1. 简介
在本篇文章中,我们将深入探讨受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)。它是一种基于无监督学习的生成式随机模型,主要用于学习数据的概率分布。我们将重点讲解其结构原理、训练过程(Contrastive Divergence,对比散度)、优缺点以及常见应用场景。
如果你是经验丰富的开发者或AI工程师,本文将帮助你快速掌握RBM的核心机制,同时避免陷入基础概念的重复解释。
2. 什么是玻尔兹曼机?
2.1 玻尔兹曼机(Boltzmann Machine)
玻尔兹曼机(Boltzmann Machine, BM)由 Geoffrey Hinton 和 Terry Sejnowski 于 1985 年提出。它是一种生成式概率图模型,能够通过无监督学习构建数据的概率分布,并用于采样和生成新数据。
BM 的结构是全连接的无向图,节点之间可以相互连接,这使得其计算复杂度较高。
2.2 受限玻尔兹曼机(Restricted Boltzmann Machine)
受限玻尔兹曼机(RBM)是 BM 的一种简化变体,由 Hinton 和 Sejnowski 于 1986 年提出。RBM 的结构被限制为二分图,即只允许可见层(visible layer)和隐藏层(hidden layer)之间的连接,隐藏层内部和可见层内部没有连接。
✅ 这种限制大幅降低了计算复杂度,使得 RBM 更容易训练和收敛。
2.3 BM 与 RBM 的主要区别
| 特性 | 玻尔兹曼机(BM) | 受限玻尔兹曼机(RBM) |
|---|---|---|
| 结构 | 全连接无向图 | 二分图(可见层 ↔ 隐藏层) |
| 计算复杂度 | 高 | 低 |
| 训练速度 | 慢 | 快 |
| 用途 | 学习复杂分布 | 特征提取、预训练 |
⚠️ BM 更强大,但 RBM 更实用,尤其是在深度学习中常用于预训练。
3. RBM 的结构
RBM 由两层神经元组成:
- 可见层(Visible Layer):用于接收输入数据。
- 隐藏层(Hidden Layer):用于提取输入数据的潜在特征。
这两层之间是全连接且对称的权重,但层内节点之间没有连接。
下图展示了 RBM 的结构:
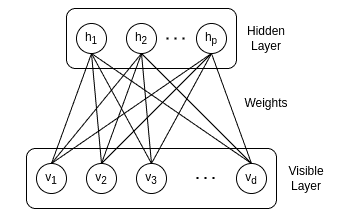
每一层的神经元通过权重连接,训练过程中不断调整这些权重,以逼近输入数据的概率分布。
4. RBM 的训练过程
RBM 的训练主要依赖于一种称为对比散度(Contrastive Divergence, CD)的算法。
4.1 对比散度(Contrastive Divergence)
CD 是一种基于梯度下降的优化算法,其核心思想是通过估计输入数据的对数似然梯度来更新模型参数。
简要流程如下:
- 输入样本 $ x $
- 前向传播计算隐藏层激活值 $ h $
- 反向传播重构输入 $ x' $
- 使用重构误差更新权重和偏置
✅ CD 的优势在于其计算效率高,适合大规模数据训练。
4.2 RBM 的学习阶段
学习阶段主要包括以下步骤:
- 初始化权重和偏置为小随机值
- 前向传播:计算隐藏层激活值
- 反向传播:重构输入
- 更新权重和偏置
- 重复上述过程直到收敛
训练过程中,学习率的设置非常关键。过大会导致模型无法收敛,过小则训练效率低下。
下图展示了 RBM 的训练过程:
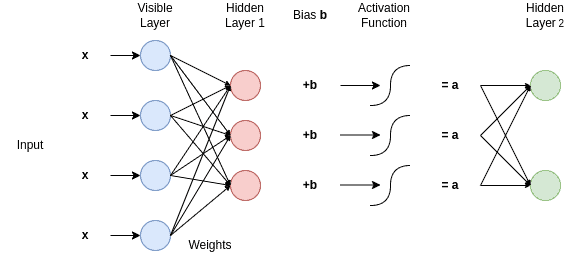
输入 $ x $ 与权重 $ w $ 相乘,加上偏置 $ b $,经过激活函数后传入下一层。
5. RBM 的优缺点
优点
- ✅ 支持无监督学习,无需标注数据
- ✅ 能有效提取高维数据的潜在特征
- ✅ 可用于降维、特征提取、独立成分分析等任务
- ✅ 可作为深度信念网络(DBN)的预训练模块
缺点
- ❌ 计算开销大,尤其在大规模数据集上
- ❌ 对数据质量敏感,缺失值或噪声会影响训练效果
- ❌ 参数设置复杂,调参难度大
- ❌ 有时无法完全捕捉数据的复杂结构,影响性能
⚠️ 如果你的项目对训练速度和模型稳定性有较高要求,RBM可能不是最佳选择。
6. 堆叠式 RBM 与深度信念网络(DBN)
多个 RBM 可以堆叠起来构建更复杂的神经网络结构,这种方式被称为堆叠式 RBM。每一层 RBM 单独训练后,其隐藏层输出作为下一层的输入。
✅ 这种结构构成了深度信念网络(Deep Belief Network, DBN)的基础。
DBN 是一种强大的生成模型,广泛应用于图像分类、自然语言处理、时间序列分析等领域。
7. RBM 的典型应用场景
RBM 在多个领域都有成功应用,包括但不限于:
| 应用场景 | 描述 |
|---|---|
| 推荐系统 | Netflix、Amazon 等平台使用 RBM 学习用户行为,提供个性化推荐 |
| 图像识别 | 用于特征提取和图像重建 |
| 异常检测 | 金融领域中用于识别欺诈交易 |
| 降维与特征学习 | 用于提取高维数据中的低维表示 |
| 生成建模 | 根据学习到的数据分布生成新样本 |
✅ RBM 的生成能力使其在推荐系统和异常检测中尤为突出。
8. 总结
RBM 是一种强大的生成式无监督学习模型,适用于高维数据的特征提取、降维和生成建模。其结构简单、训练效率相对较高,尤其适合用于深度学习的预训练阶段。
虽然 RBM 在某些方面已被更现代的模型(如自编码器、GAN)所取代,但在特定场景(如推荐系统)中仍具优势。
✅ 掌握 RBM 的原理和训练过程,有助于理解深度学习中许多重要思想的起源。
如果你正在构建一个需要特征提取或生成建模的系统,不妨尝试使用 RBM,或许会有意想不到的收获。