating its interior from the rest of the image. Further, we use chain codes to represent contours.