1. Introduction
Transformer architectures have revolutionized the field of natural language processing and influenced other domains such as computer vision and speech recognition.
Transformers leverage attention mechanisms to capture contextual relationships between words or tokens in a sequence. Alongside attention mechanisms, another crucial component of transformer models is residual connections.
Throughout this article, we’ll delve into the mechanics of residual connections and explore their specific benefits in gradient propagation. Moreover, we’ll examine their role and discuss their impact on training convergence on modern transformer models.
2. Understanding Residual Connections
Residual connections, initially deployed in the context of convolutional neural networks (CNNs), have become fundamental to the design of transformer architectures. They first appeared on the ResNet architecture.
At its core, a residual connection allows the information to flow through a shortcut, bypassing one or more layers of neural network computations:
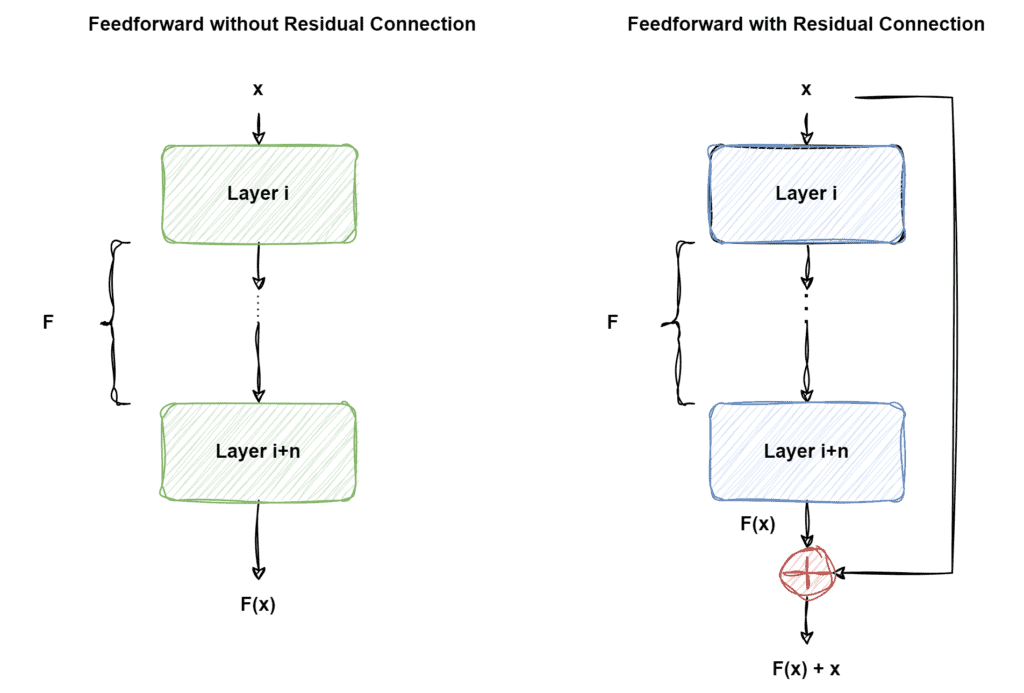
2.1. Mathematical Approach
First of all, residual connections ensure that the information from the input of a layer (or a block of layers) is preserved. Moreover, this information is added to the output before passing through a non-linear activation function.
This approach is crucial for maintaining gradient flow and optimizing the training of deep transformer architectures.
Mathematically, for a given layer with input  and output
and output  , the residual connection is formulated as,
, the residual connection is formulated as,  , where is the input to the layer.
, where is the input to the layer.
2.2. Purpose
By introducing skip connections, residual connections diminish the issue of vanishing gradients. This is particularly crucial in deep networks, where gradients can diminish significantly as they backpropagate through multiple layers. The direct path provided by residual connections facilitates smoother gradient flow and offers a more effective training of deep transformer architectures.
Moreover, residual connections enable the construction of deeper neural networks without encountering degradation in performance. This depth is essential for transformers to capture complex relationships and dependencies within sequences effectively.
2.3. Implementation in Transformers
In the context of transformers, residual connections are typically incorporated within each sub-layer of the transformer encoder and decoder stacks.
For instance, within the self-attention mechanism or the feedforward neural networks in each transformer layer, residual connections ensure that the original input information is preserved and integrated with the transformed outputs.
3. The Structure of Transformer Architectures
Unlike traditional sequential models such as recurrent neural networks (RNNs), transformers rely on self-attention mechanisms and parallel processing.
