1. 概述
在本文中,我们将探讨机器学习中两个经典算法:支持向量机(Support Vector Machine, SVM)和神经网络(Neural Network, NN)之间的异同。我们会分别介绍它们的核心特性,然后对比它们在分类任务中的表现。
最后,我们还会讨论在哪些具体场景下更适合使用其中某一个算法。
2. 分类:边界检测问题
2.1. 分类问题概述
分类问题的核心是学习一个函数  ,其中
,其中  是特征向量,
是特征向量, 是类别标签。这个函数的目标是将输入数据映射到对应的类别。
是类别标签。这个函数的目标是将输入数据映射到对应的类别。
下图展示了分类任务的直观表示:
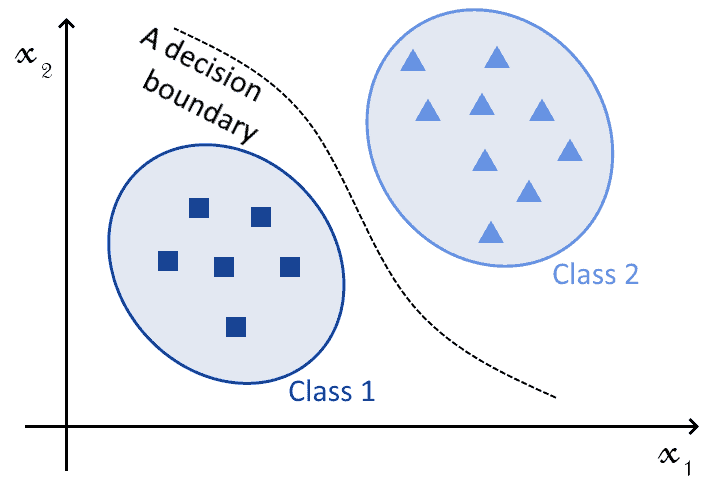
SVM 和 NN 都能完成这个任务。SVM 通过选择合适的核函数(kernel),NN 通过选择合适的激活函数(activation function)来逼近决策边界。
两者都能处理线性和非线性分类问题:
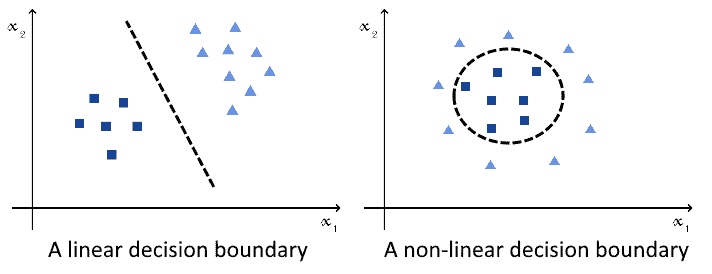
因此,选择哪一个算法并不取决于问题本身的复杂度,而是取决于算法本身的特性和使用场景。
⚠️ 注意:本文仅讨论 SVM 和 NN 在分类任务中的应用。它们也常用于回归任务,但不在本文讨论范围内。
2.2. 神经网络如何逼近决策边界
单层神经网络结合非线性激活函数,理论上可以逼近任何连续函数。这就是著名的 通用逼近定理(Universal Approximation Theorem)。
这意味着只要决策边界是连续的(分类任务中通常如此),神经网络就可以通过调整权重来逼近这个边界。
2.3. SVM 如何逼近决策边界
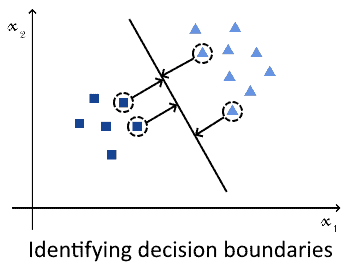
SVM 的核心思想是找到一个最优超平面,使得不同类别的样本之间的间隔最大。这个超平面由支持向量(support vectors)决定,即离分类边界最近的几个样本点。
如果原始特征空间中无法找到线性可分的边界,SVM 可以通过核函数将数据映射到高维空间,从而找到一个线性可分的超平面。
如下图所示,SVM 会最大化分类边界和支持向量之间的距离:
3. 两种算法详解
3.1. SVM 分类原理
SVM 通常分为两种类型:
- 线性 SVM:使用线性核,决策边界是原始特征空间中的一个超平面。
- 非线性 SVM:使用非线性核(如多项式核、RBF 核等),将数据映射到高维空间后再进行分类。
核函数(kernel)是 SVM 的核心,它替代了传统的向量点积操作。常见的核函数包括:
- 多项式核
- 双曲正切核(tanh)
- 高斯 RBF 核
✅ 优点:SVM 能在高维空间中找到最优分类边界,且对小样本数据表现良好。
❌ 缺点:参数调优复杂,训练速度慢。
3.2. 神经网络分类原理
神经网络不需要核函数,它通过非线性激活函数引入非线性能力。常见的激活函数包括:
- Sigmoid:

