1. 简介
双向搜索(Bidirectional Search,BiS)是一种用于在图中寻找起点和终点之间最短(或最低成本)路径的算法。与传统的单向搜索不同,BiS 同时从起点和终点出发,向中间推进,直到两个搜索路径相遇。这种方式在理论上可以显著减少搜索空间,从而提升算法效率。
2. 搜索算法回顾与动机
2.1 单向搜索的局限
常见的单向搜索算法包括:
- 广度优先搜索(BFS)
- 深度优先搜索(DFS)
- 一致代价搜索(UCS)
- A* 算法
这些算法通常从起点出发,逐步扩展搜索树,直到找到目标节点。以 BFS 为例,其时间复杂度为 O(b^d),其中 b 是图的平均分支因子,d 是最浅的目标节点深度。
当 b 和 d 较大时,单向搜索的计算量会非常大。
2.2 双向搜索的优势
双向搜索的基本思想是:
- 同时从起点和终点出发,进行双向搜索
- 当两个搜索方向在图中某节点相遇时,找到路径
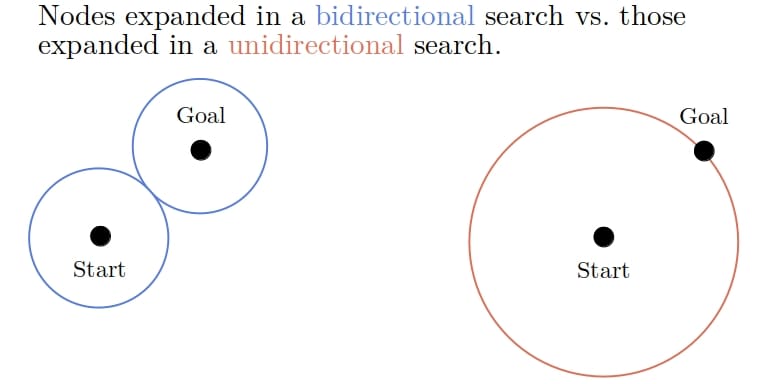
这样做的好处是:两个搜索方向各扩展 O(b^(d/2)) 个节点,总节点数约为 2 * b^(d/2),远小于单向搜索的 b^d。
✅ 举例说明:
假设 b = 10, d = 20:
- 单向 BFS:
10^20个节点 - 双向 BFS:
2 * 10^10个节点
这相当于减少了 50亿倍 的搜索量。
3. 反向边与图遍历
3.1 图的反向表示
在双向搜索中,反向搜索需要从目标节点出发,因此需要图的反向边。例如:
- 原图中有一条从
u到v的边 - 反向搜索中需要一条从
v到u的边
⚠️ 注意:反向边不一定在现实中存在,只要在计算上可逆即可。
3.2 反向边的构建方式
- 构建图时,同时保存正向和反向邻接表
- 或者在运行时动态反转邻接关系
✅ 示例:
Map<Node, List<Node>> forwardGraph; // 正向图
Map<Node, List<Node>> reverseGraph; // 反向图
4. 双向一致代价搜索(BiUCS)
4.1 搜索交替策略
双向搜索的关键问题是:如何交替执行正向和反向搜索?
常见策略:
- 轮流执行:先正向一步,再反向一步
- 优先执行代价最小的搜索方向:类似 UCS 的贪心策略
两种策略各有优劣:
- 轮流执行保证了搜索方向的平衡
- 优先执行代价最小的方向更接近 UCS 的精神,但可能偏向某一方
4.2 停止条件设计
双向搜索不能在第一次相遇时就终止,因为可能存在更优路径。
正确的停止条件是:
当两个方向的前沿节点的最小代价之和大于当前最优路径代价时,可以安全终止
数学表达为:
top_F + top_R >= μ
其中:
top_F是正向搜索前沿节点的最小代价top_R是反向搜索前沿节点的最小代价μ是当前已知最优路径的代价
4.3 算法伪代码
algorithm BidirectionalUCS(s, t, succ_F, succ_R, c):
Q_F, Q_R <- 优先队列,初始包含 s 和 t
expanded_F, expanded_R <- 已扩展集合
solution <- failure
mu <- infinity
while top_F + top_R < mu:
if forward search chosen:
STEP(search_F, search_R, solution, mu)
else:
STEP(search_R, search_F, solution, mu)
return solution
辅助函数 STEP 实现节点扩展和路径更新:
algorithm STEP(search_1, search_2, solution, mu):
u <- 从 search_1 的队列中弹出最小代价节点
for v in succ_1(u):
if v not in expanded_1 or g_1(u) + c(u, v) < g_1(v):
更新 v 的代价并加入队列
if v 在 search_2 中扩展过:
更新最优路径和 μ
5. 实现难点与注意事项
5.1 适用场景
双向搜索适用于:
- 图中目标节点明确
- 可以高效构建反向边
- 边权非负(尤其适用于 UCS/A*)
不适用于:
- 多个隐式目标节点
- 反向边不可逆
- 时间不可逆问题(如时间旅行类问题)
5.2 实现难点
- 交替策略设计:影响搜索效率
- 停止条件证明:需数学推导
- 路径重建:需记录路径信息或通过回溯重建
- 调试困难:双向状态容易出错
5.3 常见错误
❌ 错误1:在首次相遇时就终止搜索
✅ 正确做法:继续搜索直到满足停止条件
❌ 错误2:只使用一个方向的启发式函数(如 A*)
✅ 正确做法:两个方向都应使用启发式函数,并协调停止条件
6. 总结
双向搜索是一种高效的路径查找策略,尤其适合目标节点明确、图结构可逆的场景。其核心优势在于:
- 显著减少搜索空间
- 提高搜索效率
- 保持路径最优性(在合理停止条件下)
但其实现复杂度较高,需谨慎设计:
- 交替策略
- 停止条件
- 路径重建机制
✅ 建议:
- 对于常数边权:使用双向 BFS 或 IDDFS
- 对于变权图:使用 BiUCS 或双向 A*
- 谨慎处理反向边和停止条件
双向搜索是搜索算法中的高级技巧,掌握后可以在路径规划、游戏 AI、图算法等领域发挥重要作用。