The layered structure of transformers, combined with residual connections, allows for scalable model architectures. This scalability is essential for handling increasingly large datasets and complex tasks, making transformers suitable for a wide range of applications.
The core components of a transformer architecture include:
3.1. Encoder-Decoder Architecture
The encoder is responsible for processing the input sequence. It consists of multiple identical layers, each comprising a self-attention mechanism followed by a position-wise feedforward neural network (FFN). Residual connections and layer normalization are applied around each of these sub-layers.
On the other hand, the decoder generates the output sequence by attending to the encoder’s output and its input (autoregressive manner). Like the encoder, it consists of layers with self-attention, encoder-decoder attention, and FFNs, incorporating residual connections and layer normalization.
3.2. Self-Attention Mechanism
Self-attention allows each word in the input sequence to attend to every other word, capturing dependencies irrespective of their positions. This mechanism is computationally intensive but enables transformers to model long-range dependencies effectively.
3.3. Positional Encoding
Since transformers lack inherent sequential order (unlike RNNs), positional encoding vectors are added to input embeddings to provide information about token positions in the sequence. This addition ensures that transformers can distinguish between different positions within the sequence.
3.4. Layered Design and Residual Connections
Each layer in the transformer architecture consists of residual connections around its sub-components (e.g., self-attention and FFN). By preserving the original input through residual connections, transformers ensure that gradients can flow directly through the network, alleviating the vanishing gradient problem commonly encountered in deep neural networks.
Also, residual connections contribute to smoother optimization during training, enabling transformers to converge faster and achieve better performance. This efficiency is crucial given the computational demands of training large-scale transformer models.
4. Benefits of Residual Connections in Transformers
Residual connections offer several critical advantages that enhance the effectiveness of various machine-learning applications. These benefits underscore the importance of residual connections in optimizing model performance and facilitating the training of deep neural networks.
4.1. Improved Gradient Flow and Training Speed
One of the primary advantages of residual connections in transformers is their role in enhancing gradient flow throughout the network. By providing shortcut connections that skip layers or blocks of computations, residual connections mitigate the issue of vanishing gradients. This ensures that gradients can propagate more effectively during backpropagation, leading to faster convergence during training.
4.2. Deeper Architectures and Long-Ranged Dependencies
Residual connections enable the construction of deeper transformer architectures without suffering from the degradation in performance. Deeper networks are essential for capturing complex relationships and dependencies within sequential data, such as long-range dependencies in language modeling or understanding intricate patterns in image generation tasks.
This iterative refinement process, facilitated by residual connections, enables transformers to effectively model contextual relationships and dependencies across extensive sequences. Therefore we can surpass several limitations of traditional sequential models like recurrent neural networks.
4.3. Robustness and Regularization
Residual connections contribute to the robustness and regularization of transformer models. By mitigating the risk of overfitting and enhancing the generalization ability of the network, residual connections help transformers maintain high performance across diverse datasets and tasks. The inclusion of residual connections alongside other regularization techniques, such as dropout and layer normalization, further improves the stability and reliability of models.
4.4. Performance Gains
Generally, the models that take advantage of residual connections outperform their counterparts in tasks such as language translation and sentiment analysis or image generation and reinforcement learning. These performance gains highlight the critical role of residual connections in machine learning and artificial intelligence research.
5. Case Studies and Applications
The usage of residual connections has significantly enhanced the performance and versatility of transformer-based models across various domains and applications.
BERT changed natural language understanding by pre-training bidirectional transformers on large text datasets. Residual connections helped in optimizing BERT’s architecture, facilitating efficient training, and enabling the model to capture complex patterns.
Moreover, T5 extends the transformer architecture to unify different NLP tasks under a single text-to-text framework. Additionally, residual connections in T5 enhance model flexibility and performance across tasks. These tasks include translation, summarization, and question-answering.
Furthermore, residual connections have found applications in diverse domains such as computer vision. In this field, transformer-based architectures like Vision Transformers (ViTs) utilize residual connections. These connections improve feature extraction and classification performance on image data.
6. Conclusion
In summary, residual connections represent an important component of transformer architectures, offering significant benefits that contribute to their success and widespread adoption in machine learning.
In this article, we delved into residual connections, talked about its purpose, analyzed its mathematical approach, and discussed the benefits it offers in several deep learning architectures.