- Tanh:

- Softmax:

神经网络通过多层结构逐步逼近复杂的决策边界。理论上,只要隐藏层足够宽,单层神经网络就能逼近任何连续函数。
⚠️ 注意:虽然理论上可以逼近任意函数,但训练过程中可能陷入局部极小值,无法收敛。
4. 相似之处
4.1. 都是参数模型
- SVM 参数:
- C:软间隔参数
- γ:核函数参数(如 RBF 核)
- NN 参数:
- 层数、每层节点数
- 学习率、训练轮数等
两者都需要调参,但 NN 参数数量通常远大于 SVM。
4.2. 都能处理非线性问题
- SVM:通过核函数映射到高维空间
- NN:通过非线性激活函数
4.3. 分类精度相当
在相同数据集上,如果训练充分,SVM 和 NN 的分类精度相当。但 NN 在大数据和高维任务上通常表现更优。
5. 不同之处
5.1. 结构复杂度
- SVM:参数数量随输入维度线性增长
- NN:参数数量随层数和节点数指数增长
NN 的结构更灵活,但也更复杂。
5.2. 所需训练数据量
- SVM:仅依赖支持向量,对数据量要求较低
- NN:依赖大量数据,且对数据顺序敏感
5.3. 训练时间
- SVM:训练速度快,适合小样本
- NN:训练时间长,尤其是深度网络
5.4. 参数优化方法
- SVM:使用二次规划(Quadratic Programming)优化,保证全局最优
- NN:使用梯度下降(Gradient Descent),可能陷入局部最优
5.5. 对初始权重的敏感性
- NN:初始权重敏感,可能影响最终结果
- SVM:不受初始权重影响,保证收敛
6. 使用场景对比
6.1. 特征空间采样不充分
如果你的训练数据分布稀疏,远离决策边界,那么神经网络可能会学到一个“过于靠近样本”的边界,导致对边缘样本分类错误。
✅ 推荐使用 SVM:因为它会最大化边界,对边缘样本更鲁棒。
6.2. 训练时间紧张
在时间紧迫的场景下(如疫情爆发初期的医疗诊断系统),SVM 更适合快速部署。
✅ 推荐使用 SVM:训练速度快,适合快速迭代。
6.3. 对准确率要求极高
在自动驾驶、图像识别等对准确率要求极高的场景中,神经网络更合适。
✅ 推荐使用 NN:在大数据和高维任务中表现更优。
7. 总结
| 特性 | SVM | NN |
|---|---|---|
| 模型结构 | 固定 | 灵活 |
| 训练速度 | 快 | 慢 |
| 数据依赖 | 小 | 大 |
| 收敛性 | 全局 | 可能局部 |
| 适用场景 | 小数据、快速部署 | 高精度、大数据 |
✅ 选择建议:
- 小样本 + 快速部署 ➜ SVM
- 边缘样本敏感 ➜ SVM
- 高精度要求 ➜ NN
- 数据量大 ➜ NN
在实际项目中,往往先尝试 SVM 快速验证,再转向 NN 追求更高精度。希望这篇文章能帮助你在实际项目中做出更明智的选择!