1. 简介
目标检测(Object Detection)是计算机视觉和图像处理领域的一个重要方向,主要任务是在图像或视频中识别出特定类别的对象并定位其位置。例如,识别图像中的猫、狗、汽车等,并用边界框(bounding box)标出它们的位置。
在目标检测中,不同类别的对象具有各自的特征。例如,圆形物体具有圆形轮廓,方形物体具有直角和等长边。这些特征被用于分类和识别。
单次检测器(Single Shot Detectors, SSDs)是一种高效的目标检测方法,能够在一次推理过程中完成对象的分类和定位,非常适合实时应用场景,比如自动驾驶、视频监控、机器人导航等。
本文将深入讲解 SSD 的原理、结构、优缺点,以及其检测流程。
2. 目标检测 vs 图像分类
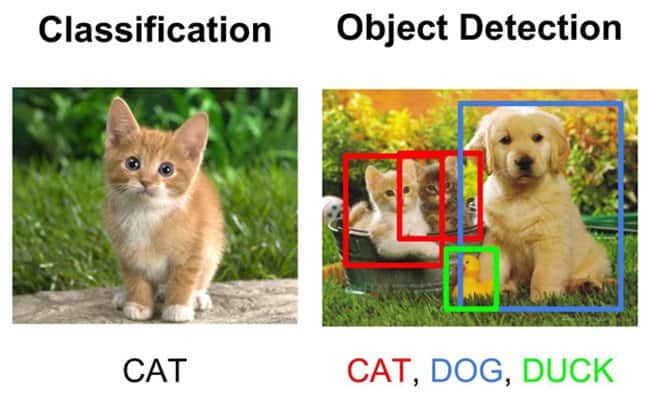
图像分类(Image Classification)的任务是识别整张图像属于哪个类别,例如判断一张图是猫还是狗;而目标检测不仅需要识别出图像中有哪些对象,还要指出它们在图像中的具体位置,通常用边界框来表示。
如下图所示,分类模型只会输出“猫”或“狗”的标签,而目标检测模型则会同时输出类别标签和边界框。
目标检测方法可以分为两大类:
- 两阶段方法(Two-stage methods):如 R-CNN 及其变体,先生成候选区域(region proposals),再对每个区域进行分类和边界框精修。
- 单阶段方法(One-stage methods):如 YOLO 和 SSD,直接对整张图像进行预测,同时输出类别和边界框,速度快但精度略低。
3. SSD 的基本原理
SSD 是一种典型的单阶段目标检测方法,利用卷积神经网络(CNN)一次性预测边界框和类别标签,无需像 R-CNN 那样进行多阶段处理,因此效率更高。
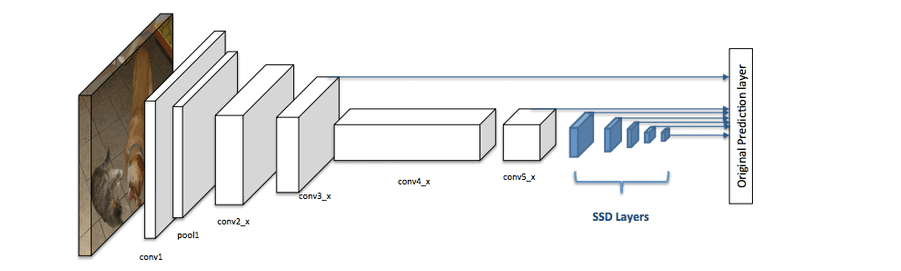
3.1. SSD 的网络结构
SSD 的整体结构通常由两部分组成:
- 基础网络(Base Network):如 VGG 或 ResNet,通常是在 ImageNet 上预训练好的分类网络,用于提取图像特征。
- 扩展层(Extra Layers):在基础网络后添加的多个卷积层,用于从不同尺度的特征图中检测目标。
这种设计使得 SSD 能够在不同尺度上检测目标,提高检测的鲁棒性。
下图展示了 SSD 的典型网络结构:
3.2. SSD 的优缺点
✅ 优点:
- 速度快:使用单一网络完成检测任务,推理效率高,适合实时应用。
- 利用预训练模型:可以借助 ImageNet 上预训练的 CNN 模型提升准确率,尤其在小数据集上表现良好。
❌ 缺点:
- 精度略低:相比两阶段方法(如 Faster R-CNN),SSD 在小目标检测上表现较弱。
- 对尺度敏感:依赖预设的 anchor boxes,若目标尺寸与训练数据差异较大,检测效果会下降。
4. SSD 的检测流程
整个 SSD 的检测流程如下图所示:
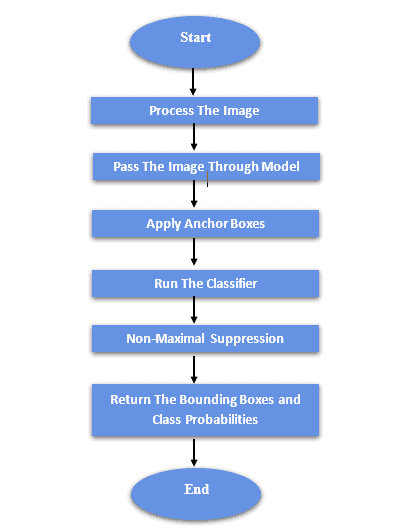
具体步骤如下:
- 图像预处理:对输入图像进行归一化、缩放、增强等处理。
- 特征提取:通过基础网络提取高维特征图。
- 生成候选框(Anchor Boxes):在每个特征图位置上生成多个预设的 anchor boxes。
- 分类与定位预测:对每个 anchor box 进行分类(判断属于哪个类别)和边界框偏移预测。
- 非极大值抑制(NMS):去除重叠的边界框,保留最优预测结果。
- 输出结果:返回最终的边界框和对应的类别概率。
5. 总结
Single Shot Detectors(SSD)是一种高效的目标检测方法,其核心优势在于速度快、实现简单、适合实时应用。虽然在精度上略逊于两阶段方法,但通过改进 anchor box 设计和引入多尺度特征图,SSD 的检测效果已经非常接近主流方法。
对于需要兼顾速度与精度的场景,比如自动驾驶、视频监控、移动设备部署等,SSD 是一个非常实用的选择。如果你希望在实际项目中快速部署一个目标检测系统,SSD 是一个非常值得尝试的模型。