1. 概述
Elasticsearch 是一个基于 Apache Lucene 构建的强大分布式搜索与分析引擎。其分布式设计使其在处理海量文档时依然具备高性能和良好的扩展性。
在众多功能中,Elasticsearch 提供了乐观并发控制(Optimistic Concurrency Control)机制,以确保在高并发环境下对文档的修改不会导致数据不一致。
本文将介绍 Elasticsearch 的乐观并发控制机制,并分析 version_conflict_engine_exception 错误与其之间的关系。
2. version_conflict_engine_exception 错误的原因
在高并发写入的 Elasticsearch 环境中,可能会遇到如下 version_conflict_engine_exception 错误日志:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, required seqNo [17], primary term [3]. current document has seqNo [18] and primary term [3]",
"index_uuid": "QuhLhsE7Qh-Yc7XbgiPO1g",
"shard": "0",
"index": "mainstore"
}
],
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, required seqNo [17], primary term [3]. current document has seqNo [18] and primary term [3]",
"index_uuid": "QuhLhsE7Qh-Yc7XbgiPO1g",
"shard": "0",
"index": "mainstore"
},
"status": 409
}
该日志表明操作被拒绝,状态码为 409(Conflict),并且提示当前文档的 seqNo 比请求的更大。
✅ 本质上,这是 Elasticsearch 的乐观并发控制机制检测到潜在冲突更新后的反馈。下面我们深入探讨并发控制机制。
3. 并发控制机制
在数据存储系统中,并发控制是指在多个操作同时执行时,管理资源访问以避免冲突的机制。
3.1. 丢失更新问题
丢失更新(Lost Update) 是并发控制中的经典问题,通常发生在两个或多个事务同时读取并修改相同数据时。其中一个事务的更新会被另一个覆盖,导致数据丢失。
举个例子:假设我们有一个库存文档,初始值为 100。两个并发进程 A 和 M 同时修改该值:
- A:加 10
- M:减 20
没有并发控制的情况下,最终值取决于哪个进程最后写入:

如果 A 最后写入,结果是 110;如果 M 最后写入,结果是 80。无论哪种情况,都意味着一个更新被覆盖了。
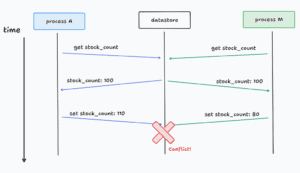
⚠️ 这种问题的危险之处在于程序不会察觉,数据被静默地破坏了。
解决方法:引入并发控制机制。
3.2. 并发控制类型
常见的并发控制机制分为两种:
- 悲观并发控制(Pessimistic Concurrency Control):在操作前加锁,保证操作期间资源不可用。如数据库中的
FOR UPDATE。 - 乐观并发控制(Optimistic Concurrency Control):假设操作不会冲突,只有在提交时才检查版本。如 Spring JPA 中的
@Version注解。
✅ 乐观并发控制的优势在于性能更高,因为没有加锁开销,也避免了死锁风险。
4. Elasticsearch 的乐观并发控制机制
Elasticsearch 使用乐观并发控制机制来管理对文档的并发修改。它通过两个关键字段来检测冲突:
- Sequence Number(序列号):每次对文档的变更都会递增。
- Primary Term(主分片任期):主分片重新分配时递增。
4.1. 序列号与主分片任期
每次文档更新时,Elasticsearch 返回当前的 _seq_no 和 _primary_term:
示例更新请求:
$ curl -X POST "http://localhost:9200/mainstore/_update/1" -H 'Content-Type: application/json' -d'
{
"doc": {
"stock_count": 100
}
}'
返回结果中包含:
{
"_seq_no": 2,
"_primary_term": 1
}
再次更新时,_seq_no 会递增:
{
"_seq_no": 3,
"_primary_term": 1
}
4.2. 冲突检测机制
Elasticsearch 的乐观并发控制流程如下:
- 检查请求中的
_primary_term是否与当前文档一致。如果不一致,说明主分片已重新分配,拒绝更新。 - 如果
_primary_term一致,再检查请求中的_seq_no是否大于当前文档的_seq_no。如果不是,说明数据可能已过期,拒绝更新。
⚠️ 这个机制确保了只有基于最新版本的更新才会被接受。
4.3. 实际演示:并发更新冲突
编写一个 Bash 函数模拟并发更新:
update_document() {
curl "http://localhost:9200/mainstore/_update/1" -H 'Content-Type: application/json' -d'
{
"doc": {
"stock_count": 100
}
}'
}
并发执行两次:
(update_document) &
(update_document) &
wait
输出结果中,一个请求成功,另一个失败并抛出 version_conflict_engine_exception。
4.4. 自动重试冲突请求
Elasticsearch 的 Update API 支持 retry_on_conflict 参数,用于在冲突时自动重试:
update_document_retry() {
curl "http://localhost:9200/mainstore/_update/1?retry_on_conflict=3" -H 'Content-Type: application/json' -d'
{
"doc": {
"stock_count": 100
}
}'
}
✅ 这个参数允许在冲突时自动重试,提高并发写入成功率。
5. 总结
本文从并发控制的基本概念讲起,介绍了丢失更新问题及其解决方案,并重点讲解了 Elasticsearch 的乐观并发控制机制。通过 _seq_no 和 _primary_term,Elasticsearch 能有效检测并拒绝冲突更新,从而保证数据一致性。
最后我们通过一个并发更新示例演示了 version_conflict_engine_exception 错误的产生,并介绍了如何通过 retry_on_conflict 参数缓解该问题。
✅ 在高并发场景下,理解并正确使用乐观并发控制机制,是避免数据丢失、提升系统稳定性的关键。